













從零開始理解 JVM 的 JIT 編譯機制
在現代軟件開發中,Java 語言因其跨平臺性和強大的生態系統而廣受歡迎。然而,性能一直是開發者關注的重點之一。為了提升 Java 應用的運行效率,Java 虛擬機(JVM)引入了多種優化技術,其中最引人注目的莫過于即時編譯(Just-In-Time Compilation,簡稱 JIT)。本文將深入探討 JVM 中的 JIT 編譯技術,揭示其背后的原理和工作機制,并介紹如何通過配置和調優來最大化應用性能。

一、詳解JIT編譯技術
1.即時編譯的執行點
在初始化階段完成后,執行引擎不斷將調用到的字節碼翻譯成機器碼交由計算機執行,Java字節碼轉為機器碼之間還有一步轉換,我們稱之為既時編譯:

最初Java字節碼文件是直接通過解釋器( Interpreter )解釋為機器碼直接運行的。對于某些執行頻率比較頻繁的代碼,我們可以稱之為熱點代碼,JIT就會針對這些熱點代碼進行相應的優化并緩存,以提升程序的運行效率:
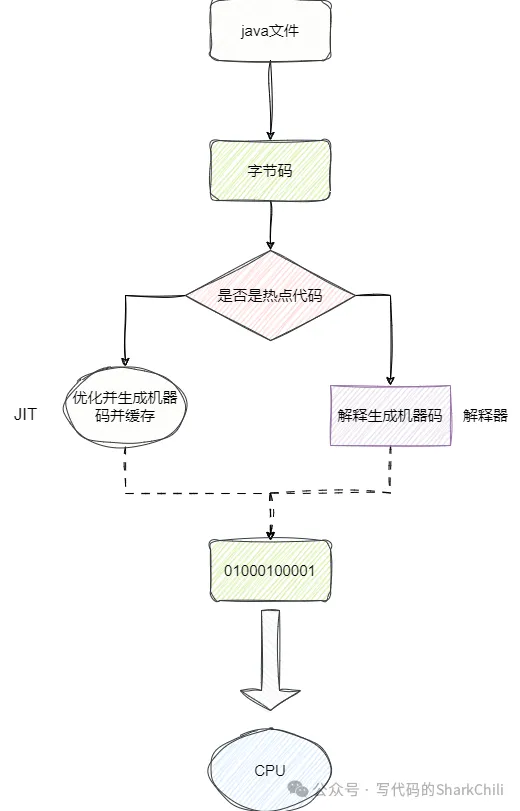
2.即時編譯器類型有哪些?
我們以HotSpot 虛擬機為例,該虛擬機內置了兩個JIT編譯器,分別為:
- C1編譯器:主要關注點在于局部性優化,常用于那些執行時間短,或者要求快速啟動的應用程序,例如GUI應用程序。
- C2編譯器:常用于長期運行且對峰值性能有高要求的服務器。
所以我們也稱C1編譯器和C2編譯器為Client Compiler或者Server Compiler。
在Java7 之前,需要根據程序的特性來選擇對應的JIT,虛擬機默認采用解釋器和其中一個編譯器配合工作。Java7 引入了分層編譯,這種方式綜合了C1 的啟動性能優勢和C2 的峰值性能優勢,我們也可以通過參數“-client”“-server” 強制指定虛擬機的即時編譯模式。分層編譯將JVM 的執行狀態分為了 5 個層次:
- 第 0 層:程序解釋執行,默認開啟性能監控功能(Profiling),如果不開啟,可觸發第二層編譯;
- 第 1 層:可稱為 C1 編譯,將字節碼編譯為本地代碼,進行簡單、可靠的優化,不開啟 Profiling;
- 第 2 層:也稱為 C1 編譯,開啟 Profiling,僅執行帶方法調用次數和循環回邊執行次數 profiling 的 C1 編譯;
- 第 3 層:也稱為 C1 編譯,執行所有帶 Profiling 的 C1 編譯;
- 第 4 層:可稱為 C2 編譯,也是將字節碼編譯為本地代碼,但是會啟用一些編譯耗時較長的優化,甚至會根據性能監控信息進行一些不可靠的激進優化。
在Java8 中,默認開啟分層編譯,-client 和-server 的設置已經是無效的了。如果只想開啟C2,可以關閉分層編譯(-XX:-TieredCompilation),如果只想用 C1,可以在打開分層編譯的同時,使用參數:-XX:TieredStopAtLevel=1。
我們可以使用java -version查看當前編譯的編譯模式,可以看到筆者服務器的JVM使用的就是混合編譯模式:
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)當然,如果我們想將編譯器模式改為解釋器模式,就可以鍵入下面這條命令:
java -Xint -version如果我們想強制運行JIT編譯模式,也可以使用
java -Xcomp -version二、JIT的熱點探測
1..什么是JIT熱點探測
HotSpot 虛擬機判定熱點代碼是基于兩種計數器進行的,分別是方法調用計數器(Invocation Counter)和回邊計數器(Back Edge Counter),只有執行代碼符合他們的標準且達到他的設置的閾值時才會進行JIT編譯優化。
2.方法調用計數器
方法調用器會針對方法的執行頻率進行相應的優化,當某個方法執行次數超過閾值時,就會觸發JIT編譯優化,這個閾值我們可以通過jinfo查看:
