譯者 | 朱先忠
審校 | 重樓
本文將通過探討微軟開源Florence-2模型的零樣本功能來全面了解其在字幕識別、目標(biāo)檢測、分割和OCR等領(lǐng)域的應(yīng)用。

簡介
近年來,計算機視覺領(lǐng)域見證了基礎(chǔ)模型的興起,這些模型可以在不需要訓(xùn)練自定義模型的情況下進行圖像注釋。我們已經(jīng)看到了用于分類的CLIP模型(參考文獻2)、用于對象檢測的Grounding DINO(參考文獻3)和用于分割的SAM(參考文獻4)等模型,每種模型在其各自領(lǐng)域都表現(xiàn)出色。但是,我們是否能夠開發(fā)一個能夠同時處理所有這些任務(wù)的單一模型呢?
在本教程中,我們將要介紹Florence-2模型(參考文獻1)——一種新穎的開源視覺語言模型(VLM),旨在處理各種視覺和多模型任務(wù),包括字幕識別、對象檢測、分割和OCR等內(nèi)容。
通過Colab筆記本文件形式,我們將開始探索Florence-2的零樣本功能,用來注釋一部舊相機的圖像。
Florence-2模型
背景
Florence-2模型于2024年6月由微軟發(fā)布。它被設(shè)計為在單個模型中執(zhí)行多個視覺任務(wù)。這是一個開源模型,可以在麻省理工學(xué)院許可的Hugging Face網(wǎng)站上使用。
盡管Florence-2模型的尺寸相對較小,僅具有0.23B和0.77B個參數(shù)的版本,但它實現(xiàn)了最先進的性能。其緊湊的尺寸使其能夠在計算資源有限的設(shè)備上高效部署,同時確保快速的推理速度。
該模型在一個名為FLD-5B的龐大、高質(zhì)量的數(shù)據(jù)集上進行了預(yù)訓(xùn)練,該數(shù)據(jù)集由1.26億張圖像上的5.4B個注釋組成。這使得Florence-2模型在許多任務(wù)中都能在零樣本情況下表現(xiàn)出色,而無需額外訓(xùn)練。
Florence-2模型的原始開源權(quán)重支持以下任務(wù):
任務(wù)類型 | 任務(wù)提示文本 | 任務(wù)描述 | 輸入信息形式 | 輸出 |
圖像字幕 | <CAPTION> | 為圖像生成基本標(biāo)題 | 圖像 | 文本 |
<DETAILED_CAPTION> | 為圖像生成詳細的標(biāo)題 | 圖像 | 文本 | |
<MORE_DETAILED_CAPTION> | 為圖像生成非常詳細的標(biāo)題 | 圖像 | 文本 | |
<REGION_TO_CATEGORY> | 為指定的邊界框生成類別標(biāo)簽 | 圖像,邊界盒 | 文本 | |
<REGION_TO_DESCRIPTION> | 為指定的邊界框生成描述 | 圖像,邊界盒 | 文本 | |
對象檢測 | <OD> | 檢測對象并生成帶有標(biāo)簽的邊界框 | 圖像 | 邊界盒,文本 |
<DENSE_REGION_CAPTION> | 檢測對象并生成帶有標(biāo)題的邊界框 | 圖像 | 邊界盒,文本 | |
<CAPTION_TO_PHRASE_GROUNDING> | 用邊界框檢測并固定字幕中的短語 | 圖像,文本 | 邊界盒,文本 | |
<OPEN_VOCABULARY_DETECTION> | 根據(jù)提供的文本(開放詞匯表)檢測對象 | 圖像,文本 | 邊界盒,文本 | |
<REGION_PROPOSAL> | 用邊界框提出感興趣的區(qū)域 | 圖像 | 邊界盒 | |
分割 | <REFERRING_EXPRESSION_SEGMENTATION> | 基于文本描述生成分割多邊形 | 圖像,文本 | 多邊形 |
<REGION_TO_SEGMENTATION> | 為給定的邊界框生成分割多邊形 | 圖像,邊界盒 | 多邊形 | |
OCR | <OCR> | 從整個圖像中提取文本 | 圖像 | 文本 |
<OCR_WITH_REGION> | 提取帶有位置的文本(邊界框或四邊形框) | 圖像 | 文本,邊界盒 |
通過微調(diào)模型可以添加其他不受支持的任務(wù)。
任務(wù)格式
受大型語言模型的啟發(fā),F(xiàn)lorence-2被設(shè)計為一種序列到序列的模型。它將圖像和文本指令作為輸入,并輸出文本結(jié)果。輸入或輸出文本可以表示純文本或圖像中的區(qū)域。區(qū)域格式因任務(wù)而異:
- 邊界框:“<X1><Y1><X2><Y2>”用于對象檢測任務(wù)。這些標(biāo)記表示長方體左上角和右下角的坐標(biāo)。
- 四邊框:“<X1><Y1><X2><Y2><X3><Y3><X4><Y4>”用于文本檢測,使用包圍文本的四個角的坐標(biāo)。
- 多邊形:“<X1><Y1><Xn><Yn>'用于分割任務(wù),其中坐標(biāo)按順時針順序表示多邊形的頂點。
