KAN結合Transformer,真有團隊搞出了解決擴展缺陷的KAT
Transformer 是現代深度學習的基石。傳統上,Transformer 依賴多層感知器 (MLP) 層來混合通道之間的信息。
前段時間,來自 MIT 等機構的研究者提出了一種非常有潛力的替代方法 ——KAN。該方法在準確性和可解釋性方面表現優于 MLP。而且,它能以非常少的參數量勝過以更大參數量運行的 MLP。
KAN的發布,引起了AI社區大量的關注與討論,同時也伴隨很大的爭議。
而此類研究,又有了新的進展。
最近,來自新加坡國立大學的研究者提出了 Kolmogorov–Arnold Transformer(KAT),用 Kolmogorov-Arnold Network(KAN)層取代 MLP 層,以增強模型的表達能力和性能。

- 論文標題:Kolmogorov–Arnold Transformer
- 論文地址:https://arxiv.org/pdf/2409.10594
- 項目地址:https://github.com/Adamdad/kat
KAN 原論文第一作者 Ziming Liu 也轉發點贊了這項新研究。

將 KAN 集成到 Transformer 中并不是一件容易的事,尤其是在擴展時。具體來說,該研究確定了三個關鍵挑戰:
(C1) 基函數。KAN 中使用的標準 B 樣條(B-spline)函數并未針對現代硬件上的并行計算進行優化,導致推理速度較慢。
(C2) 參數和計算效率低下。KAN 需要每個輸入輸出對都有特定的函數,這使得計算量非常大。
(C3) 權重初始化。由于具有可學習的激活函數,KAN 中的權重初始化特別具有挑戰性,這對于實現深度神經網絡的收斂至關重要。
為了克服上述挑戰,研究團隊提出了三個關鍵解決方案:
(S1) 有理基礎。該研究用有理函數替換 B 樣條函數,以提高與現代 GPU 的兼容性。通過在 CUDA 中實現這一點,該研究實現了更快的計算。
(S2) Group KAN。通過一組神經元共享激活權重,以在不影響性能的情況下減少計算負載。
(S3) Variance-preserving 初始化。該研究仔細初始化激活權重,以確保跨層保持激活方差。
結合解決方案 S1-S3,該研究提出了一種新的 KAN 變體,稱為 Group-Rational KAN (GR-KAN),以取代 Transformer 中的 MLP。
實驗結果表明:GR-KAN 計算效率高、易于實現,并且可以無縫集成到視覺 transformer(ViT)中,取代 MLP 層以實現卓越的性能。此外,該研究的設計允許 KAT 從 ViT 模型加載預訓練權重并繼續訓練以獲得更好的結果。
該研究在一系列視覺任務中實證驗證了 KAT,包括圖像識別、目標檢測和語義分割。結果表明,KAT 的性能優于傳統的基于 MLP 的 transformer,在計算量相當的情況下實現了增強的性能。
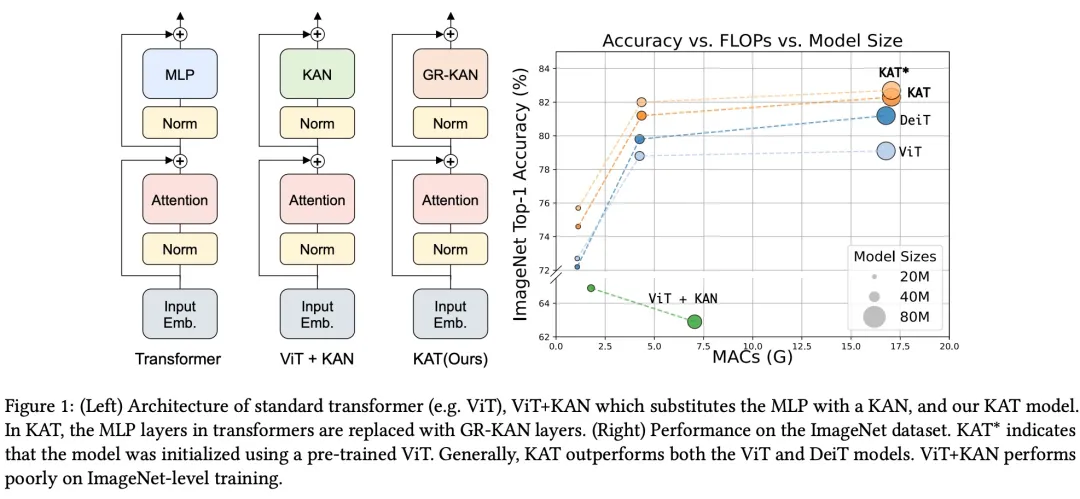
如圖 1 所示,KAT-B 在 ImageNet-1K 上實現了 82.3% 的準確率,超過相同大小的 ViT 模型 3.1%。當使用 ViT 的預訓練權重進行初始化時,準確率進一步提高到 82.7%。
不過,也有網友質疑道:「自從有論文比較了具有相同參數大小的 MLP 模型和 KAN 模型的性能后,我就對 KAN 持懷疑態度。可解釋性似乎是唯一得到巨大提升的東西。」

對此,論文作者回應道:「的確,原始 KAN 在可解釋性上做得很好,但不保證性能和效率。我們所做的就是修復這些 bug 并進行擴展。」

還有網友表示,這篇論文和其他人的想法一樣,就是用 KAN 取代了 MLP,并質疑為什么作者在嘗試一些已經很成熟和類似的東西,難道是在炒作 KAN?對此, 論文作者 Xingyi Yang 解釋道,事實確實如此,但不是炒作,根據實驗,簡單地進行這種替換是行不通的,他們在努力將這個簡單的想法變成可能的事情。