jinfo -flag CompileThreshold pid以筆者某個java進程為例,可以看到JVM設置的方法調用計數器判定是否是熱點代碼的條件為調用次數達到10000次:
-XX:CompileThreshold=10000這也就意味著當方法調用在一段時間(而非永久疊加)次數達到10000次的時候,就會提交一個編譯請求,后續執行時都直接用緩存中的編譯后的機器碼直接運行:

3.回邊計數器
在字節碼遇到控制流后跳轉的操作我們稱之為回邊,回邊計數器判定代碼為熱點代碼的條件是一個代碼在循環體內達到回邊計數器要求的閾值,而這個閾值我們也可以通過jinfo查看
jinfo -flag OnStackReplacePercentage pid以筆者的進程為例可以看到當回邊次數達到140時也會執行相應的JIT優化,即當這段代碼被判定為熱點代碼時,JVM就會進行一種棧上編譯的優化操作,它會將這段代碼編譯為最優邏輯保存到本地內存,在執行循環體的期間,直接使用緩存中的機器碼:
-XX:OnStackReplacePercentage=140注意:與方法計數器不同,回邊計數器沒有計數熱度衰減的過程,因此這個計數器統計的就是該方法循環執行的絕對次數。
三、JIT編譯優化技術
1.方法內聯
我們都知道方法調用會經歷一個壓棧和出棧的操作,執行調用方法時會將地址轉移到存儲該方法的起始地址上,待調用結束后,在返回原來的位置。 這就意味著一個方法調用另一個方法時,就需要保存當前方法執行位置,棧上壓入被調用方法,執行完成后,恢復現場繼續執行之前執行的方法。因此方法調用期間是有一定的時間和空間的開銷的。
所以JIT會對那些方法調用方法非常頻繁的代碼執行方法內聯:
private int add1(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}最終會被優化為如下,由此減少方法調用時壓棧和出棧的開銷:
private int add1(int x1, int x2, int x3, int x4) {
return x1 + x2 + x3 + x4;
}但是方法內斂優化也是有條件的,除了必須是熱點代碼(達到XX:CompileThreshold的閾值)以外,還要達到以下要求:
- 對于經常執行的方法,方法體要小于325字節,這個字節數可以通過-XX:MaxFreqInlineSize=N來調整。
- 對于不經常執行的方法,方法體要小于35字節,這個字節數可以由-XX:MaxInlineSize=N 來調整。
我們不妨看一段代碼,可以看到add1執行了1000000次
public class JVMJit {
public static void main(String[] args) {
for (int i = 0; i < 1000000; i++) {
add1(1, 2, 3, 4);
}
}
private static int add1(int i, int i1, int i2, int i3) {
return i + i1 + i2 + i3;
}
}我們可以對這段程序添加這樣一段參數:
-XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining他們的含義分別是:
-XX:+PrintCompilation // 在控制臺打印編譯過程信息 -XX:+UnlockDiagnosticVMOptions // 解鎖對 JVM 進行診斷的選項參數。默認是關閉的,開啟后支持一些特定參數對 JVM 進行診斷 -XX:+PrintInlining // 將內聯方法打印出來可以看到這段代碼被判定為熱點代碼,說明他已經被JVM優化了:
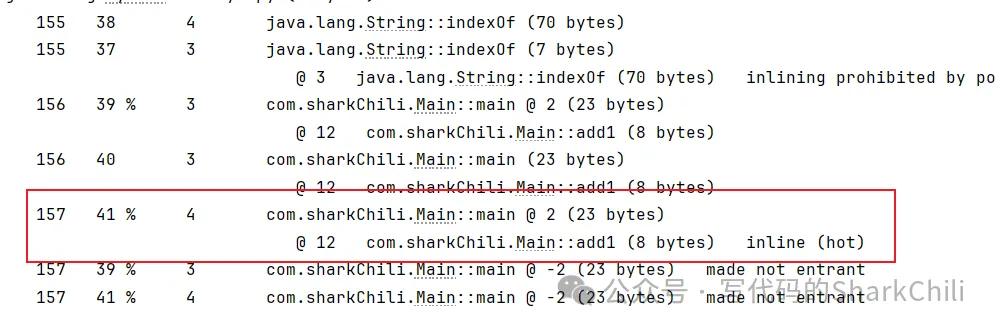
所以這就要求我們平時寫代碼時:
- 方法體盡可能小。
- 盡可能使用private、final、static修飾,避免一些沒必要的類是否繼承等相關檢查。
2.棧上分配
