清華團(tuán)隊(duì)革新MoE架構(gòu)!像搭積木一樣構(gòu)建大模型,提出新型類腦稀疏模塊化架構(gòu)
探索更高效的模型架構(gòu), MoE是最具代表性的方向之一。
MoE架構(gòu)的主要優(yōu)勢(shì)是利用稀疏激活的性質(zhì),將大模型拆解成若干功能模塊,每次計(jì)算僅激活其中一小部分,而保持其余模塊不被使用,從而大大降低了模型的計(jì)算與學(xué)習(xí)成本,能夠在同等計(jì)算量的情況下產(chǎn)生性能優(yōu)勢(shì)。
然而,此前像MoE等利用稀疏激活性質(zhì)的研究工作,都認(rèn)為大模型需要在預(yù)訓(xùn)練階段就額外引入模塊化結(jié)構(gòu)約束。
如今,來自清華的一項(xiàng)最新研究打破了以上思維定式,并將MoE架構(gòu)進(jìn)行了革新。
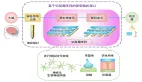
具體而言,研究人員受啟發(fā)于人腦高效的稀疏模塊化架構(gòu),在論文《Configurable Foundation Models: Building LLMs from a Modular Perspective》中提出了一種類腦高效稀疏模塊化架構(gòu):Configurable Foundation Model。
該架構(gòu)將大模型的模塊拆分為預(yù)訓(xùn)練階段產(chǎn)生的涌現(xiàn)模塊(Emergent Brick)與后訓(xùn)練階段產(chǎn)生的定制模塊(Customized Brick),然后通過模塊的檢索、組合、更新與增長(zhǎng)可以高效地實(shí)現(xiàn)復(fù)雜功能配置與組合,因此,將這一類模塊化模型架構(gòu)命名為“Configurable Foundation Model”——可配置的基礎(chǔ)模型。
從此,訓(xùn)練大模型無需在預(yù)訓(xùn)練階段就像MoE架構(gòu)一樣引入模塊化結(jié)構(gòu)約束,而是可以在預(yù)訓(xùn)練階段產(chǎn)生涌現(xiàn)模塊之后,像搭積木一樣來構(gòu)建大模型!
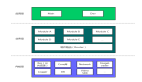
如下圖所示,大模型看做是一個(gè)大的積木,將其按照功能拆分成一個(gè)一個(gè)小模塊之后,給定一個(gè)指令時(shí),我們僅需選用部分相關(guān)的模塊組成子模型即可完成任務(wù)。
 圖片
圖片
該研究揭示了「模塊化」是大模型本身自帶的性質(zhì),所有 Transformer-based 大模型的預(yù)訓(xùn)練和后訓(xùn)練等工作都可以通過模塊化的視角進(jìn)行解構(gòu),其中MoE、Delta tuning只是Configurable Foundation Model包含的一種路線。
Configurable Foundation Model架構(gòu)具有高效性、可復(fù)用性、可溯源性、可擴(kuò)展性,并且更適合分布式計(jì)算,能夠更好地契合未來大模型在端側(cè)部署、在廣泛的場(chǎng)景中使用、在新環(huán)境中進(jìn)化的未來趨勢(shì)。
 圖片
圖片
論文鏈接:https://arxiv.org/pdf/2409.02877
論文單位:清華大學(xué)、加州大學(xué)圣地亞哥分校、卡耐基梅隆大學(xué)、面壁智能、中國人民大學(xué)、普林斯頓大學(xué)、新加坡國立大學(xué)、斯坦福大學(xué)和加州大學(xué)洛杉磯分校。
可配置的大模型 —— 涌現(xiàn)模塊與定制模塊
研究人員描述了涌現(xiàn)模塊和定制模塊兩種模塊類型及其構(gòu)建方式。
1. 涌現(xiàn)模塊
