RAG 結合了大型語言模型和信息檢索模型的力量,允許它們用從大量文本數據中提取的相關事實和細節來補充生成的響應。事實證明,這種方法在提高模型輸出的實際準確性和總體質量方面是有效的。
 圖片
圖片
然而,隨著 RAG 系統得到更廣泛的采用,它們的局限性開始浮出水面,具體而言:
- 平面檢索: RAG 將每個文檔作為一個獨立的信息。想象一下,閱讀單獨的書頁,卻不知道它們之間是如何連接的。這種方法錯過了不同信息片段之間更深層次的關系。
- 語境缺陷: 如果不理解關系和語境,人工智能可能會提供不連貫的反應。這就像有一個圖書管理員,他知道在哪里可以找到書,但是卻不知道書中的故事之間的聯系。
- 可伸縮性問題: 隨著信息量的增長,尋找正確的文檔變得越來越慢,也越來越復雜,就像試圖在不斷擴展的庫中找到一本特定的書一樣。
也就是說,對非結構化文本數據的依賴意味著這些模型很難捕捉到處理復雜查詢所必需的更深層次的語義關系和上下文細微差別。此外,為每個查詢檢索和處理大量文本的計算成本構成了重大挑戰。
1.什么是GraphRAG
GraphRAG 是檢索增強生成領域的一個重要進展。GraphRAG 不使用非結構化的文本,而是利用知識圖譜的力量ーー實體的結構化表示、屬性以及它們之間的關系。通過以這種結構化的格式表達,GraphRAG 可以克服傳統 RAG 方法的局限性。知識圖譜可以更精確和全面地檢索相關信息,使模型能夠產生不僅事實準確而且與上下文相關并涵蓋查詢所需方面的答復。
1.1 GraphRAG中的結構化表達——知識圖譜
讓我們來理解 GraphRAG 如何存儲信息,例如“2型糖尿病是一種擁有屬性高血糖的慢性疾病,可能導致神經損傷、腎臟疾病和心血管疾病等并發癥。”
以下是 GraphRAG 如何在知識圖譜中表示這些信息:
# 實體
二型糖尿病(病況)
高血糖水平(癥狀)
神經損傷(并發癥)
腎臟疾病(并發癥)
心血管疾病(并發癥)
# 關系
2型糖尿病-> 有癥狀-> 高血糖水平
2型糖尿病-> 可導致-> 神經損傷
2型糖尿病-> 可導致-> 腎臟疾病
2型糖尿病-> 可導致-> 心血管疾病在這個知識圖譜中,實體(節點)表示句子中提到的關鍵概念,如病況、癥狀和并發癥。這些關系(邊)捕捉了這些實體之間的聯系,例如,2型糖尿病有高血糖水平的癥狀,并可能導致各種并發癥。這種結構化的表示允許 GraphRAG 理解句子中的語義關系和上下文,而不是僅僅將其視為一個單詞包。當用戶問一個與2型糖尿病相關的問題時,比如“2型糖尿病的并發癥是什么?”,
GraphRAG 可以快速遍歷知識圖,從“2型糖尿病”實體開始,遵循“可以導致”關系來檢索相關并發癥(神經損傷,腎臟疾病和心血管問題)。
1.2 GraphRAG 的主要特性
GraphRAG 已被證明可以顯著提高生成文本的準確性和相關性,使其成為一個有價值的解決方案,用于準確、合理的實時答案。它還因其通過跟蹤圖中的關系鏈來處理復雜查詢的能力而受到關注,提供了對回答問題所需信息的更為豐富的理解。
GraphRAG 的主要特性如下:
- 結構化知識表示: GraphRAG 使用知識圖譜來表示信息、捕獲實體、關系和層次結構。
- 上下文檢索: 知識圖譜使 GraphRAG 能夠理解語義上下文和關系,允許更全面的檢索。
- 高效處理: 在知識圖譜中將數據預處理可以降低計算成本,并且與傳統的 RAG 方法相比,可以更快地檢索。
- 多方面查詢處理: GraphRAG 可以通過綜合來自知識圖譜多個部分的相關信息來處理復雜的多方面查詢。
- 可解釋性: 與大模型的黑盒輸出相比,GraphRAG 中的結構化知識表示提供了更高的透明度和可解釋性。
GraphRAG 的這些關鍵特性展示了它相對于傳統 RAG 模型的優勢,以及它在各種應用中革新檢索增強生成的潛力。
2.GraphRAG 的應用場景
GraphRAG的應用場景非常廣泛。下面簡要介紹 GraphRAG 的兩個用例,以及它們是如何在每個用例中使用的。
2.1 醫療領域
GraphRAG 可以幫助醫學專業人員從大量的醫學文獻中快速找到相關信息,以回答關于患者癥狀、治療和結果的復雜問題。通過將醫學知識表示為一個結構化的知識圖譜,GraphRAG 使得多跳推理能夠連接不同的信息并提供全面的答案。這可以導致更快和更準確的診斷,更知情的治療決定,并改善患者的結果。
2.2 銀行金融業
GraphRAG 可以通過在知識圖譜中表示客戶交易、賬戶信息和行為模式來幫助銀行檢測和防止欺詐。通過分析圖譜中的關系和異常,GraphRAG 可以識別可疑活動,并向銀行的欺詐檢測系統發出警報。這可以導致更快、更準確的欺詐檢測,減少財務損失,提高客戶對銀行安全措施的信任。
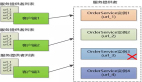
3.GraphRAG的工作原理
GraphRAG 首先從輸入文檔中提取實體和關系,生成知識圖譜,然后通過圖算法檢測社區結構。接下來,使用 LLM 為每個社區生成自然語言摘要,保留分層結構。在用戶查詢時,系統先進行局部檢索匹配高級主題,再進行全局檢索獲取詳細信息,最后由 LLM 生成準確相關的響應。GraphRAG 的局部搜索針對特定上下文提供針對性信息,而全局搜索則利用預先計算的社區摘要,回答跨多個文檔的綜合查詢。
