













深入解析 Java 中的 synchronized 關鍵字
在多線程編程中,確保數據的一致性和線程安全是至關重要的問題。Java 語言提供了多種機制來實現這一目標,其中 synchronized 關鍵字是最常用且最基礎的一種同步工具。本文將通過具體的使用示例和詳細的底層原理分析,幫助讀者全面理解 synchronized 的工作方式及其在實際開發中的應用。

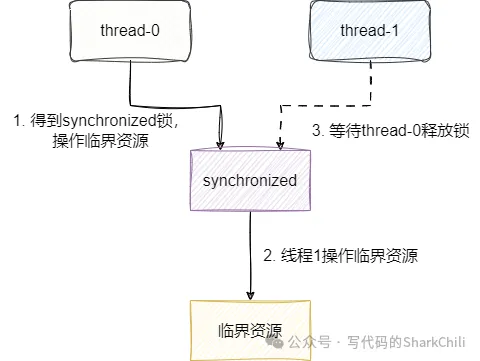
一、synchronized是什么?有什么用?
synchronized是在多線程場景經常用到的關鍵字,通過synchronized將共享資源設置為臨界資源,確保并發場景下共享資源操作的正確性:
二、synchronized基礎使用示例
1.synchronized作用于靜態方法
synchronized作用于靜態方法上,鎖的對象為Class,這就意味著方法的調用者無論是Class還是實例對象都可以保持互斥,所以下面這段代碼的結果為200:
public
class
SynchronizedDemo
{
private
static Logger logger = LoggerFactory.getLogger(SynchronizedDemo.class);
private
static
int count = 0;
/**
* synchronized作用域靜態類上
*/
public
synchronized
static
void
method()
{
count++;
}
@Test
public
void
test()
{
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->SynchronizedDemo.method());
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->new SynchronizedDemo().method());
logger.info("count:{}",count);
}
}輸出結果:
22:59:44.647 [main] INFO com.sharkChili.webTemplate.SynchronizedDemo - count:200002.synchronized作用于方法
作用于方法上,則鎖住的對象是調用的示例對象,如果我們使用下面這段寫法,最終的結果卻不是10000。
private
static Logger logger = LoggerFactory.getLogger(SynchronizedDemo.class);
private
static
int count = 0;
/**
* synchronized作用域實例方法上
*/
public
synchronized
void
method()
{
count++;
}
@Test
public
void
test()
{
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->new SynchronizedDemo().method());
logger.info("count:{}",count);
}
}輸出結果:
2023-03-16
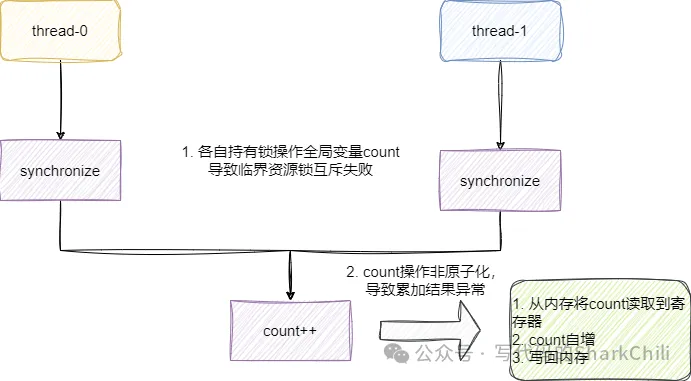
21:03:44,300 INFO SynchronizedDemo:30 - count:8786因為synchronized 作用于實例方法,會導致每個線程獲得的鎖都是各自使用的實例對象,而++操作又非原子操作,導致互斥失敗進而導致數據錯誤。 什么是原子操作呢?通俗的來說就是一件事情只要一條指令就能完成,而count++在底層匯編指令如下所示,可以看到++操作實際上是需要3個步驟完成的:
- 從內存將count讀取到寄存器
- count自增
- 寫回內存
__asm
{
moveax, dword ptr[i]
inc eax
mov dwordptr[i], eax
}正是由于鎖互斥的失敗,導致兩個線程同時到臨界區域加載資源,獲得的count都是0,經過自增后都是1,導致數據少了1。
所以正確的使用方式是多個線程使用同一個對象調用該方法:
SynchronizedDemo demo = new SynchronizedDemo();
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->demo.method());
logger.info("count:{}",count);這樣一來輸出的結果就正常了。
2023-03-16
23:08:23,656 INFO SynchronizedDemo:31 - count:100003.synchronized作用于代碼塊
作用于代碼塊上的synchronized鎖住的就是括號內的對象實例,以下面這段代碼為例,鎖的就是當前調用者。
public
void
method()
{
synchronized (this) {
count++;
}
}所以我們的使用的方式還是和作用與實例方法上一樣。
@Test
public
void
test()
{
SynchronizedDemo demo = new SynchronizedDemo();
IntStream.rangeClosed(1, 1_0000)
.parallel()
.forEach(i -> demo.method());
logger.info("count:{}", count);
}輸出結果也是10000:
2023-03-16
23:11:08,496 INFO SynchronizedDemo:33 - count:10000三、深入理解synchronized關鍵字
1.synchronized工作的本質
我們給出一段synchronized作用于代碼塊上的方法:
public
class
SynchronizedDemo
{
private
static
int count = 0;
/**
* synchronized作用域實例方法內
*/
public
void
method()
{
synchronized (this) {
count++;
}
}
public
static
void
main(String[] args)
{
SynchronizedDemo demo = new SynchronizedDemo();
IntStream.rangeClosed(1, 1_0000)
.parallel()
.forEach(i -> demo.method());
System.out.println("count:" + count);
}
}先使用javac指令生成class文件:
javac SynchronizedDemo.java然后再使用反編譯指令javap獲取反編譯后的代碼信息:
javap -c -s -v SynchronizedDemo.class最終我們可以看到method方法的字節碼指令,可以看到關鍵字synchronized 的鎖是通過monitorenter和monitorexit來確保線程間的同步。
public
void
method();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #2
// Field count:I