架構(gòu)
Florence-2模型是使用標(biāo)準(zhǔn)“編碼器-解碼器”轉(zhuǎn)換器架構(gòu)構(gòu)建的。以下是該過程的工作原理:
- 輸入圖像由DaViT視覺編碼器嵌入(參考文獻5)。
- 文本提示使用BART(參考文獻6)嵌入,利用擴展的標(biāo)記器和單詞嵌入層。
- 視覺和文本嵌入都是連接在一起的。
- 這些級聯(lián)的嵌入由基于轉(zhuǎn)換器的多模型編碼器-解碼器處理,以生成響應(yīng)。
- 在訓(xùn)練過程中,該模型最小化交叉熵損失,類似于標(biāo)準(zhǔn)語言模型。
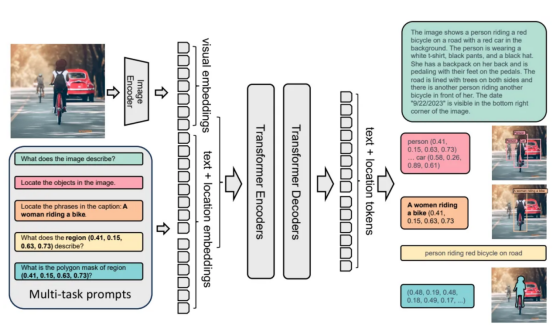
Florence-2模型架構(gòu)圖(來源鏈接:https://arxiv.org/abs/2311.06242)
代碼實現(xiàn)
加載Florence-2模型和一個樣本圖像
安裝并導(dǎo)入必要的庫后,我們首先加載Florence-2模型、處理器和相機的輸入圖像:
#加載模型:
model_id = ‘microsoft/Florence-2-large’
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, torch_dtype='auto').eval().cuda()
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
#加載圖像:
image = Image.open(img_path)輔助函數(shù)
在本教程中,我們將使用幾個輔助函數(shù)。最重要的是run_example核心函數(shù),它從Florence-2模型生成響應(yīng)。
run_example函數(shù)將任務(wù)提示與任何其他文本輸入(如果提供的話)組合成一個提示。借助處理器,它生成文本和圖像嵌入,作為模型的輸入。最神奇的事情發(fā)生在model.generate步驟中,在該步驟中生成模型的響應(yīng)。以下是一些關(guān)鍵參數(shù)的詳細解釋:
- max_new_tokens=1024:設(shè)置輸出的最大長度,允許輸出詳細的響應(yīng)。
- do_sample=False:確保產(chǎn)生確定性的響應(yīng)。
- num_beams=3:在每個步驟中使用前3個最可能的標(biāo)記進行波束搜索,探索多個潛在序列以找到最佳的整體輸出。
- early_stoping=False:確保波束搜索繼續(xù)進行,直到所有波束達到最大長度或生成序列結(jié)束標(biāo)記。
最后,使用processor.batch_decode和processor.post_process_generation對模型的輸出進行解碼和后處理,以便產(chǎn)生最終的文本響應(yīng)。該響應(yīng)由run_example函數(shù)返回。
def run_example(image, task_prompt, text_input=''):
prompt = task_prompt + text_input
inputs = processor(text=prompt, images=image, return_tensors=”pt”).to(‘cuda’, torch.float16)
generated_ids = model.generate(
input_ids=inputs[“input_ids”].cuda(),
pixel_values=inputs[“pixel_values”].cuda(),
max_new_tokens=1024,
do_sample=False,
num_beams=3,
early_stopping=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=(image.width, image.height)
)
return parsed_answer此外,我們利用輔助函數(shù)來可視化結(jié)果(draw_box、draw_ocr_bboxes和draw_polygon),并處理邊界框格式(convert_box_to_florence-2和convert_florence-2_to_bbox)之間的轉(zhuǎn)換。所有這些內(nèi)容,有興趣的讀者可以在隨附的Colab筆記本文件中進一步探索。
其他方面的任務(wù)
Florence-2模型可以執(zhí)行各種視覺任務(wù)。讓我們從圖像字幕識別開始探索它的一些功能。
1.為生成相關(guān)任務(wù)添加字幕
(1)生成字幕