在將棧上分配前,我們需要先了解一個叫逃逸分析(Escape Analysis)的技術。 逃逸分析就是判斷當前操作的對象是否有被外部方法引用或外部線程訪問的一種技術,若逃逸分析判定當前對象并沒有被其他引用或者線程使用到的話,某些機制就可以開始進行優化,比如我現在要說的棧上分配。
我們都知道創建一個對象,都是在堆上分配的,假如這個對象使用封閉,GC就會將其回收,而創建和回收這一來一回的操作也是有一定開銷的。而棧則不一樣,它使用的引用或者各種變量隨著調用的結束就消亡。
而棧上分配就是抓住這一特點,當他經過逃逸分析技術發現這個對象并沒有被外部引用且僅在當前線程使用,那么它就會將該對象分配在棧上。如下面這樣一段代碼:
public static void main(String[] args) {
for (int i = 0; i < 200000 ; i++) {
getAge();
}
}
public static int getAge(){
Student person = new Student(" 小明 ",18,30);
return person.getAge();
}
static class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
...get set
}但是,在HotSpot 中暫時沒有實現這項優化。隨著即時編譯器的發展與逃逸分析技術的逐漸成熟,相信不久的將來HotSpot 也會實現這項優化功能。
3.鎖消除
同樣在逃逸分析某些沒有被外部方法或者其他線程引用的情況下,會將某些鎖消除。例如下面這段代碼,實際上你在運行時可以發現StringBuffer 和StringBuilder 性能上沒有什么區別,這正是因為鎖消除為我們做的優化工作。
public static void main(String[] args) {
appendStr(1000);
}
public static void appendStr(int count) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < count; i++) {
sb.append("no: " + i + " ");
}從編譯后的字節碼可以看出,因為對象沒有發生逃逸,中間字符串拼接操作都是通過StringBuilder完成操作的,在StringBuilder完成字符串拼接之后再追加到StringBuffer上:
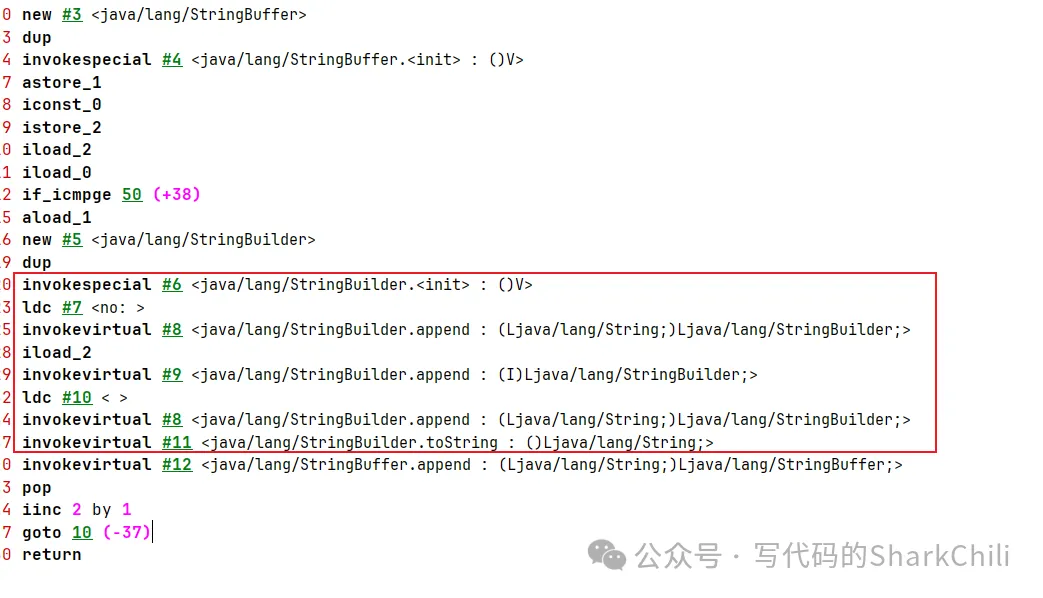
4.標量替換
當一個代碼的對象在方法上可以拆分,并且代碼僅僅是對這個對象的變量進行各種操作的話,編譯器可能會執行標量替換,如下所示
public void foo() {
TestInfo info = new TestInfo();
info.id = 1;
info.count = 99;
...//to do something
}由于上述代碼僅僅是創建一個對象后操作對象的變量,實際上這個工作似乎和對象沒有任何關聯,編譯器識別到這點之后就不去創建沒必要的對象,進而使用標量替換的方式將對象的成員變量放到棧上,避免沒必要的對象創建和銷毀。
public void foo() {
id = 1;
count = 99;
...//to do something
}我們可以通過設置JVM 參數來開關逃逸分析,還可以單獨開關同步消除和標量替換,在JDK1.8 中JVM 是默認開啟這些操作的。
-XX:+DoEscapeAnalysis 開啟逃逸分析(jdk1.8 默認開啟,其它版本未測試)
-XX:-DoEscapeAnalysis 關閉逃逸分析
-XX:+EliminateLocks 開啟鎖消除(jdk1.8 默認開啟,其它版本未測試)
-XX:-EliminateLocks 關閉鎖消除
-XX:+EliminateAllocations 開啟標量替換(jdk1.8 默認開啟,其它版本未測試)
-XX:-EliminateAllocations 關閉就可以了






