7: iconst_1
8: iadd
9: putstatic #2
// Field count:I
12: aload_1
13: monitorexit
14: goto 22
17: astore_2
18: aload_1
19: monitorexit
20: aload_2
21: athrow
22: return我們再將synchronized 關鍵字改到方法上再次進行編譯和反編譯:
public
synchronized
void
method()
{
count++;
}可以看到synchronized 實現鎖的方式編程了通過ACC_SYNCHRONIZED關鍵字來標明該方法是一個同步方法:
public
synchronized
void
method();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #2
// Field count:I
3: iconst_1
4: iadd
5: putstatic #2
// Field count:I
8: return
LineNumberTable:
line 17: 0
line 19: 8了解了不同synchronized在不同位置使用的指令之后,我們再來聊聊這些指令如何實現"鎖"的。
因為JDK1.6之后提出鎖升級的機制,涉及不同層面的鎖的過程,這里我們直接以默認情況下最高級別的重量級鎖為例展開探究。
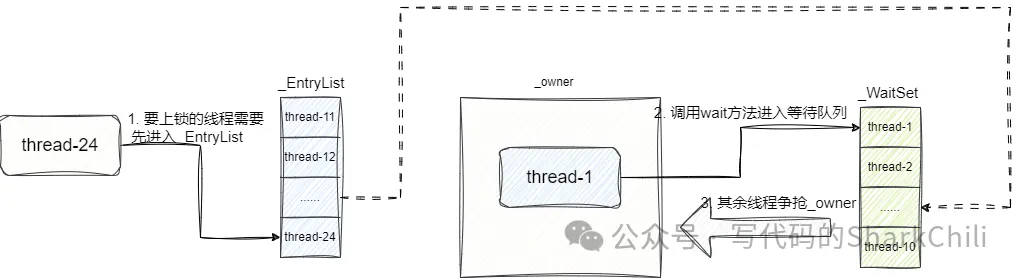
每個線程使用的實例對象都有一個對象頭,每個對象頭中都有一個Mark Word,當我們使用synchronized 關鍵字時,這個Mark Word就會指向一個monitor。 這個monitor鎖就是一種同步工具,是實現線程操作臨界資源互斥的關鍵所在,在Java HotSpot虛擬機中,monitor就是通過ObjectMonitor實現的。
其代碼如下,我們可以看到_EntryList、_WaitSet 、_owner三個關鍵屬性:
ObjectMonitor() {
_header = NULL;
_count = 0; // 記錄線程獲取鎖的次數
_waiters = 0,
_recursions = 0; //鎖的重入次數
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor對象的線程
_WaitSet = NULL; // 處于wait狀態的線程,會被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 處于等待鎖block狀態的線程,會被加入到該列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
我們假設自己現在就是一個需要獲取鎖的線程,要獲取ObjectMonitor鎖,所以我們經過了下面幾個步驟:
- 進入_EntryList。
- 嘗試取鎖,發現_owner區被其他線程持有,于是進入_WaitSet 。
- 其他線程用完鎖,將count--變為0,釋放鎖,_owner被清空。
- 我們有機會獲取_owner,嘗試爭搶,成功獲取鎖,_owner指向我們這個線程,將count++。
- 我們操作到一半發現CPU時間片用完了,調用wait方法,線程再次進入_WaitSet ,count--變為0,_owner被清空。
- 我們又有機會獲取_owner,嘗試爭搶,成功獲取鎖,將count++。
- 這一次,我們用完臨界資源,準備釋放鎖,count--變為0,_owner清空,其他線程繼續進行monitor爭搶。
2.synchronized如何保證可見性、有序性、可重入性
