打破MoE訓(xùn)練效率與性能瓶頸,華為盤古稀疏大模型全新架構(gòu)LocMoE出爐
2023 年 12 月,首個開源 MoE 大模型 Mixtral 8×7B 發(fā)布,在多種基準(zhǔn)測試中,其表現(xiàn)近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理開銷僅相當(dāng)于 12B 左右的稠密模型。為進一步提升模型性能,稠密 LLM 常由于其參數(shù)規(guī)模急劇擴張而面臨嚴峻的訓(xùn)練成本。MoE 的廣泛應(yīng)用,使得在計算成本相對不變的條件下,模型容量能夠得到顯著擴展。此特性無疑使得 MoE 成為推動 LLM 發(fā)展的關(guān)鍵技術(shù)。
MoE 設(shè)計的初衷,是使模型的學(xué)習(xí)更加 “術(shù)業(yè)有專攻”,其有效性已得到業(yè)界肯定。然而現(xiàn)有 MoE 架構(gòu)訓(xùn)練中的弊端也逐漸凸顯,主要包括:專家負載失衡、專家內(nèi)樣本混雜而專家間同質(zhì)化現(xiàn)象嚴重、額外的通信開銷等等。
為了緩解現(xiàn)有 MoE 普遍存在的訓(xùn)練效率與性能瓶頸,專精于高性能計算、LLM 訓(xùn)練加速的華為 GTS AI 計算 Lab的研究團隊提出了名為 LocMoE 的全新 MoE 架構(gòu),從路由機制角度出發(fā),以期降低稀疏 LLM 訓(xùn)練成本的同時,提升其性能。

論文鏈接:https://arxiv.org/abs/2401.13920
論文簡介
在這項工作中,作者發(fā)現(xiàn)之前的 MoE 路由機制往往會導(dǎo)致路由至同一專家網(wǎng)絡(luò)的 token 差異較大,干擾專家網(wǎng)絡(luò)的收斂;而路由至不同專家的 token 相似性較高,造成專家間同質(zhì)化現(xiàn)象嚴重,最終影響模型語義理解與生成的能力。作者通過理論闡明了專家路由與輸入數(shù)據(jù)特征之間的關(guān)聯(lián),并在 NLP 領(lǐng)域首次證明專家網(wǎng)絡(luò)存在容量下限。在此理論基礎(chǔ)上,專家路由的門控權(quán)重經(jīng)正交化處理后,明顯增強了專家網(wǎng)絡(luò)間的區(qū)分度,處理遠小于原先規(guī)模的 token,能夠在領(lǐng)域評測中達到相近的效果。同時該研究針對 MoE 架構(gòu)中固有的 All-To-All 通信瓶頸,結(jié)合負載 / 通信優(yōu)化,提出高效高能的 MoE 架構(gòu)。
具體來說,作者提出了一種名為 LocMoE 的新穎 MoE 架構(gòu),將其嵌入到盤古大模型的骨干中以增強其能力。LocMoE 旨在增強路由機制的可解釋性,同時降低額外通信與計算開銷。首先,作者發(fā)現(xiàn) token 總傾向于路由至與該 token 夾角最小的專家,當(dāng)專家間門控權(quán)重向量滿足正交時,專家網(wǎng)絡(luò)間處理的 token 能盡可能避免同質(zhì)化。
因此,本文采用 GAP 層提取 token 特征,將其作為路由的依據(jù)。GAP 層特性上滿足門控權(quán)重正交的條件,計算量相比 Dense 層也得到大幅下降。基于上述結(jié)構(gòu),作者通過理論求解出在不影響模型 loss 前提下,專家處理的 token 規(guī)模的下限,以降低專家網(wǎng)絡(luò)的負載。此外,作者結(jié)合 auxiliary loss,提出了 locality loss 對路由進行軟約束,降低跨機 All-To-All 通信開銷。最后,采用通信遮掩等工程優(yōu)化,進一步提升稀疏大模型整體的訓(xùn)練性能。
作者將 LocMoE 架構(gòu)嵌入到盤古-Σ 38B 模型中,采用語義相似度較高的 ICT 領(lǐng)域數(shù)據(jù)進行訓(xùn)練,檢驗其領(lǐng)域知識的學(xué)習(xí)能力。在十項下游任務(wù)中,LocMoE 的準(zhǔn)確性普遍高于原生盤古-Σ,訓(xùn)練性能每步提升 10%~20%。該 MoE 架構(gòu)還具有較強的通用性和易于移植性,能夠低成本嵌入到其他硬件規(guī)格和其他 MoE 架構(gòu)的 LLM 骨干中。
當(dāng)前,LocMoE 已部署至華為 ICT 服務(wù)領(lǐng)域?qū)I(yè)知識問答應(yīng)用 AskO3 上,AskO3 已上線華為 O3 知識社區(qū),獲得數(shù)萬工程師用戶群體廣泛好評。
創(chuàng)新點剖析
路由與數(shù)據(jù)特征的關(guān)系
針對現(xiàn)有 MoE 路由機制普遍缺乏可解釋性的問題,作者分析了 token 路由的本質(zhì),并設(shè)計了能夠?qū)?token 有效區(qū)分的結(jié)構(gòu)。對于某個 token,學(xué)習(xí)性的路由策略普遍選擇門控權(quán)重與該 token 乘積更大的專家進行分配:

那么,如果專家的門控權(quán)重滿足正交,能夠使得專家具備更高的判別性。同時,能夠得出 token 傾向于被路由至與其夾角更小的專家:

作者最終選取 GAP 作為提取 token 特征的結(jié)構(gòu),其門控權(quán)重能夠滿足正交的條件:

上述路由機制的實質(zhì)描述了路由判別能力與專家 token 間最小夾角之間的關(guān)聯(lián),如圖所示。

圖:LocMoE 路由機制示意圖
專家容量下界
在上述理論的基礎(chǔ)上,作者發(fā)現(xiàn),專家容量存在下界,即,在輸入數(shù)據(jù)確定的情況下,專家處理遠小于經(jīng)驗值規(guī)模的 token,也能達到相當(dāng)?shù)男阅堋T搯栴}可以轉(zhuǎn)化為,求解使得至少一個具有類別判別性 token 被路由至某個專家的最小 token 規(guī)模,作為所有專家容量拉齊時的下界。同時能夠得出,合理的專家容量與 token 和門控權(quán)重間的最小夾角呈負相關(guān),并隨著夾角的減小呈指數(shù)級增長。經(jīng)實驗證實,專家容量設(shè)為該下界時,未對模型收斂性和 loss 曲線產(chǎn)生影響。

本地性約束
LocMoE 在 MoE 層的 loss 包含兩部分:auxiliary loss 和 locality loss。auxiliary loss 首次在 sparsely-gated MoE 中提出,同時應(yīng)用于 SwitchTransformer,用以提升專家負載均衡性:

然而,跨機 All-To-All 帶來的額外通信開銷仍無法避免。因此,作者添加了本地性約束,使得在專家負載均衡的前提下,token 更傾向于被分派給本地設(shè)備的專家,最終達到約束平衡。locality loss 采用當(dāng)前 token 分布與完全本地化分布之間的差異即 KL 散度來量化,從而將部分機間通信轉(zhuǎn)為機內(nèi)通信,充分利用機內(nèi)互聯(lián)高帶寬。

實驗結(jié)果
作者分別在包含 64 張、128 張和 256 張昇騰 910A NPU 的集群上進行了實驗,主要與兩款經(jīng)典的 MoE 結(jié)構(gòu):Hash (來自 Facebook) 和 Switch (來自 Google) 進行比較。
訓(xùn)練效率
作者記錄了各實驗組訓(xùn)練過程中計算、通信、遮掩以及閑置的耗時。其中,在 64N 和 128N 的情況下,LocMoE 的計算開銷和通信開銷都是最低的。盡管 256N 時 LocMoE 的計算開銷仍然最低,但部分設(shè)備不包含專家使得本地性通信轉(zhuǎn)換失效,說明了 LocMoE 在計算及通信方面同時存在顯著增益的適用條件是專家數(shù)至少大于等于節(jié)點數(shù)。