 圖片
圖片
3.1 知識圖譜構建
- 輸入文檔: GraphRAG 將一組文本文檔作為輸入,比如研究論文、新聞文章或產品描述。
- 實體和關系提取: LLM 用于從輸入文檔中自動提取實體(人、地點、概念)以及它們之間的關系。這是使用命名實體識別和關系提取等復雜的自然語言處理技術完成的。
- 知識圖譜生成: 利用提取的實體和關系構造知識圖譜數據結構。在知識圖譜中,實體表示為節點,它們之間的關系表示為邊。
- 分層社區檢測: 采用圖算法檢測知識圖譜中密集連接節點形成的社區。這些社區代表了跨越多個文檔的主題或主題。社區按等級組織,高層次社區包含低層次的子社區。
3.2 知識圖譜的信息摘要
- 社區摘要: 對于知識圖譜中檢測到的每個社區,使用 LLM 生成自然語言摘要。這些摘要描述了每個社區中的關鍵實體、關系和主題。
- 分層摘要: 社區的分層結構保留在摘要中。高級摘要描述寬泛的主題,而低級摘要提供更細粒度的細節。
3.3 檢索增強生成
- 用戶查詢: 用戶向系統提出一個問題或查詢,例如“可再生能源的最新發展是什么?”
- 局部檢索: 首先將查詢與社區摘要進行匹配,以查找最相關的高級主題。這使得系統可以快速縮小搜索空間。
- 全局檢索: 在相關的高級社區中,系統執行更詳細的搜索,以查找回答查詢所需的特定實體、關系和信息。這包括了遍歷知識圖譜和組合來自多個社區的信息。
- 響應生成: 使用檢索到的信息,LLM 生成用戶查詢的最終答案。生成的響應基于來自知識圖譜的結構化知識,確保其事實上的準確性和相關性。
其中,GraphRAG 中的局部搜索是指從特定實體或文本塊的局部上下文中檢索和使用信息。這涉及到使用知識圖譜結構來查找直接連接到當前查詢或上下文的相關實體、關系和文本單元。局部搜索允許系統檢索有針對性的相關信息,以增強語言模型對特定的本地化查詢的響應。
GraphRAG 中的全局搜索是指利用知識圖的更廣泛的層次結構對整個數據集進行推理。這涉及到使用檢測到的“社區”或圖中相關實體和文本單元的集群來生成完整數據集中關鍵主題和主題的摘要和概述。全局搜索使系統能夠回答需要跨多個文檔或實體聚合信息的查詢,例如“文檔中最重要的5個主題是什么?” 通過利用預先計算的社區摘要,全局搜索可以提供全面的響應,而無需為每個查詢從頭開始搜索整個數據集。
4.GraphRAG 的局限
構建全面而精確的知識圖譜不是一個簡單的過程,其質量和覆蓋率嚴重依賴于輸入數據源,隨著知識圖譜的增長,計算資源的需求也會增加,對實時應用構成挑戰。
- 知識圖譜構建復雜性: 構建一個全面而精確的知識圖可能是一個復雜而耗時的過程,需要復雜的實體提取和關系建模技術。
- 依賴于底層數據: 知識圖譜的質量和覆蓋率嚴重依賴于輸入數據源。如果底層數據不完整或有偏差,則會限制 GraphRAG 的有效性。
- 可伸縮性挑戰: 隨著知識圖譜的大小和復雜性的增長,有效的檢索和推理所需的計算資源可能成為一個挑戰,特別是對于實時應用程序。
5.GraphRAG的實現示例
有很多種方法可以實現GraphRAG,例如, 采用微軟開源的GraphRAG 解決方案。為了簡化問題, 這里給出了兩種參考實現的示例。
5.1 基于LLMGraphTransformer 的GraphRAG實現
首先需要 pip 安裝一些必要的庫:
pip install --upgrade --quiet json-repair networkx langchain-core langchain-google-vertexai langchain-experimental langchain-community
#versions used
langchain==0.2.8
langchain-community==0.2.7
langchain-core==0.2.19
langchain-experimental==0.0.62
langchain-google-vertexai==1.0.3當然,可以自己選擇不同的大模型來替換 google 的 verexai。
然后,導入所需的函數,初始化 LLM 對象和引用文本。使用任何 SOTA LLM 獲得最佳結果,因為創建知識圖譜是一項復雜的任務。
import os
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_google_vertexai import VertexAI
import networkx as nx
from langchain.chains import GraphQAChain
from langchain_core.documents import Document
from langchain_community.graphs.networkx_graph import NetworkxEntityGraph
llm = VertexAI(max_output_tokens=4000,model_name='text-bison-32k')
text = """
your content in details.