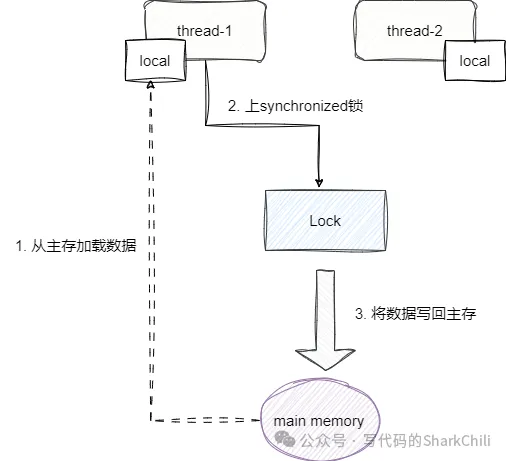
我們先來說說可見性,每個線程使用synchronized獲得鎖操作臨界資源時,首先需要獲取臨界資源的值,為了保證臨界資源的值是最新的,JMM模型規定線程必須將本地工作內存清空,到共享內存中加載最新的進行操作。 當前線程上鎖后,其他線程是無法操作這個臨界資源的。當前線程操作完臨界資源之后,會立刻將值寫回主存中,正是由于每個線程操作期間其他線程無法干擾,且臨界資源數據實時同步,所以synchronized關鍵字保證了臨界資源數據的可見性。
再來說說有序性,synchronized同步的代碼塊具備排他性,這就意味著同一個時刻只有一個線程可以獲得鎖,synchronized代碼塊的內部資源是單線程執行的。同時synchronized也遵守as-if-serial原則,可以當線程線程修改最終結果是可以保證最終有序性,注意這里筆者說的保證最終結果的有序性。
具體例子,某段線程得到鎖Test.class之后,執行臨界代碼邏輯,可能會先執行變量b初始化的邏輯,在執行a變量初始化的邏輯,但是最終結果都會執行a+b的邏輯。這也就我們的說的保證最終結果的有序,而不保證執行過程中的指令有序。
synchronized (Test.class) {
int a=1;
int b=2;
int c=a+b;最后就是有序性了,Java允許同一個線程獲取同一把鎖兩次,即可重入性,原因我們上文將synchronized相關的ObjectMonitor鎖已經提到了,ObjectMonitor有一個count變量就是用于記錄當前線程獲取這把鎖的次數。 就像下面這段代碼,例如我們的線程T1,兩次執行synchronized 獲取鎖Test.class兩次,count就自增兩次變為2。 退出synchronized關鍵字對應的代碼塊,count就自減,變為0時就代表釋放了這把鎖,其他線程就可以爭搶這把鎖了。所以當我們的線程退出下面的兩個synchronized 代碼塊時,其他線程就可以爭搶Test.class這把鎖了。
public
void
add2()
{
synchronized (Test.class) {
synchronized (Test.class){
list.add(1);
}
}
}四、詳解synchronized鎖粗化和鎖消除
1.鎖粗化
當jvm發現操作的方法連續對同一把鎖進行加鎖、解鎖操作,就會對鎖進行粗化,所有操作都在同一把鎖中完成:

如下代碼所示,該方法內部連續3次上同一把鎖,存在頻繁上鎖執行monitorenter和monitorexit的開銷:
private
static
void
func1()
{
synchronized (lock) {
System.out.println("lock first");
}
synchronized (lock) {
System.out.println("lock second");
}
synchronized (lock) {
System.out.println("lock third");
}
}
這一點我們通過jclasslib查看字節碼即可知曉這一點:

對此JIT編譯器一旦感知到這種一個操作頻繁加解同一把鎖的情況,便會將鎖進行粗化,最終的代碼效果大概是這樣:
private
static
void
func1()
{
synchronized (lock) {
System.out.println("lock first");
System.out.println("lock second");
System.out.println("lock third");
}
}2.鎖消除
