終于把機器學習中的評估指標搞懂了
今天給大家分享在機器學習中最廣泛使用的十大評估指標。評估指標是用于衡量機器學習模型的性能,幫助我們判斷模型在解決特定任務上的效果。

不同的評估指標適用于不同類型的任務(分類、回歸),選擇合適的指標能夠有效反映模型的優劣。
回歸指標
1.MSE
MSE(均方誤差) 是最常用的回歸評估指標,它衡量了模型預測值與實際值之間的平方差的平均值。
計算公式為:
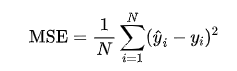
優缺點:
- 優點:對大誤差有更大的懲罰,適合對誤差敏感的場景。
- 缺點:對離群值非常敏感,可能導致模型對極端值過度擬合。
2.RMSE
均方根誤差 (RMSE) 是 MSE 的平方根。它將誤差量級與原始數據保持一致,便于解釋。RMSE 越小,模型的預測性能越好。
計算公式為:
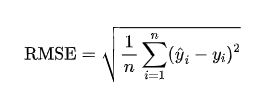
其中 是實際值, 是預測值。RMSE 的單位與原數據相同,因此容易理解。
3.R 平方
值表示模型解釋數據方差的比例,范圍是 0 到 1,越接近 1 表示模型對數據的擬合程度越好。
計算公式為:
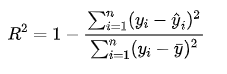
其中 是實際值的平均值。
4.調整后的 R 平方
調整后的 值考慮了模型中使用的特征數,能夠更好地評估復雜模型的表現。
它通過對特征數量進行懲罰,避免過擬合。
計算公式為:
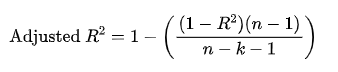
其中 n 是樣本數量,k 是特征數。
調整后的 會隨著無意義變量的增加而下降。
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X = np.random.rand(100, 1)
y = 3 * X.squeeze() + np.random.randn(100) * 0.5
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 計算 MSE
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse}")
# 計算 RMSE
rmse = np.sqrt(mse)
print(f"RMSE: {rmse}")
# 計算 R2 值
r2 = r2_score(y_test, y_pred)
print(f"R2: {r2}")
# 計算調整后的 R2 值
n = len(y_test)
p = X_test.shape[1]
adjusted_r2 = 1 - (1 - r2) * (n - 1) / (n - p - 1)