隨機(jī)初始化的模型參數(shù),在預(yù)訓(xùn)練過程中,模型神經(jīng)元將會(huì)自發(fā)地產(chǎn)生功能分化的現(xiàn)象,進(jìn)而組成了大模型的功能分區(qū)。在推理階段,只有與當(dāng)前輸入內(nèi)容相關(guān)的功能分區(qū)會(huì)被激活,并作用于模型的輸出結(jié)果。
 圖片
圖片
在該機(jī)制作用下,許多研究致力于發(fā)掘大模型神經(jīng)元的稀疏激活性質(zhì)與功能定位:
稀疏激活:
最早利用稀疏激活性質(zhì)的模型架構(gòu)為稀疏混合專家模型,它通過預(yù)定義的模塊化結(jié)構(gòu),強(qiáng)制每個(gè)詞僅能使用部分專家進(jìn)行計(jì)算。
進(jìn)一步地,在稠密訓(xùn)練的模型中,神經(jīng)元同樣存在稀疏激活現(xiàn)象:在處理每個(gè)詞語過程中,大量神經(jīng)元激活值的絕對(duì)值很低,無法對(duì)輸出產(chǎn)生有效貢獻(xiàn)。稀疏激活的性質(zhì)使得我們可以訓(xùn)練高效的參數(shù)選擇器,在推理時(shí)動(dòng)態(tài)選擇參數(shù)進(jìn)行計(jì)算,以降低計(jì)算開銷。
功能定位:
與人腦類似,大模型神經(jīng)元在預(yù)訓(xùn)練后產(chǎn)生了功能分化,各自僅負(fù)責(zé)部分功能。目前已經(jīng)被廣泛發(fā)現(xiàn)的功能神經(jīng)元包括:
- 知識(shí)神經(jīng)元,用于存儲(chǔ)世界三元組知識(shí);
- 技能神經(jīng)元,用于輔助模型完成特定任務(wù),例如情感分類;
- 語言神經(jīng)元,用于識(shí)別特定的語法特征或處理特定語言。
這些功能神經(jīng)元的發(fā)現(xiàn)進(jìn)一步佐證了大模型具備與人腦一樣進(jìn)行高效稀疏化推理的潛力。
2. 定制模塊(插件)
預(yù)訓(xùn)練之后,我們往往需要對(duì)模型進(jìn)行后訓(xùn)練,從而將模型與人類需求對(duì)齊,并增強(qiáng)包括領(lǐng)域能力和任務(wù)能力在內(nèi)的模型能力。最近的研究表明,后訓(xùn)練過程中參數(shù)變化本質(zhì)上是低秩的,這意味著該過程只訓(xùn)練少部分參數(shù)。受這些發(fā)現(xiàn)的啟發(fā),多樣化的定制模塊(插件)被提出。
其中,最廣為人知的是通過少參數(shù)微調(diào)形成的任務(wù)模塊,保持模型主體參數(shù)不變,僅微調(diào)少量的任務(wù)相關(guān)參數(shù)。進(jìn)一步地,許多研究發(fā)現(xiàn),小規(guī)模的外部插件,不僅可以賦予大模型任務(wù)特定的能力,還可以為它們補(bǔ)充更多額外的知識(shí)和功能,例如用于世界知識(shí)注入的知識(shí)插件、用于多模態(tài)組合的模態(tài)插件、用于長(zhǎng)文本處理的記憶插件,以及用于推理加速的壓縮插件等。
因此,該論文研究者認(rèn)為,后訓(xùn)練的本質(zhì)是定制模塊的訓(xùn)練,這些模塊可以充分補(bǔ)充和激發(fā)大模型的知識(shí)和能力。
 圖片
圖片
由涌現(xiàn)模塊與定制模塊構(gòu)成的可配置的大模型相比于傳統(tǒng)的稠密模型擁有五大優(yōu)勢(shì):
- 高效性:我們依舊可以使用數(shù)百億、數(shù)千億的參數(shù)來存儲(chǔ)海量的世界知識(shí),但每次計(jì)算過程,僅有部分參數(shù)參與計(jì)算,保證了模型效果的同時(shí),大幅降低計(jì)算開銷。
- 可復(fù)用性:不同數(shù)據(jù)、不同任務(wù)訓(xùn)練得到的模塊,可以在同一個(gè)序列中通過模塊路由器/選擇器進(jìn)行組合,實(shí)現(xiàn)能力的遷移與復(fù)用。
- 可溯源性:模塊化架構(gòu)改變了傳統(tǒng)黑盒大模型的使用方法,在推理階段,我們可以觀察到不同功能模塊的激活調(diào)用情況,從而更好地觀測(cè)模型產(chǎn)生錯(cuò)誤行為的原因。