Florence-2模型可以使用“<CAPTION>”、“<DETAILED_CAPTION>”或“<MORE_DETAILED_CACTION>”任務(wù)提示生成各種細節(jié)級別的圖像字幕。
print (run_example(image, task_prompt='<CAPTION>'))
# 輸出: 'A black camera sitting on top of a wooden table.'
print (run_example(image, task_prompt='<DETAILED_CAPTION>'))
# 輸出: 'The image shows a black Kodak V35 35mm film camera sitting on top of a wooden table with a blurred background.'
print (run_example(image, task_prompt='<MORE_DETAILED_CAPTION>'))
# 輸出: 'The image is a close-up of a Kodak VR35 digital camera. The camera is black in color and has the Kodak logo on the top left corner. The body of the camera is made of wood and has a textured grip for easy handling. The lens is in the center of the body and is surrounded by a gold-colored ring. On the top right corner, there is a small LCD screen and a flash. The background is blurred, but it appears to be a wooded area with trees and greenery.'該模型準(zhǔn)確地描述了圖像及其周圍環(huán)境。它甚至可以識別相機的品牌和模型,展示其OCR功能。然而,在“<MORE_DETALED_CAPTION>”任務(wù)中,存在輕微的不一致性,這是零樣本模型所預(yù)期的。
(2)為給定的邊界框生成字幕
Florence-2模型可以為圖像中由邊界框定義的特定區(qū)域生成字幕。為此,它將邊界框位置作為輸入。你可以使用“<REGION_TO_category>”提取類別,或使用“<REGION_TO_DESCRIPTI>”提取描述。
為了你的使用方便,我在Colab筆記本中添加了一個小部件,使你能夠在圖像上繪制一個邊界框,并編寫代碼將其轉(zhuǎn)換為Florence-2格式。
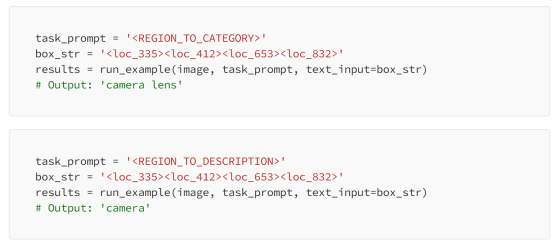
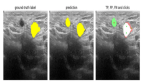
在這種情況下,“<REGION_TO_CATEGORY>”標(biāo)識了鏡片,而“<REGION _TO_DESCRIPTI>”則不太具體。但是,此性能可能因不同的圖像而有所不同。
2.目標(biāo)檢測相關(guān)任務(wù)
(1)為對象生成邊界框和文本
Florence-2模型可以識別圖像中密集的區(qū)域,并提供它們的邊界框坐標(biāo)和相關(guān)的標(biāo)簽或字幕。要提取帶有標(biāo)簽的邊界框,請使用“<OD>”任務(wù)提示:
results = run_example(image, task_prompt='<OD>')
draw_bbox(image, results['<OD>'])要提取帶有文本內(nèi)容的邊界框,請使用“<DENSE_REGION_CAPTION>”任務(wù)提示:
task_prompt results = run_example(image, task_prompt= '<DENSE_REGION_CAPTION>')
draw_bbox(image, results['<DENSE_REGION_CAPTION>'])
左側(cè)的圖像顯示了“<OD>”任務(wù)提示的結(jié)果,而右側(cè)的圖像顯示的是“<DENSE_REGION_CAPTION>”。
(2)基于文本的對象檢測
Florence-2模型還可以執(zhí)行基于文本的對象檢測。通過提供特定的對象名稱或描述作為輸入,F(xiàn)lorence-2模型可以檢測指定對象周圍的邊界框。
task_prompt = '<CAPTION_TO_PHRASE_GROUNDING>'
results = run_example(image,task_prompt, text_input=”lens. camera. table. logo. flash.”)