print(f"Adjusted R2: {adjusted_r2}")分類指標
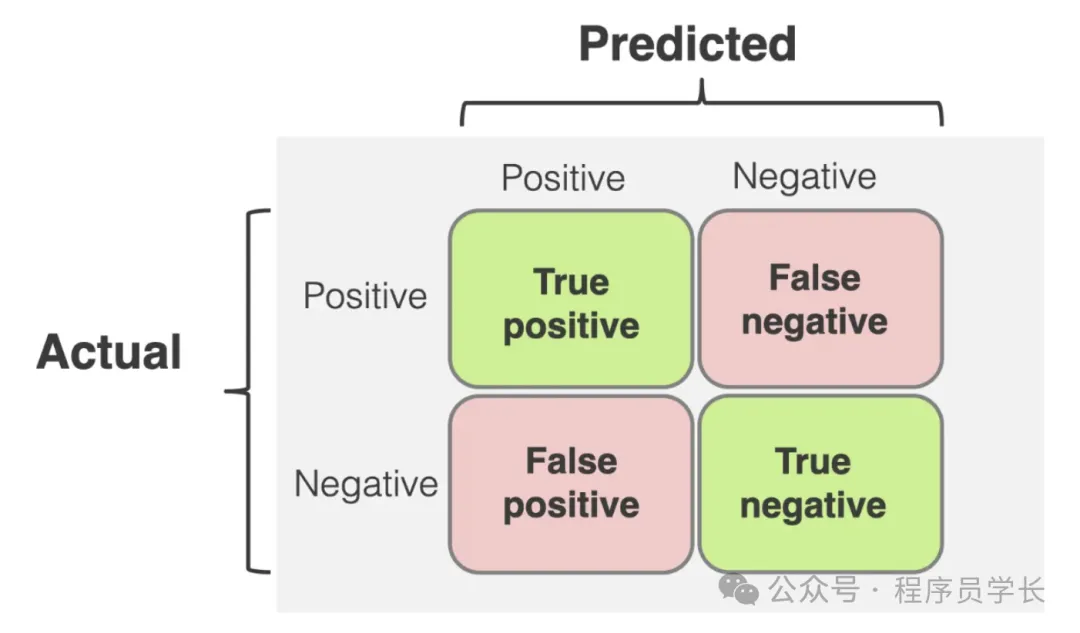
1.混淆矩陣
混淆矩陣是用于分類問題的指標,展示了模型分類結果的詳細情況。
它通常以 2x2 矩陣形式表示,包含以下部分:
- TP (True Positives),正類被正確預測為正類的數量。
- TN (True Negatives),負類被正確預測為負類的數量。
- FP (False Positives),負類被錯誤預測為正類的數量(誤報)。
- FN (False Negatives),正類被錯誤預測為負類的數量(漏報)。
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
iris = datasets.load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target,
random_state = 1)
clf = LogisticRegression(solver = 'liblinear')
# fit the training data
clf.fit(x_train, y_train)
# Do prediction on training data
y_train_pred = clf.predict(x_train)
# Do prediction on testing data
y_test_pred = clf.predict(x_test)
# find the confusion matrix for train data
confusion_matrix(y_train, y_train_pred)
# find the confusion matrix for test data
confusion_matrix(y_test, y_test_pred)
# get the full classification report for training data
print(classification_report(y_train, y_train_pred))
# get the full classification report for testing data
print(classification_report(y_test, y_test_pred))2.準確性
準確性衡量模型預測正確的樣本占總樣本的比例。
適用于樣本均衡的分類問題。
計算公式為:
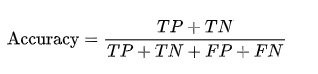
然而,在數據不平衡時,準確性可能不是一個好的評估指標。
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