- 可擴(kuò)展性:模塊化架構(gòu)使得我們可以通過模塊的更新與構(gòu)建實(shí)現(xiàn)對(duì)模型的更新、能力增強(qiáng),而無需對(duì)所有模型參數(shù)進(jìn)行訓(xùn)練。這使得模型可以高效地不斷學(xué)習(xí)新知識(shí)與新能力。
- 分布式計(jì)算:功能模塊的拆分使得我們?cè)诓渴鹉P蜁r(shí),可以天然地將不同模塊置于不同機(jī)器上進(jìn)行計(jì)算。例如,將包含有個(gè)人隱私數(shù)據(jù)的模塊部署在端側(cè)設(shè)備中,而將大部分通用模塊署在云端服務(wù)器,實(shí)現(xiàn)高效、安全的端云協(xié)同。
在定義了可配置的大模型架構(gòu)之后,研究人員提出了四種主要的模塊操作,通過這些操作,可以讓不同模塊進(jìn)行靈活地配合,實(shí)現(xiàn)復(fù)雜能力。
- 檢索與路由:根據(jù)需求,選擇相關(guān)的功能模塊參與計(jì)算;
- 組合:將多個(gè)單一能力的模塊進(jìn)行組合,實(shí)現(xiàn)復(fù)合能力;
- 更新:根據(jù)外部世界的需求,對(duì)特定的知識(shí)與功能模塊進(jìn)行更改;
- 增長(zhǎng):構(gòu)建新的功能模塊,對(duì)模型進(jìn)行能力增強(qiáng)的同時(shí),使其能夠與其他模塊進(jìn)行高效合作。
這些模塊化操作,使得我們能夠更方便地對(duì)模型能力進(jìn)行高效配置。
大模型的涌現(xiàn)模塊分析
進(jìn)一步地,為了驗(yàn)證大模型模塊化觀點(diǎn),作者對(duì)現(xiàn)在被廣泛使用的通用生成式大模型(Llama-3-8B-Instruct,Mistral-7B-Instruct-v0.3)進(jìn)行了涌現(xiàn)模塊分析:
- 稀疏激活特性:通用的生成式大模型是否存在稀疏激活現(xiàn)象,即每個(gè)詞僅要求少量的神經(jīng)元參與計(jì)算;
- 功能分化特性:對(duì)于不同的能力,是否存在特定的神經(jīng)元來負(fù)責(zé);
- 功能分區(qū)特性:不同的能力對(duì)應(yīng)的神經(jīng)元之間,是否存在重疊。
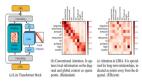
(1)針對(duì)稀疏激活特性,作者采用了神經(jīng)元激活值、神經(jīng)元輸出向量的模長(zhǎng)兩個(gè)指標(biāo),作為神經(jīng)元是否激活的評(píng)價(jià)指標(biāo)。并且,作者還開展了擾動(dòng)實(shí)驗(yàn),探究對(duì)每個(gè)詞語將其中激活指標(biāo)最低的神經(jīng)元給遮蓋掉之后,模型性能是否會(huì)受到影響。
 圖片
圖片
結(jié)果表明,對(duì)于神經(jīng)元激活值和輸出向量模長(zhǎng)兩個(gè)指標(biāo)而言,神經(jīng)元激活指標(biāo)均存在長(zhǎng)尾分布特點(diǎn),即絕大多數(shù)神經(jīng)元的激活指標(biāo)均較低。同時(shí),將每個(gè)詞激活指標(biāo)最低的70%-80%的神經(jīng)元進(jìn)行遮蓋,模型性能僅會(huì)受到非常微弱的影響。這充分表明了,通用生成式大模型存在稀疏激活特性,每次計(jì)算過程中,大量神經(jīng)元的計(jì)算對(duì)輸出并不會(huì)造成太多的影響。
(2)針對(duì)功能分化特性:作者選取了7種大模型能力,包括代碼、倫理、知識(shí)、語言、數(shù)學(xué)、翻譯和寫作能力,并且計(jì)算了神經(jīng)元激活與輸入指令所需能力之間的相關(guān)性。下圖結(jié)果表明,每種能力都有非常少量的神經(jīng)元與其高度相關(guān),而在需要改能力的指令中,大部分與該能力無關(guān)的神經(jīng)元的激活特性與隨機(jī)激活的神經(jīng)元相似。