虛擬機在JIT即時編譯運行時,對一些代碼上要求同步,但是檢測到不存在共享數據的鎖的進行消除。
下面這段代碼涉及字符串拼接操作,所以jvm會將其優化為StringBuffer或者StringBuilder,至于選哪個,這就需要進行逃逸分析了。逃逸分析通俗來說就是判斷當前操作的對象是否會逃逸出去被其他線程訪問到。
public String appendStr(String str1, String str2, String str3)
{
String result = str1 + str2 + str3;
return result;
}例如我們上面的result ,是局部變量,沒有發生逃逸,所以完全可以當作棧上數據來對待,是線程安全的,所以jvm進行鎖消除,使用StringBuilder而不是Stringbuffer完成字符串拼接:
這一點我們可以在字節碼文件中得到印證
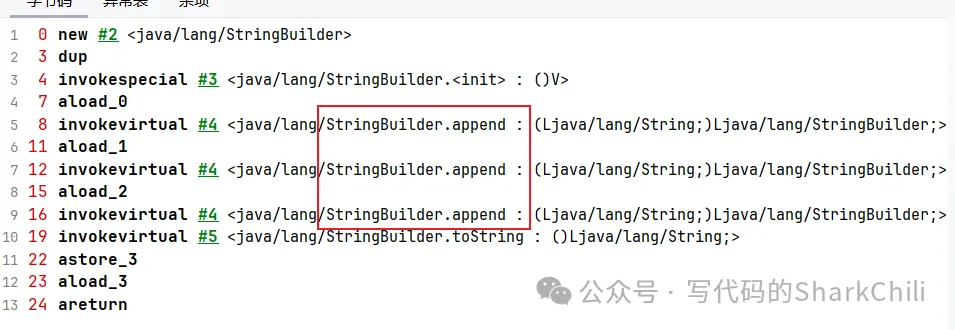
五、synchronized的鎖升級
1.詳解鎖升級過程
synchronized關鍵字在JDK1.6之前底層都是直接調用ObjectMonitor的enter和exit完成對操作系統級別的重量級鎖mutex的使用,這使得每次上鎖都需要從用戶態轉內核態嘗試獲取重量級鎖的過程。
這種方式也不是不妥當,在并發度較高的場景下,取不到mutex的線程會因此直接阻塞,到等待隊列_WaitSet 中等待喚醒,而不是原地自選等待其他線程釋放鎖而立刻去爭搶,從而避免沒必要的線程原地自選等待導致的CPU開銷,這也就是我們上文中講到的synchronized工作原理的過程。
但是在并發度較低的場景下,可能就10個線程,競爭并不激烈可能線程等那么幾毫秒就可以拿到鎖了,而我們每個線程卻還是需要不斷從用戶態到內核態獲取重量級鎖、到_WaitSet 中等待機會的過程,這種情況下,可能功能的開銷還不如所競爭的開銷來得激烈。
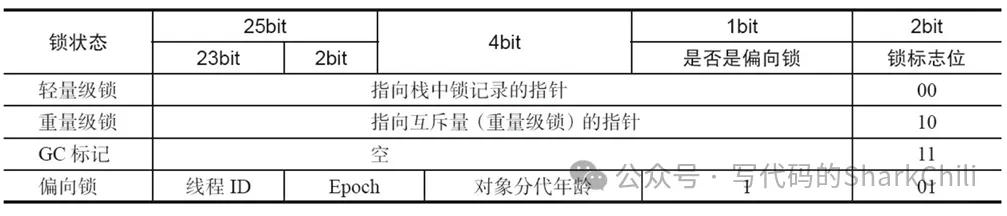
所以JDK1.6之后,HotSpot虛擬機就對synchronized底層做了一定的優化,通俗來說根據線程競爭的激烈程度的不斷增加逐步進行鎖升級的策略。對應的我們先給出32位虛擬機中不同級別的鎖在對象頭mark word中的標識變化:
我們假設有這樣一個場景,我們有一個鎖對象LockObj,我們希望用它作為鎖,使用代碼邏輯如下所示:
synchronized(LockObj){
//dosomething
}我們把自己當作一個線程,一開始沒有線程競爭時,synchronized鎖就是無鎖狀態,無需進行任何鎖爭搶的邏輯。此時鎖對象LockObj的偏向鎖標志位為0,鎖標記為01。
后續線程1需要嘗試執行該語句塊,首先通過CAS修改mark word中的信息,即鎖的對象LockObj的對象頭偏向鎖標記為1,鎖標記為01,我們的線程開始嘗試獲取這把鎖,并將線程id就當前線程號即可。
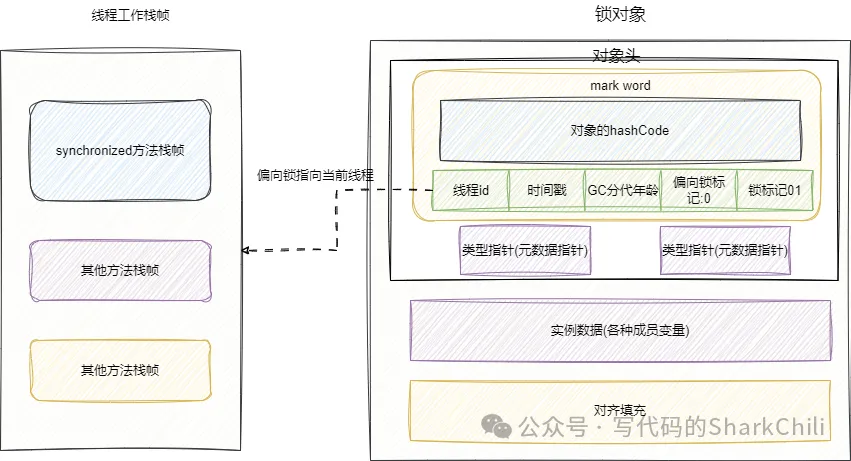
后續線程1操作鎖時,只需比較一下mark word中的鎖是否是偏向鎖且線程id是否是線程1即可:
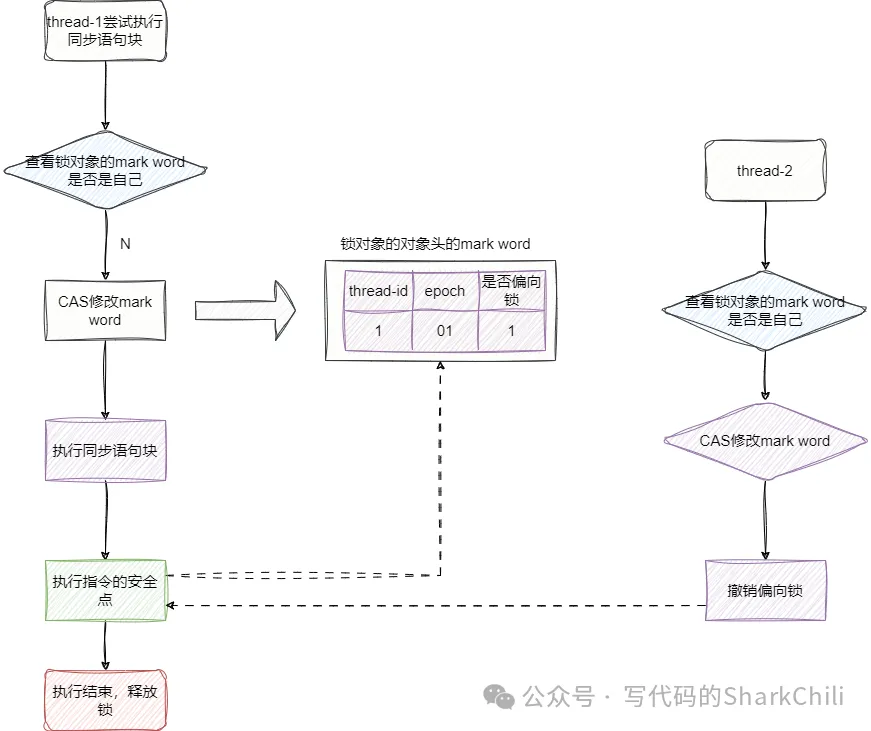
當我們發現偏向鎖中指向的線程id不是我們時,就執行下面的邏輯:
- 我們嘗試CAS競爭這把鎖,如果成功則將鎖對象的markdown中的線程id設置為我們的線程id,然后執行代碼邏輯。
- 我們嘗試CAS競爭這把鎖失敗,則當持有鎖的線程到達安全點的時候,直接將這個線程掛起并執行鎖撤銷,將偏向鎖升級為輕量級鎖,然后持有鎖的線程繼續自己的邏輯,我們的線程繼續等待機會。
這里可能有讀者好奇什么叫安全點?
