在圖像、視頻生成上,語言模型首次擊敗擴散模型,tokenizer是關鍵
大型語言模型(LLM 或 LM)一開始是用來生成語言的,但隨著時間的推移,它們已經能夠生成多種模態的內容,并在音頻、語音、代碼生成、醫療應用、機器人學等領域開始占據主導地位。
當然,LM 也能生成圖像和視頻。在此過程中,圖像像素會被視覺 tokenizer 映射為一系列離散的 token。然后,這些 token 被送入 LM transformer,就像詞匯一樣被用于生成建模。盡管 LM 在視覺生成方面取得了顯著進步,但 LM 的表現仍然不如擴散模型。例如,在圖像生成的金標基準 —ImageNet 數據集上進行評估時,最佳語言模型的表現比擴散模型差了 48% 之多(以 256?256 分辨率生成圖像時,FID 為 3.41 對 1.79)。
為什么語言模型在視覺生成方面落后于擴散模型?來自谷歌、CMU 的研究者認為,主要原因是缺乏一個良好的視覺表示,類似于我們的自然語言系統,以有效地建模視覺世界。為了證實這一假設,他們進行了一項研究。

論文鏈接:https://arxiv.org/pdf/2310.05737.pdf
這項研究表明,在相同的訓練數據、可比模型大小和訓練預算條件下,利用良好的視覺 tokenizer,掩碼語言模型在圖像和視頻基準的生成保真度和效率方面都超過了 SOTA 擴散模型。這是語言模型在標志性的 ImageNet 基準上擊敗擴散模型的首個證據。
需要強調的是,研究者的目的不是斷言語言模型是否優于其他模型,而是促進 LLM 視覺 tokenization 方法的探索。LLM 與其他模型(如擴散模型)的根本區別在于,LLM 使用離散的潛在格式,即從可視化 tokenizer 獲得的 token。這項研究表明,這些離散的視覺 token 的價值不應該被忽視,因為它們存在以下優勢:
1、與 LLM 的兼容性。token 表示的主要優點是它與語言 token 共享相同的形式,從而可以直接利用社區多年來為開發 LLM 所做的優化,包括更快的訓練和推理速度、模型基礎設施的進步、擴展模型的方法以及 GPU/TPU 優化等創新。通過相同的 token 空間統一視覺和語言可以為真正的多模態 LLM 奠定基礎,后者可以在我們的視覺環境中理解、生成和推理。
2、壓縮表示。離散 token 可以為視頻壓縮提供一個新的視角。可視化 token 可以作為一種新的視頻壓縮格式,以減少數據在互聯網傳輸過程中占用的磁盤存儲和帶寬。與壓縮的 RGB 像素不同,這些 token 可以直接輸入生成模型,繞過傳統的解壓縮和潛在編碼步驟。這可以加快生成視頻應用的處理速度,在邊緣計算情況下尤其有益。
3、視覺理解優勢。先前的研究表明,離散 token 在自監督表示學習中作為預訓練目標是有價值的,如 BEiT 和 BEVT 中所討論的那樣。此外,研究發現,使用 token 作為模型輸入提高了魯棒性和泛化性。