 圖片
圖片
進(jìn)一步地,作者嘗試將每種能力特定的神經(jīng)元進(jìn)行剪枝,觀察這些神經(jīng)元對(duì)其他能力的影響。
下圖結(jié)果表明,對(duì)大部分能力而言,剪除與其最相關(guān)的神經(jīng)元,對(duì)其他能力影響甚微,表明了這些神經(jīng)元的特異性。
比如,對(duì)于Llama-3-8B-Instruct而言,剪除代碼神經(jīng)元之后,性能下降(PPL上漲了) 112%,而對(duì)其他能力的性能影響均不超過8%。
此外,Llama-3-8B-Instruct中的知識(shí)相關(guān)神經(jīng)元、Mistral-7B-Instruct-v0.3中翻譯相關(guān)神經(jīng)元對(duì)每一種能力都非常關(guān)鍵,這可能是常駐神經(jīng)元的影響,識(shí)別特定能力神經(jīng)元時(shí)算法,將常駐神經(jīng)元識(shí)別出來,影響了模型通用能力。這也進(jìn)一步需要研究者針對(duì)神經(jīng)元能力探索開展更多的后續(xù)研究。
 圖片
圖片
(3)功能分區(qū)特性:作者對(duì)不同能力神經(jīng)元開展了分布上的分析,結(jié)果發(fā)現(xiàn),不同能力神經(jīng)元之間重疊度很低。這表明,我們可以進(jìn)一步將神經(jīng)元進(jìn)行聚類分隔,形成功能分區(qū)。

大模型的定制模塊(插件)分析
Configurable Foundation Model由預(yù)訓(xùn)練階段的涌現(xiàn)模塊與后訓(xùn)練階段的定制化模塊構(gòu)成。前文已經(jīng)對(duì)大模型涌現(xiàn)模塊的相關(guān)性質(zhì)進(jìn)行了分析。同樣,作者團(tuán)隊(duì)已經(jīng)在插件構(gòu)建層面,取得了很多有益的嘗試:
- 知識(shí)插件:為實(shí)現(xiàn)高效地長(zhǎng)時(shí)知識(shí)更新,我們提出面向大模型的即插即拔參數(shù)化知識(shí)插件:把無結(jié)構(gòu)文本知識(shí)參數(shù)化為大模型的模塊,在模型需要相關(guān)知識(shí)時(shí),將模塊插入模型中實(shí)現(xiàn)知識(shí)注入。該方法能夠有效地為模型注入知識(shí),降低知識(shí)驅(qū)動(dòng)任務(wù)中的文本編碼開銷,節(jié)省69%的計(jì)算成本。
論文鏈接:https://arxiv.org/pdf/2305.17691 https://arxiv.org/pdf/2305.17660
- 長(zhǎng)文本記憶插件:為實(shí)現(xiàn)高效地短時(shí)知識(shí)記憶,我們提出面向大模型的免訓(xùn)練上下文記憶模塊:將遠(yuǎn)距離上下文存儲(chǔ)到額外的記憶單元中,并采用一種高效的機(jī)制來查找與當(dāng)前文本相關(guān)的記憶單元進(jìn)行注意力計(jì)算。實(shí)驗(yàn)結(jié)果表明,我們提出的InfLLM能夠有效地?cái)U(kuò)展Mistral、LLaMA的上下文處理窗口,并在1024K上下文的passkey檢索任務(wù)中實(shí)現(xiàn)100%召回。
論文鏈接:https://arxiv.org/pdf/2402.04617
- 加速插件:閱讀知覺廣度是影響人閱讀速度的重要因素,人單次注視可以閱讀并處理多個(gè)字詞,然而大模型卻始終只能夠逐字閱讀并處理。受啟發(fā)于此,該研究提出了一種文本推理加速模塊。該加速模塊在大模型內(nèi)部對(duì)文本序列進(jìn)行長(zhǎng)度壓縮,使得模型單次閱讀可以處理多個(gè)詞語,從而實(shí)現(xiàn)效率的提升。該加速模塊不改變大模型原本參數(shù),通過部署一個(gè)模型+多個(gè)不同速率的加速模塊,可以實(shí)現(xiàn)速度與效果的動(dòng)態(tài)平衡。