Kolmogorov–Arnold Transformer (KAT)
作者表示,標準的 KAN 面臨三大挑戰,限制了其在大型深度神經網絡中的應用。
它們分別是基函數的選擇、冗余參數及其計算、初始化問題。這些設計選擇使得原始版本的 KAN 是資源密集型的,難以應用于大規模模型。
本文對這些缺陷設計加以改進,以更好地適應現代 Transformer,從而允許用 KAN 替換 MLP 層。
KAT 整體架構
正如其名稱所暗示的那樣,KAT 用 KAN 層取代了視覺 transformer 中的 MLP 層。
具體來說,對于 2D 圖像 ,作者首先將其平面化成 1D 序列,在此基礎上應用 patch 嵌入和位置編碼,然后通過一系列 KAT 層進行傳遞。對于
,作者首先將其平面化成 1D 序列,在此基礎上應用 patch 嵌入和位置編碼,然后通過一系列 KAT 層進行傳遞。對于 層,可以執行如下操作:
層,可以執行如下操作:

其中, 表示
表示 層的輸出特征序列。
層的輸出特征序列。
如圖所示,作者用兩層 KAN 替換兩層 MLP,同時保持注意力層不變。然而,簡單的替換不足以在大模型中實現可擴展性。
最重要的是,在這里,作者引入了一種特殊的 Group-Rational KAN。作者使用有理函數作為 KAN 的基函數,并在一組邊之間共享參數。此外,作者還指定了權重初始化方案以確保穩定的訓練。這些改進使得 KAT 更具可擴展性并提高了性能。
有理基函數
作者使用有理函數作為 KAN 層的基函數,而不是 B 樣條函數,即每個邊上的函數 ?? (??) 參數化為 ??、?? 階多項式 ?? (??)、??(??) 上的有理數。

標準形式轉化為:

至于為什么采用有理函數,作者表示從效率角度來看,多項式求值涉及簡單的運算,非常適合并行計算。這使得有理函數對于大規模模型具有計算效率。
其次,從理論角度來看,有理函數可以比多項式更高效、更準確地逼近更廣泛的函數。由于 B 樣條本質上是局部多項式的和,因此有理函數在復雜行為建模方面比 B 樣條具有理論優勢。
第三,從實踐角度來看,有理激活函數已經成功用作神經網絡中的激活函數。

Group KAN
作者表示,他們不必為每個輸入 - 輸出對學習一個獨特的基函數,而是可以在一組邊內共享它們的參數。這減少了參數數量和計算量。這種參數共享和分組計算的方式一直是神經網絡設計中的關鍵技術
圖 2 說明了原始 KAN、Group KAN 和標準 MLP 之間的區別。Group KAN 通過在一組邊之間共享這些函數來減少參數數量。

除了節省參數數量外,這種分組還減少了計算需求。不同模型間參數數量和計算量的對比如下所示:

Variance-preserving 初始化
作者旨在初始化 Group-Rational KAN 中的 ??_??、??_?? 和 ?? 的值,其核心是防止整個層中的激活參數呈量級增長或減少,從而保持穩定性。

實驗
實驗中,作者修改了原始 ViT 架構,用 GR-KAN 層替換其 MLP 層。

圖像識別
實驗結果表明,KAT 模型在 IN-1k( ImageNet-1K ) 數據集上的表現始終優于其他模型。首先,GR-KAN 在 Transformer 架構中的表現優于傳統的基于 MLP 的混合器的性能。例如,KAT-S 模型的準確率達到 81.2%,比 DeiT-S 模型高出 2.4%。

其次,原始 KAN 層面臨可擴展性問題。ViT-T/S + KAN 的準確率僅為 63% 左右,即使計算成本高得多。ViT-L + KAN 無法收斂,導致 NAN 錯誤。本文解決了這些擴展挑戰,從而使 KAT 模型能夠成功擴展。
目標檢測和實例分割
表 6 比較了不同骨干模型的性能。KAT 的表現始終優于其他模型,尤其是在物體檢測方面,與 ViTDet 相比,其在 S 規模的模型上實現了 3.0 AP^box 增益,在 L 規模的模型上實現了 1.4 AP^box 增益。這種改進在較小的模型中最為明顯,計算成本僅增加了 1 GFLOP。這表明 KAT 以最小的開銷提供了更好的準確率。

語義分割
表 7 總結了分割結果。總體而言,KAT 比基于 ViT 的普通架構表現出了競爭優勢,比 DeiT-S 提高了 2.4%,比 DeiT-B 提高了 0.2%。這種性能提升伴隨著計算成本的輕微增加,反映在更高的 FLOP 上。與檢測結果類似,KAT 在較小的模型中顯示出更顯著的收益。然而,與具有分層架構的模型(如 ConvNeXt)相比,它仍然有所不足,這些模型受益于更高效的架構設計。

作者介紹
Xingyi Yang 現在是新加坡國立大學(NUS)三年級博士生,導師是 Xinchao Wang 教授,這篇論文就是師徒兩人合作完成的。
Xingyi Yang 于 2021 年在加州大學圣地亞哥分校獲得碩士學位,并于 2019 年在東南大學獲得計算機科學學士學位。
Xinchao Wang 目前是新加坡國立大學電氣與計算機工程系(ECE)的助理教授,研究興趣包括人工智能、計算機視覺、機器學習、醫學圖像分析和多媒體。