這里我們可以通俗的理解一下,安全點就是代碼執行到的一個特殊位置,當線程執行到這個位置時,我們可以將線程暫停下來,讓我們在暫停期間做一些處理。我們上文中將偏向鎖升級為輕量級鎖就是在安全點將線程暫停一下,將鎖升級為輕量級鎖,然后再讓線程進行進一步的工作。
升級為輕量級鎖時,偏向鎖標記為0,鎖標記變為是00。此時,如果我們的線程需要獲取這個輕量級鎖時的過程如下:
- 判斷當前這把鎖是否為輕量級鎖,如果是則在線程棧幀中劃出一塊空間,存放這把鎖的信息,我們這里就把它稱為"鎖記錄",并將鎖對象的markword復制到鎖記錄中。
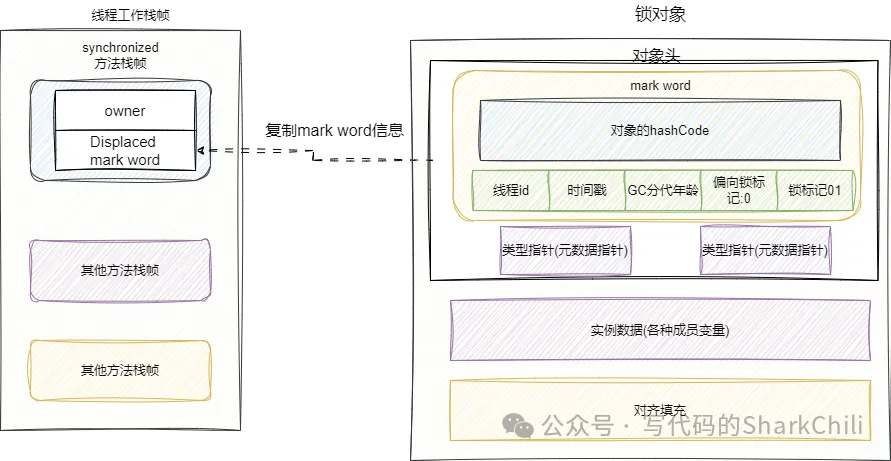
- 復制成功之后,通過CAS的方式嘗試將鎖對象頭中markword更新為鎖記錄的地址,并將owner指向鎖對象頭的markword。如果這幾個步驟操作成功,則說明獲取輕量級鎖成功了。
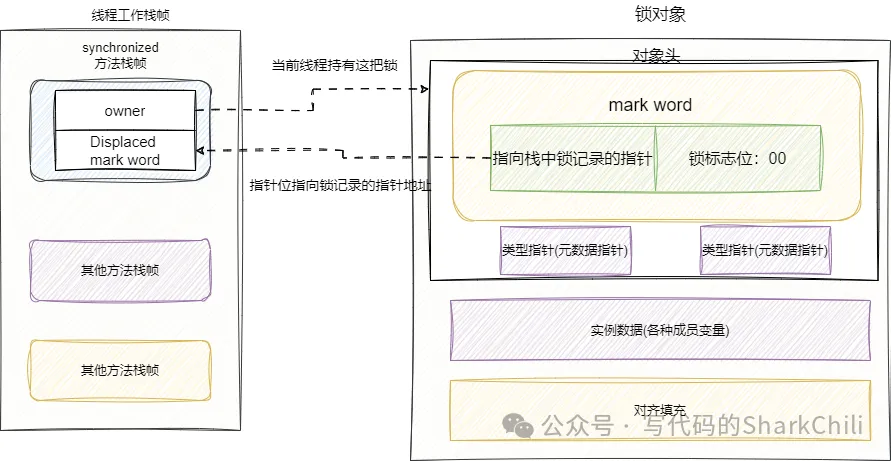
- 如果線程CAS操作失敗,則進行自旋獲取鎖,如果自旋超過10次(默認設置為10次)還沒有得到鎖則將鎖升級為重量級鎖,升級為重量級鎖時,鎖標記為0,鎖狀態為10。由此導致持有鎖的線程進行釋放時需要CAS修改mark word信息失敗,發現鎖已經被其他線程膨脹為重量級鎖,對應釋放操作改為將指針地址置空,然后喚醒其他等待的線程嘗試獲取鎖。
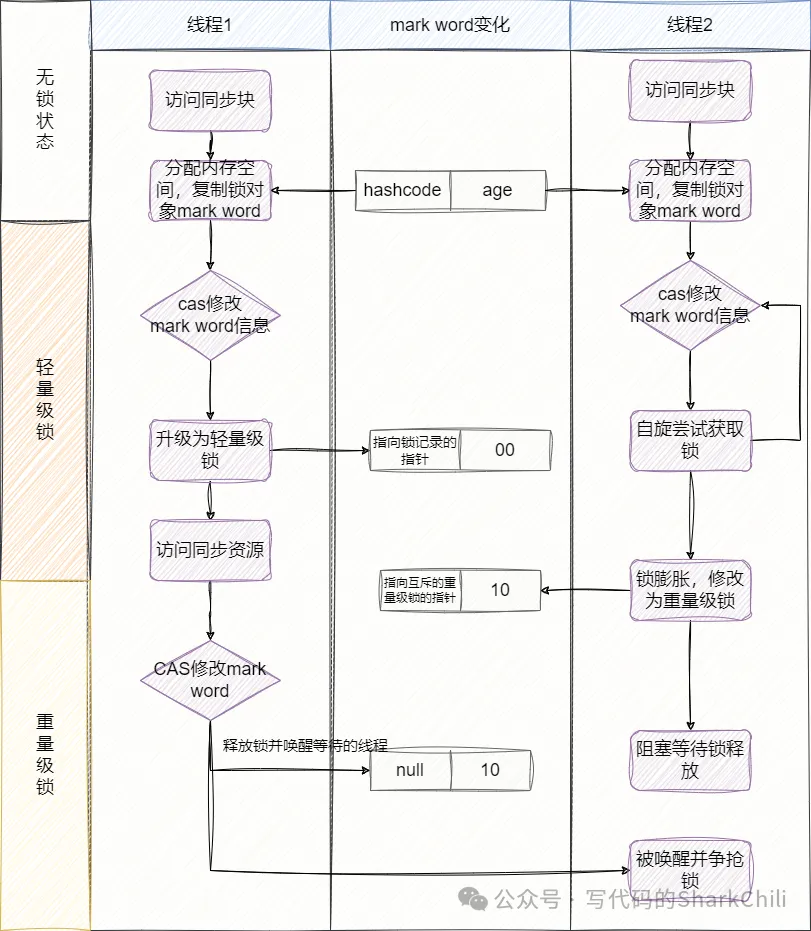
經過上述的講解我們對鎖升級有了一個全流程的認識,在這里做個階段小結:
- 無線程競爭,無鎖狀態:偏向鎖標記為0,鎖標記為01。
- 存在一定線程競爭,大部分情況下會是同一個線程獲取到,升級為偏向鎖,偏向標記為1,鎖標記為01。
- 線程CAS爭搶偏向鎖鎖失敗,鎖升級為輕量級鎖,偏向標記為0,鎖標記為00。
- 線程原地自旋超過10次還未取得輕量級鎖,鎖升級為重量級鎖,避免大量線程原地自旋造成沒必要的CPU開銷,偏向鎖標記為0,鎖標記為10。
2.基于jol-core代碼印證
上文我們將自己當作一個線程了解完一次鎖升級的流程,口說無憑,所以我們通過可以通過代碼來印證我們的描述。
上文講解鎖升級的之后,我們一直在說對象頭的概念,所以為了能夠直觀的看到鎖對象中對象頭鎖標記和鎖狀態的變化,我們這里引入一個jol工具。
<!--jol內存分析工具-->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>然后我們聲明一下鎖對象作為實驗對象。
public
class
Lock
{
private
int count;
public
int
getCount()
{
return count;
}
public
void
setCount(int count)
{
this.count = count;
}
}首先是無鎖狀態的代碼示例,很簡單,沒有任何線程爭搶邏輯,就通過jol工具打印鎖對象信息即可。
public
class
Lockless
{
public
static
void
main(String[] args)
{
Lock object=new Lock();
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}打印結果如下,我們只需關注第一行的object header,可以看到第一列的00000001,我們看到后3位為001,偏向鎖標記為0,鎖標記為01,001這就是我們說的無鎖狀態。
