清華發布SmartMoE:一鍵實現高性能MoE稀疏大模型分布式訓練
2023 年 7 月,清華大學計算機系 PACMAN 實驗室發布稀疏大模型訓練系統 SmartMoE,支持用戶一鍵實現 MoE 模型分布式訓練,通過自動搜索復雜并行策略,達到開源 MoE 訓練系統領先性能。同時,PACMAN 實驗室在國際頂級系統會議 USENIX ATC’23 發表長文,作者包括博士生翟明書、何家傲等,通訊作者為翟季冬教授。PACMAN 實驗室在機器學習系統領域持續深入研究,SmartMoE 是繼 FastMoE, FasterMoE 和 “八卦爐” 后在大模型分布式訓練系統上的又一次探索。欲了解更多相關成果可查看翟季冬教授首頁:https://pacman.cs.tsinghua.edu.cn/~zjd
Mixture-of-Experts (MoE) 是一種模型稀疏化技術,因其高效擴展大模型參數量的特性而備受研究者關注。為了提高 MoE 模型的易用性、優化 MoE 模型訓練性能,PACMAN 實驗室在 MoE 大模型訓練系統上進行了系統深入的研究。2021 年初,開源發布了 FastMoE 系統,它是第一個基于 PyTorch 的 MoE 分布式訓練系統開源實現,在業界產生了較大的影響力。進一步,為了解決專家并行的稀疏、動態計算模式帶來的嚴重性能問題,FasterMoE 系統地分析、優化了專家并行策略。FasterMoE 中設計的「影子專家」技術顯著緩解了負載不均問題、通信 - 計算協同調度算法有效隱藏了 all-to-all 通信的高延遲。FasterMoE 成果發表在 PPoPP’22 國際會議。

- 論文地址:https://www.usenix.org/system/files/atc23-zhai.pdf
- 項目地址:https://github.com/zms1999/SmartMoE
MoE 模型遇到的難題
不同于稠密模型直接通過增大模型尺寸實現擴展,如圖一所示,MoE 技術通過將一個小模型轉變為多個稀疏激活的小模型實現參數擴展。由于各個專家在訓練時稀疏激活,MoE 模型得以在不增加每輪迭代計算量的前提下增加模型參數量;從而有望在相同訓練時間內獲得更強的模型能力。
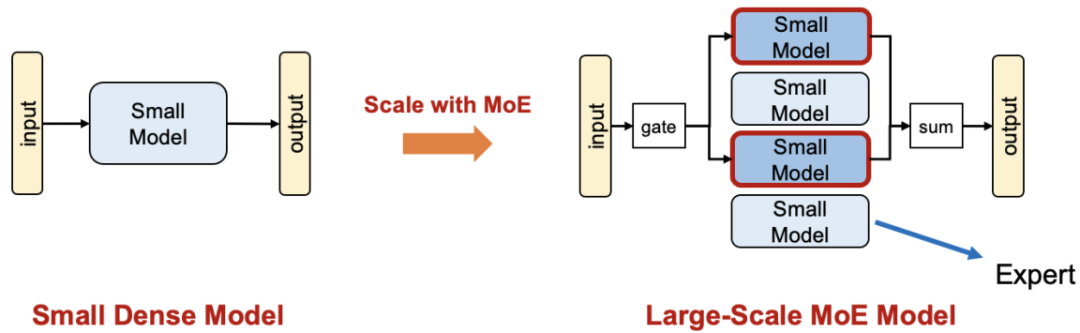
圖一:通過 MoE 技術擴展模型規模
為了實現 MoE 大模型的分布式訓練,業界提出了專家并行(Expert Parallelism)技術。如圖二所示,各個專家被分布式地存儲在不同節點上,在訓練過程中通過 all-to-all 通信將訓練數據發送至對應專家所在節點。專家并行相較于數據并行(Data Parallelism)有更小的內存開銷,因為專家參數無冗余存儲。可以認為專家并行是一種針對 MoE 結構的模型并行(Model Parallelism)。

圖二:專家并行示意圖
然而,使用樸素的專家并行技術訓練 MoE 模型有嚴重的性能問題,其根因是 MoE 模型的稀疏激活模式。它會導致節點間產生大量不規則 all-to-all 通信增加延遲、計算量負載不均造成硬件利用率低。如圖三所示的真實模型訓練過程中的專家選擇分布,可以觀察到專家間顯著的負載不均現象,且分布隨訓練進行動態變化。