論文鏈接:https://arxiv.org/pdf/2310.15724
總結(jié)和更多研究
在本篇文章中,作者提出了一種高效模塊化架構(gòu) —— 由涌現(xiàn)模塊與定制模塊組成的可配置大模型。該架構(gòu)強(qiáng)調(diào)將大模型根據(jù)功能拆解為若干模塊,通過模塊的檢索、組合、更新、增長(zhǎng)實(shí)現(xiàn)復(fù)雜能力的組合。該架構(gòu)具有高效性、可復(fù)用性、可溯源性、可擴(kuò)展性,并且更適合分布式計(jì)算,能夠更好地契合未來大模型在端側(cè)部署、在廣泛的場(chǎng)景中使用、在新環(huán)境中進(jìn)化的未來趨勢(shì)。
清華大學(xué)自然語言處理實(shí)驗(yàn)室已經(jīng)在大模型稀疏模塊化架構(gòu)方面開展了大量的研究工作,附上相關(guān)論文列表,供大家參考:
- 參數(shù)模塊化聚類
Moefication: Transformer feed-forward layers are mixtures of experts (https://arxiv.org/pdf/2110.01786)
- 大模型稀疏模塊性增強(qiáng):
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models (https://arxiv.org/pdf/2402.13516)
ReLU^2 Wins: Discovering Efficient Activation Functions for Sparse LLMs (https://arxiv.org/pdf/2402.03804)
- 大模型模塊化性質(zhì)分析:
Emergent Modularity in Pre-trained Transformers (https://arxiv.org/pdf/2305.18390)
- 稀疏模塊化預(yù)訓(xùn)練:
Exploring the Benefit of Activation Sparsity in Pre-training (https://arxiv.org/pdf/2410.03440?)
- 神經(jīng)元功能定位:
Finding Skill Neurons in Pre-trained Transformer-based Language Model(https://arxiv.org/pdf/2211.07349)
- 大模型知識(shí)插件:
Plug-and-play document modules for pre-trained models (https://arxiv.org/pdf/2305.17660)
Plug-and-play knowledge injection for pre-trained language models (https://arxiv.org/pdf/2305.17691)
- 大模型記憶插件:
Infllm: Training-free long-context extrapolation for llms with an efficient context memory (https://arxiv.org/pdf/2402.04617)
- 大模型加速插件:
Variator: Accelerating Pre-trained Models with Plug-and-Play Compression Modules (https://arxiv.org/pdf/2310.15724)
- 大模型任務(wù)插件:
Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models (https://arxiv.org/pdf/2203.06904)