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0
4 (object header) 01
00
00
00 (00000001
00000000
00000000
00000000) (1)
4
4 (object header) 00
00
00
00 (00000000
00000000
00000000
00000000) (0)
8
4 (object header) 43 c1 00
20 (01000011
11000001
00000000
00100000) (536920387)
12
4
int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total接下來是偏向鎖,我們還是用同樣的代碼即可,需要注意的是偏向鎖必須在jvm啟動后的一段時間才會運行,所以如果我們想打印偏向鎖必須讓線程休眠那么幾秒,這里筆者就偷懶了一下,通過設置jvm參數-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0,通過禁止偏向鎖延遲,直接打印出偏向鎖信息
public
class
BiasLock
{
public
static
void
main(String[] args)
{
Lock object = new Lock();
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}輸出結果如下,可以看到對象頭的信息為00000101,此時鎖標記為1即偏向鎖標記,鎖標記為01,101即偏向鎖。
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0
4 (object header) 05
00
00
00 (00000101
00000000
00000000
00000000) (5)
4
4 (object header) 00
00
00
00 (00000000
00000000
00000000
00000000) (0)
8
4 (object header) 43 c1 00
20 (01000011
11000001
00000000
00100000) (536920387)
12
4
int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total然后的輕量級鎖的印證,我們只需使用Lock對象作為鎖即可。
public
class
LightweightLock
{
public
static
void
main(String[] args)
{
Lock object = new Lock();
synchronized (object) {
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
}可以看到輕量級鎖鎖標記為0,鎖標記為00,000即輕量級。
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0
4 (object header) e8 f1 96
02 (11101000
11110001
10010110
00000010) (43446760)
4
4 (object header) 00