draw_bbox(image, results['<CAPTION_TO_PHRASE_GROUNDING>'])
CAPION_TO_PHRASE_ROUNDING任務(wù),文本輸入:“鏡頭、相機、桌子、徽標(biāo)、閃光燈。”
3.分割相關(guān)任務(wù)
Florence-2還可以生成基于文本(“<REFERRING_EXPRESSION_segmentation>”)或邊界框(“<REGION_TO_segmentation>”)的分割多邊形:
results = run_example(image, task_prompt='<REFERRING_EXPRESSION_SEGMENTATION>', text_input=”camera”)
draw_polygons(image, results[task_prompt])
results = run_example(image, task_prompt='<REGION_TO_SEGMENTATION>', text_input="<loc_345><loc_417><loc_648><loc_845>")
draw_polygons(output_image, results['<REGION_TO_SEGMENTATION>'])
左側(cè)的圖像顯示了以“camera”文本作為輸入的REFERRING_EXPRESSION_SEGMENTATION任務(wù)的結(jié)果。右側(cè)的圖像演示了REGION_TO_SEGMENTION任務(wù),鏡頭周圍有一個邊界框作為輸入。
4.OCR相關(guān)任務(wù)
Florence-2模型還展示出強大的OCR功能。它可以使用“<OCR>”任務(wù)提示從圖像中提取文本,并使用“<OCR_with_REGON>”提取文本及其位置。
results = run_example(image,task_prompt)
draw_ocr_bboxes(image, results['<OCR_WITH_REGION>'])
結(jié)束語
總之,F(xiàn)lorence-2模型是一個通用的視覺語言模型(VLM),它能夠在單個模型中處理多個視覺任務(wù)。其零樣本功能在圖像字幕、對象檢測、分割和OCR等各種任務(wù)中都給人留下深刻印象。雖然Florence-2模型表現(xiàn)良好,但是額外的微調(diào)可以進一步使模型適應(yīng)新任務(wù),或提高其在獨特的自定義數(shù)據(jù)集上的性能。
參考文獻
本文在Colab Notebook中的源代碼鏈接地址:https://gist.github.com/Lihi-Gur-Arie/427ecce6a5c7f279d06f3910941e0145
《Florence-2:推進各種視覺任務(wù)的統(tǒng)一表示》。原文地址:https://arxiv.org/pdf/2311.06242
《CLIP:從自然語言監(jiān)督中學(xué)習(xí)可轉(zhuǎn)移的視覺模型》。原文地址:https://arxiv.org/pdf/2103.00020v1
《Grounding DINO:將DINO與開放式目標(biāo)檢測的預(yù)訓(xùn)練相結(jié)合》。https://arxiv.org/abs/2303.05499
《SAM2:分割圖像和視頻中的任何內(nèi)容》。原文地址:https://arxiv.org/pdf/2408.00714
《DaViT:雙注意力視覺轉(zhuǎn)換器》。地址:https://arxiv.org/abs/2204.03645
《BART:用于自然語言生成、翻譯和理解的去噪序列到序列預(yù)訓(xùn)練》。地址:https://arxiv.org/pdf/1910.13461
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標(biāo)題:Florence-2: Advancing Multiple Vision Tasks with a Single VLM Model,作者:Lihi Gur Arie