print("Score :", accuracy_score(y_true, y_pred))3.精確度
精確度也稱為查準率,用于衡量模型預測的正類中有多少是真正的正類。
計算公式為:
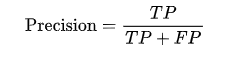
精確度在我們關心誤報(false positive)時尤為重要。
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
from sklearn.metrics import precision_score
precision_score(y_true, y_pred)4.召回率
召回率也稱為查全率或靈敏度,用于衡量實際正類中有多少被正確預測為正類。
計算公式為:
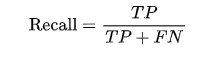
召回率在關心漏報(false negative)時非常重要。
5.F1 分數
F1 分數是精確度和召回率的調和平均數,綜合考慮了模型的查準率和查全率。
計算公式為:
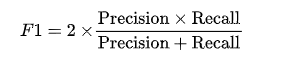
F1 分數適合處理不平衡數據集的分類任務。
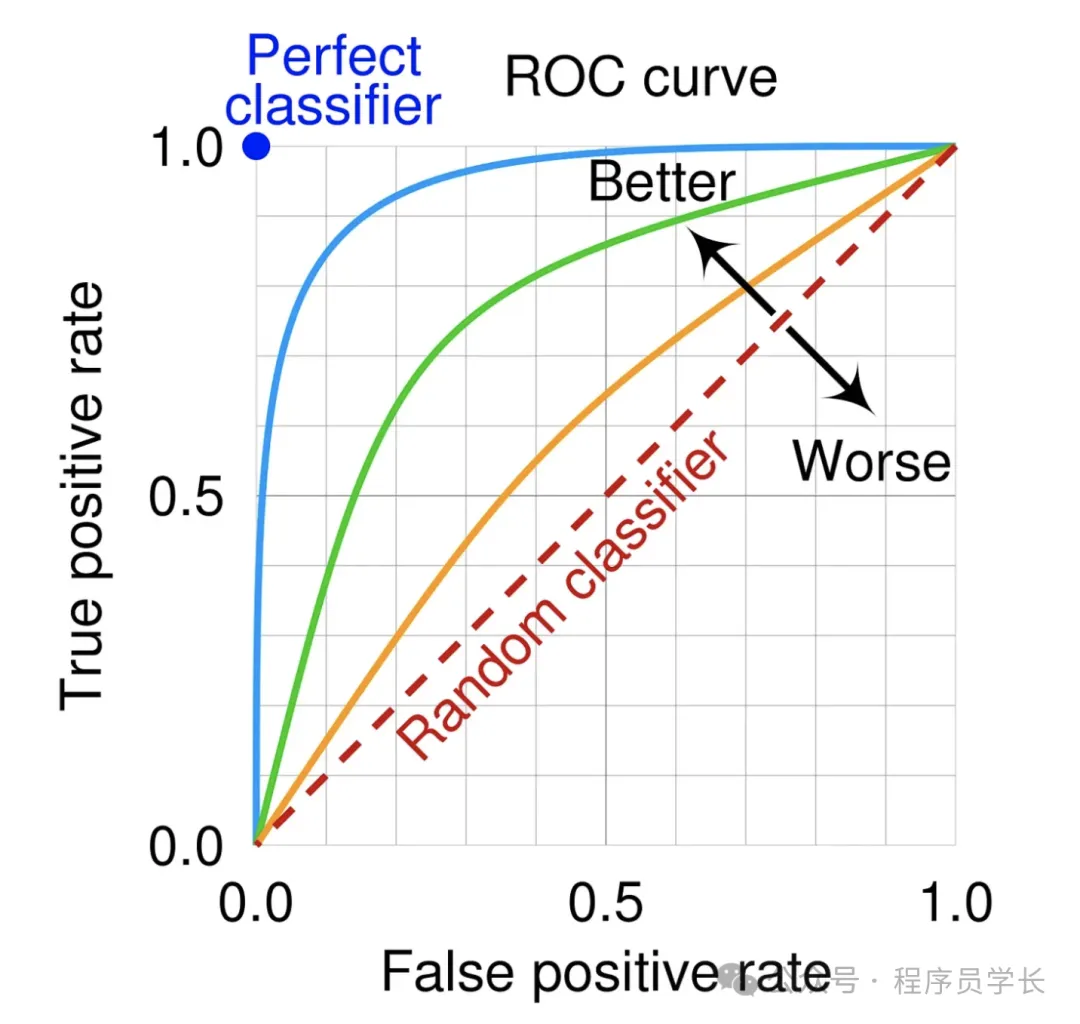
6.ROC 曲線和 AUC
ROC 曲線是一種常用于評估分類模型性能的圖形工具,特別適合不平衡數據集。
它展示了不同閾值下分類模型的性能表現。
ROC 曲線的兩個關鍵要素是:
- 真正率 (True Positive Rate, TPR)
在所有正類樣本中,被模型正確分類為正類的比例。
計算公式為:
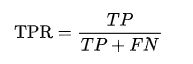
其中 TP 是真正例數,FN 是假負例數。
- 假正率 (False Positive Rate, FPR)
在所有負類樣本中,被模型錯誤分類為正類的比例。
計算公式為:

其中 FP 是假正例數,TN 是真負例數。
ROC 曲線的橫軸是假正率 (FPR),縱軸是真正率 (TPR)。隨著分類閾值的調整,FPR 和 TPR 都會變化。通過繪制不同閾值下的 FPR 和 TPR 的點,并將這些點連成曲線,就得到了 ROC 曲線。
AUC 是 ROC 曲線下的面積,取值范圍在 0 到 1 之間。它用一個數值量化了模型的整體表現。
AUC 表示了模型在不同閾值下的平均性能,是模型區分正負樣本能力的衡量指標。
AUC 值解釋
- AUC = 1,模型完美地分類了所有正負樣本,表現極佳。
- AUC = 0.5,模型的分類能力與隨機猜測相當,沒有預測能力。
- AUC < 0.5,模型的表現比隨機猜測還要差,意味著模型可能將類別完全反向分類。