00
00
00 (00000000
00000000
00000000
00000000) (0)
8
4 (object header) 43 c1 00
20 (01000011
11000001
00000000
00100000) (536920387)
12
4
int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total最后就是重量級鎖了,我們只需打印出鎖對象的哈希碼即可將其升級為重量級鎖。
public
class
HeavyweightLock
{
public
static
void
main(String[] args)
{
Lock object = new Lock();
synchronized (object) {
System.out.println(object.hashCode());
}
synchronized (object) {
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
}輸出結果為10001010,偏向鎖標記為0,鎖標記為10,010為重量級鎖。
1365202186
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0
4 (object header) 8a 15
83
17 (10001010
00010101
10000011
00010111) (394466698)
4
4 (object header) 00
00
00
00 (00000000
00000000
00000000
00000000) (0)
8
4 (object header) 43 c1 00
20 (01000011
11000001
00000000
00100000) (536920387)
12
4
int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total3.更多關于jol-core
jol不僅僅可以監控Java進程的鎖情況,在某些場景下,我們希望通過比較對象的地址來判斷當前創建的實例是否是多例,是否存在線程安全問題。此時,我們就可以VM對象的方法獲取對象地址,如下所示:
public
static
void
main(String[] args) throws Exception {
//打印字符串aa的地址
System.out.println(VM.current().addressOf("aa"));
}六、常見面試題
synchronized和ReentrantLock的區別
我們可以從三個角度來了解兩者的區別:
- 從實現角度:synchronized是JVM層面實現的鎖,ReentrantLock是屬于Java API層面實現的鎖,所以用起來需要我們手動上鎖lock和釋放鎖unlock。
- 從性能角度:在JDK1.6之前可能ReentrantLock性能更好,在JDK1.6之后由于JVM對synchronized增加適應性自旋鎖、鎖消除等策略的優化使得synchronized和ReentrantLock性能并無太大的區別。
- 從功能角度:ReentrantLock相比于synchronized增加了更多的高級功能,例如等待可中斷、公平鎖、選擇性通知等功能。



