圖:多種 MoE 結(jié)構(gòu)在不同集群配置下的訓(xùn)練效率
專家負載
為了驗證約束項對于專家負載的影響,作者分析了路由至每個專家的 token 分布情況。為了達到負載均衡,通過 RRE 模塊實現(xiàn)的 Hash 路由采用靜態(tài)路由表的硬約束確保分配的均衡性,LocMoE 和 Switch 則考慮到 token 的具體特征而進行路由。作為學(xué)習(xí)型路由,在 auxiliary 和本地性約束項的作用下,LocMoE 專家的均衡性明顯優(yōu)于 Switch,表現(xiàn)出穩(wěn)定且較高的資源利用率。

圖:多種 MoE 結(jié)構(gòu)下專家負載情況
分配給專家的樣本相似性
對于支撐 LocMoE 提出的關(guān)鍵理論,作者采用實驗對其進行了驗證。左圖表明路由到同一專家的 token 相似性更高,接近于 1。右圖則表明 token 與其路由至的專家對應(yīng)的門控權(quán)重相似度分布相較其他專家更靠右,從而證實了 token 傾向于路由至與其夾角最小的專家的理論前提,并標(biāo)記出專家容量下限求解的關(guān)鍵參數(shù) δ。
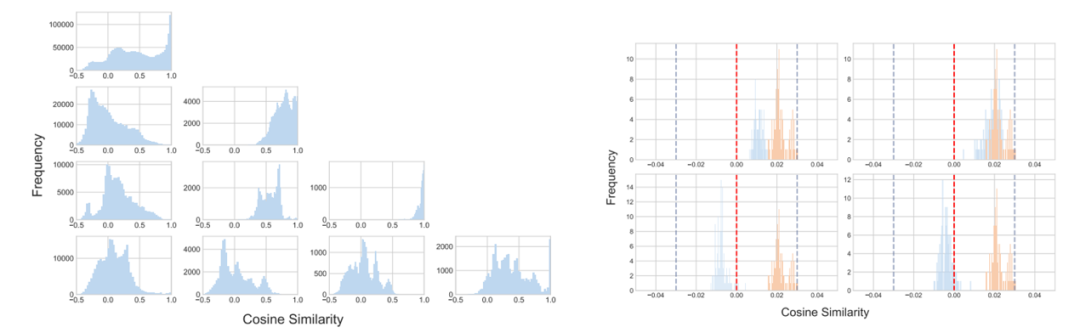
圖:路由至同一 / 不同專家 token 相似性(左);token 與其路由至的專家的相似性(右)
NLP 領(lǐng)域下游任務(wù)
盤古-Σ 已經(jīng)使用了來自金融、健康等超過 40 個領(lǐng)域的語料進行預(yù)訓(xùn)練,證明其從多領(lǐng)域文本數(shù)據(jù)中學(xué)習(xí)知識的能力。在本項工作中,作者使用 ICT 服務(wù)的領(lǐng)域數(shù)據(jù),包含無線網(wǎng)絡(luò)、光、運營商 IT 等產(chǎn)品線的技術(shù)報告和工具手冊等,評估 LocMoE 在專業(yè)領(lǐng)域知識的學(xué)習(xí)表現(xiàn)。根據(jù)概念間邏輯復(fù)雜程度分為 L1 至 L3,梳理出十類 NLP 領(lǐng)域任務(wù)的評測數(shù)據(jù)集。與原生盤古-Σ 相比,LocMoE 使得模型語義理解和表達能力都有一定程度的提高。

圖:與原生盤古-Σ 相比,NLP 領(lǐng)域下游任務(wù)表現(xiàn)