圖三:真實訓練中的專家選擇分布
隨著學界對各并行策略的深入研究,使用各并行策略的復雜組合(稱為混合并行)進行大模型訓練成為必要模式。混合并行的策略調優過程十分復雜,為了提高可用性,學界提出了自動并行算法自動搜索、調優混合并行策略。然而,現有混合并行、自動并行系統無法高效處理 MoE 大模型,他們缺少對 MoE 模型訓練稀疏激活、計算負載不均且動態變化的特征的針對性設計。
SmartMoE 帶來解決方案
為了實現 MoE 模型的高效訓練,SmartMoE 系統對 MoE 模型的分布式訓練策略進行了全面的支持。對于常用的四種并行策略(數據并行、流水線并行、模型并行和專家并行),SmartMoE 系統做出了全面的支持,允許用戶對它們任意組合;在論文投稿時(2023 年 1 月),尚未有其他系統能做到這一點(如圖四所示)。
為了處理 MoE 的動態計算負載,SmartMoE 獨特設計了專家放置(Expert Placement)策略,在經典并行策略組合的基礎上,實現了動態負載均衡。如圖五所示,MoE 模型不同的計算負載(workload)會造成不同專家的過載;使用不同的專家放置順序,能在特定負載下實現節點間負載均衡。

圖四:開源分布式系統對各并行策略的支持情況對比

圖五:不同 MoE 訓練負載需要不同專家放置策略
為了提高 MoE 模型復雜混合并行策略的易用性,SmartMoE 設計了一套輕量級且有效的兩階段自動并行算法。現有自動并行系統只能在訓練開始前進行策略搜索,無法根據負載情況動態調整策略。簡單的將現有自動并行搜索算法在訓練過程中周期性使用亦不可行,因為訓練過程中的并行策略搜索和調整對延遲要求很高,現有算法的開銷過大。
SmartMoE 獨創性地將自動并行搜索過程分為兩階段:
- 訓練開始前,使用經典算法搜索,獲得一個較小的候選策略集合
- 訓練過程中,根據當前負載,在候選策略集合中動態調整,由于候選策略集合大小有限,此過程的開銷可以得到控制。
最終,SmartMoE 實現了輕量級且有效的自動并行,達到了業界領先的性能。
在性能測試中,SmartMoE 在不同模型結構、集群環境和規模下均有優異的表現。例如,在 GPT-MoE 模型的訓練性能測試中,相較于 FasterMoE,SmartMoE 有最高 1.88x 的加速比。值得注意的,在對每一輪迭代的性能觀察中發現,動態的并行策略調整是必要的,且需要使用合適的調整頻率,如圖六所示。更多實驗細節請參考論文原文。
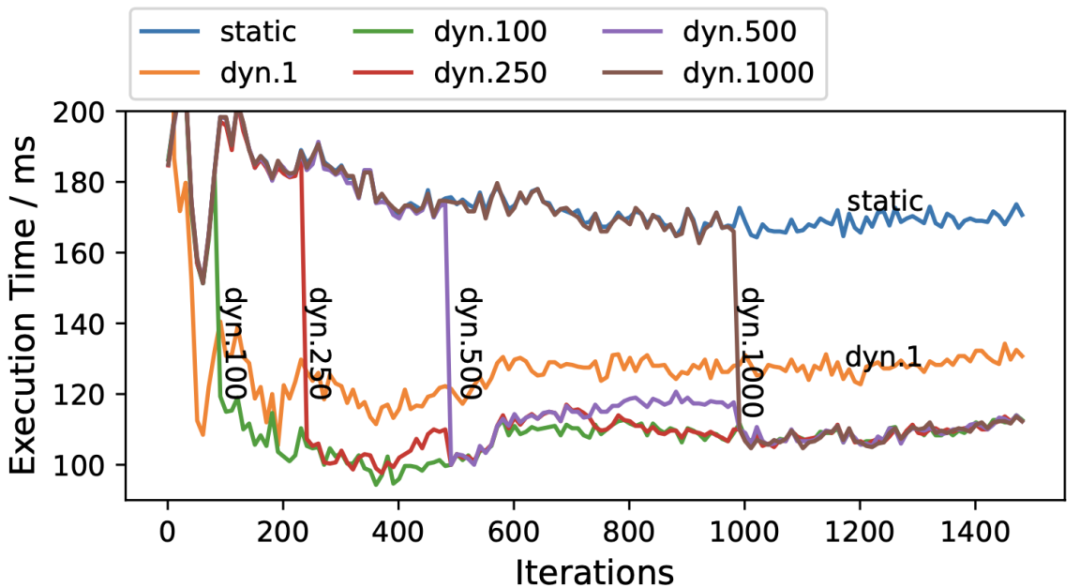 圖六:MoE 模型在不同迭代的運行時間。”dyn.X” 表示每 X 輪進行一次策略調整。
圖六:MoE 模型在不同迭代的運行時間。”dyn.X” 表示每 X 輪進行一次策略調整。

圖七:SmartMoE 在 GPT-MoE 模型端到端訓練中的性能提升
結語
SmartMoE 現已開源,開發者維護活躍,且仍在持續優化迭代,助力 MoE 大模型的發展。這是 PACMAN 實驗室繼 FastMoE,[PPoPP’22] FasterMoE,[PPoPP’22] BaGuaLu 后在大模型分布式訓練系統上的又一次探索。