在這篇論文中,研究者提出了一個名為 MAGVIT-v2 的視頻 tokenizer,旨在將視頻(和圖像)映射為緊湊的離散 token。
該模型建立在 VQ-VAE 框架內的 SOTA 視頻 tokenizer——MAGVIT 基礎上。基于此,研究者提出了兩種新技術:1)一種新穎的無查找(lookup-free)量化方法,使得大量詞匯的學習成為可能,以提高語言模型的生成質量;2)通過廣泛的實證分析,他們確定了對 MAGVIT 的修改方案,不僅提高了生成質量,而且還允許使用共享詞匯表對圖像和視頻進行 token 化。
實驗結果表明,新模型在三個關鍵領域優于先前表現最好的視頻 tokenizer——MAGVIT。首先,新模型顯著提高了 MAGVIT 的生成質量,在常見的圖像和視頻基準上刷新了 SOTA。其次,用戶研究表明,其壓縮質量超過了 MAGVIT 和當前的視頻壓縮標準 HEVC。此外,它與下一代視頻編解碼器 VVC 相當。最后,研究者表明,與 MAGVIT 相比,他們的新 token 在兩個設置和三個數據集的視頻理解任務中表現更強。
方法介紹
本文引入了一種新的視頻 tokenizer,旨在將視覺場景中的時間 - 空間動態映射為適合語言模型的緊湊離散 token。此外,該方法建立在 MAGVIT 的基礎上。
隨后,該研究重點介紹了兩種新穎的設計:無查找量化(Lookup-Free Quantization ,LFQ)和 tokenizer 模型的增強功能。
無查找量化
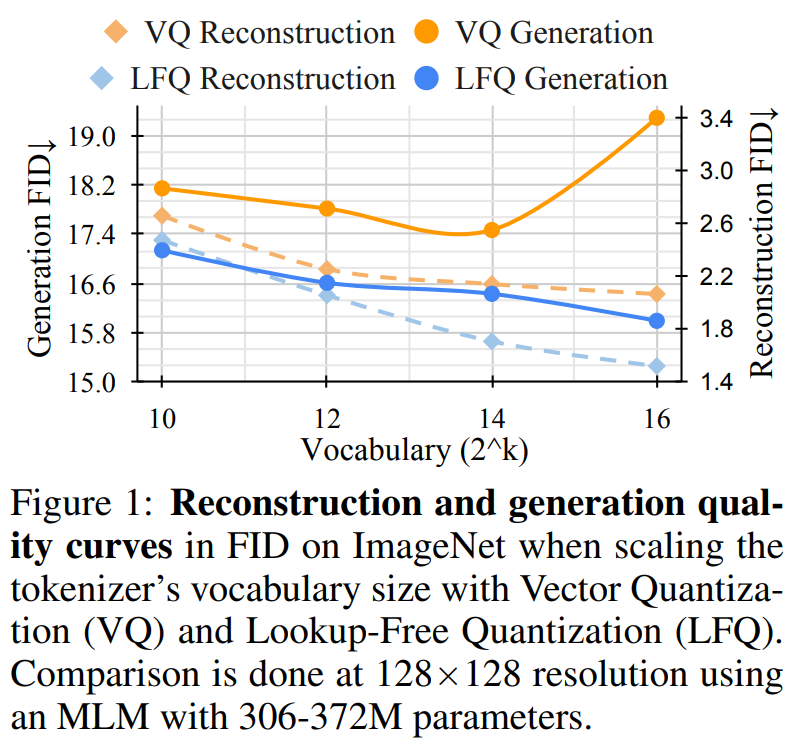
最近一段時間,VQ-VAE 模型取得巨大進展,但該方法存在一個缺點,即重建質量的改進與后續生成質量之間的關系不明確。很多人誤以為改進重建就等于改進語言模型的生成,例如,擴大詞匯量可以提高重建質量。然而,這種改進僅適用于詞匯量較小時的生成,而詞匯量非常大時會損害語言模型的性能。
本文將 VQ-VAE codebook 嵌入維度縮減到 0 ,即 Codebook  被替換為一個整數集
被替換為一個整數集 ,其中
,其中 。
。
與 VQ-VAE 模型不同的是,這種新設計完全消除了對嵌入查找的需要,因此將其稱為 LFQ。本文發現 LFQ 可以通過增加詞匯量,提高語言模型的生成質量。如圖 1 中的藍色曲線所示,隨著詞匯量的增加,重建和生成都不斷改進 —— 這是當前 VQ-VAE 方法中未觀察到的特性。
到目前為止,可用的 LFQ 方法很多,但本文討論了一種簡單的變體。具體來說,LFQ 的潛在空間被分解為單維變量的笛卡爾積,即  。假定給定一個特征向量
。假定給定一個特征向量 ,量化表示 q (z) 的每個維度從以下獲得:
,量化表示 q (z) 的每個維度從以下獲得:

對于 LFQ ,q (z) 的 token 索引為:

除此以外,本文在訓練過程中還增加了熵懲罰:
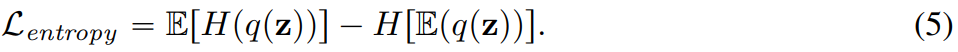
視覺 tokenizer 模型的改進
聯合圖像 - 視頻 tokenization。為了構建聯合圖像 - 視頻 tokenizer,需要一種新的設計。本文發現 3D CNN 的性能比空間 transformer 更好。
本文探索了兩種可行的設計方案,如圖 2b 將 C-ViViT 與 MAGVIT 進行結合;圖 2c 使用時間因果 3D 卷積來代替常規 3D CNN。
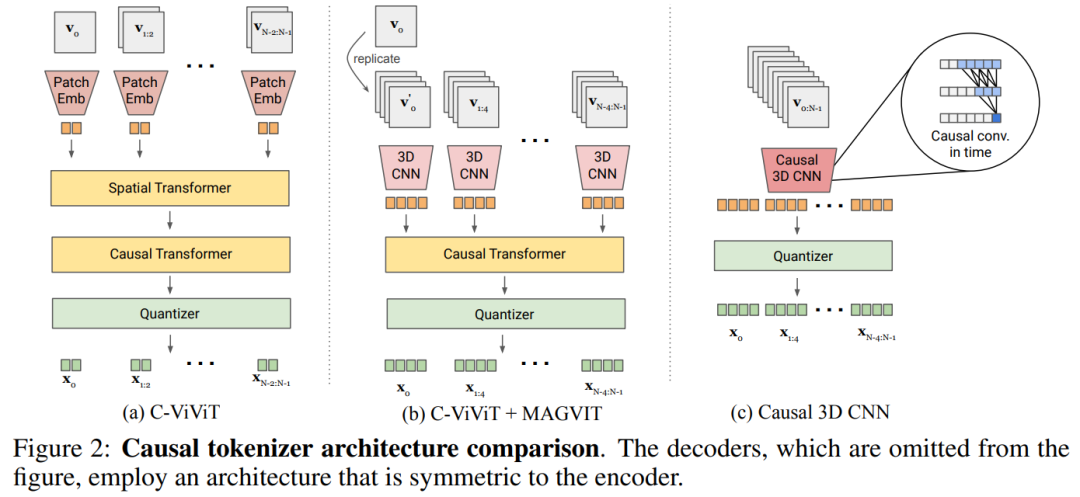
表 5a 對圖 2 中的設計進行了經驗比較,發現因果 3D CNN 表現最好。
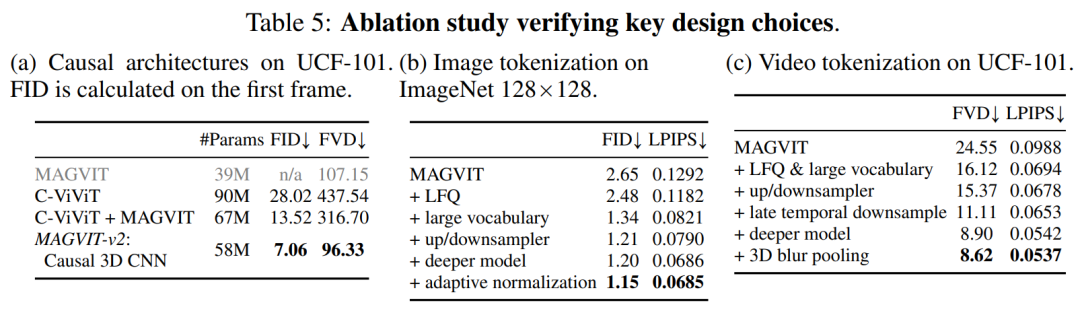
除了使用因果 3D CNN 層之外,本文還進行了其他架構的修改,以提高 MAGVIT 性能,比如本文將編碼器下采樣器從平均池化更改為跨步卷積;又比如在解碼器中每個分辨率的殘差塊之前添加一個自適應組歸一化層等。
實驗結果
實驗從三個部分驗證了本文提出的 tokenizer 的性能:視頻和圖像生成、視頻壓縮,動作識別。圖 3 直觀地比較了 tokenizer 與先前研究的結果對比。

視頻生成。表 1 顯示了本文模型在兩個基準測試中都超越了所有現有技術,證明了良好的視覺 tokenizer 在使 LM 生成高質量視頻方面發揮著重要作用。

圖 4 顯示了模型的定性樣本。

圖像生成。本文在標準 ImageNet 類條件設置下對 MAGVIT-v2 的圖像生成結果進行了評估。結果表明本文模型在采樣質量(ID 和 IS)和推理時間效率(采樣步驟)方面都超過了表現最好的擴散模型。

圖 5 為可視化結果。

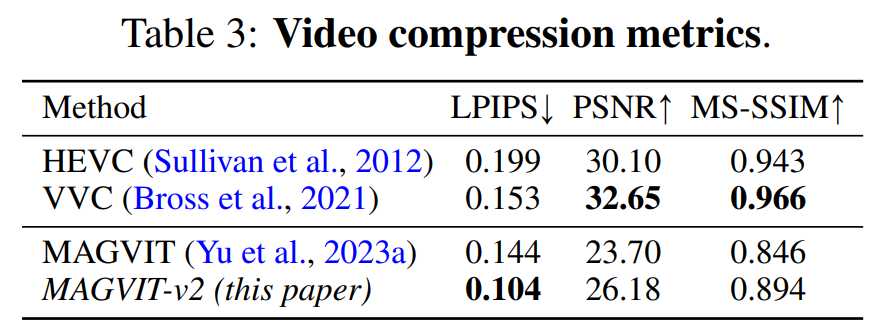
視頻壓縮。結果如表 3 所示,本文模型在所有指標上都優于 MAGVIT,并且在 LPIPS 上優于所有方法。
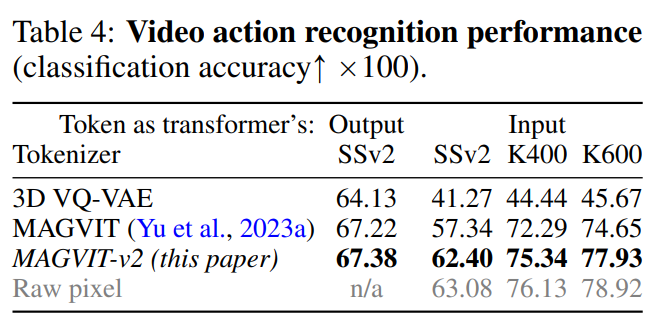
視頻理解。如表 4 所示,MAGVIT-v2 在這些評估中優于之前最好的 MAGVIT。