"""接下來,我們需要將該文本作為 GraphDocument 加載,并創建 LLMTransformer 對象。
documents = [Document(page_cnotallow=text)]
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)創建知識圖譜的時候,最好提供一個要提取的實體和關系列表,否則LLM可能會將所有內容標識為實體或關系。llm_transformer_filtered = LLMGraphTransformer(llm=llm,allowed_nodes=["Person", "Country", "Organization"],allowed_relatinotallow=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],)graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents(documents)
我們可以使用 Networkx Graph 工具包將上面標識的節點和邊進行可視化,當然生產環境中一般會存入圖數據庫。
graph = NetworkxEntityGraph()
# 增加節點
for node in graph_documents_filtered[0].nodes:
graph.add_node(node.id)
# 增加邊
for edge in graph_documents_filtered[0].relationships:
graph._graph.add_edge(
edge.source.id,
edge.target.id,
relatinotallow=edge.type,
)現在,我們可以創建一個 GraphQAChain,它將幫助我們與知識庫進行交互。
chain = GraphQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True
)最后,就可以使用Query 調用 chain 的對象了。question = """my question xxxx"""chain.run(question)
5.2 基于GraphIndexCreator 的GraphRAG實現
在 LangChain 使用 GraphIndexCreator,它與上述方法非常相似。
from langchain.indexes import GraphIndexCreator
from langchain.chains import GraphQAChain
index_creator = GraphIndexCreator(llm=llm)
with open("/home/abel/sample.txt") as f:
all_text = f.read()
text = "\n".join(all_text.split("\n\n"))
graph = index_creator.from_text(text)
chain = GraphQAChain.from_llm(llm, graph=graph, verbose=True)
chain.run("my question xxxx ?")兩種方法都很容易實現。這些示例使用非常小的數據集。如果您使用大型數據集,知識圖譜的創建可能會導致大量token 成本。
5.3 知識圖譜作為檢索工具
特殊地,使用知識圖譜作為 RAG 的檢索部分有三種方法:
- 基于向量的檢索: 向量化知識圖譜并將其存儲在向量數據庫中。然后對提示詞進行向量化,則可以在向量數據庫中找到與提示符最相似的向量。由于這些向量對應于圖中的實體,因此可以在給定自然語言提示詞的情況下返回圖中最“相關”的實體。注意,可以在沒有知識圖譜的情況下進行基于向量的檢索。這實際上是 RAG 最初的實現方式,有時稱為基本RAG。您將向量化 SQL 數據庫或內容,并在查詢時檢索它。
- 提示詞查詢檢索: 使用 LLM 編寫 SPARQL 或 Cypher 查詢,使用對知識圖譜的查詢,然后使用返回的結果來增強提示詞。
- 混合方式(Vector + SPARQL) : 可以以各種有趣的方式組合以上這兩種方法。
總之,有很多方法可以將矢量數據庫和知識圖譜結合起來用于搜索、相似性和 RAG。
6.小結
GraphRAG 代表了檢索增強生成領域的一項重要進步。通過利用知識圖譜的力量,GraphRAG克服了傳統RAG模型的局限性,為復雜查詢提供更準確、相關和全面的響應。
在GraphRAG中,結構化的知識表示使系統能夠理解不同信息片段之間的語義上下文和關系,從而輕松處理復雜的多主題查詢。此外,GraphRAG的高效處理能力使其成為實際應用程序中的實用解決方案,特別是在速度和準確性至關重要的場景中。
GraphRAG已在各個領域被證明是有效的,包括醫療保健和銀行業,能夠提供有價值的見解并支持決策過程。其不斷學習和擴展知識的能力,使其成為一個多功能工具,能夠適應新的信息和不斷變化的領域。