譯者 | 朱先忠
審校 | 重樓
本文將探討基于LangChain框架和云原生向量數據庫Milvus并將密集嵌入與稀疏嵌入結合起來開發混合搜索型AI程序的實戰過程。
簡介
最近,我們——來自IBM研究中心的團隊——需要在Milvus向量存儲中使用混合搜索技術。因為我們已經在使用LangChain框架,所以我們決定一鼓作氣貢獻出在langchain-milvus中啟用這一功能所需的一切。其中包括通過langchain接口支持稀疏嵌入和多向量搜索技術。
在本文中,我們首先簡要介紹密集嵌入和稀疏嵌入之間的區別,然后分析如何使用混合搜索來利用這兩種嵌入技術。然后,我們還將提供關鍵部分的源代碼分析,以演示如何在langchain-milvus中使用這些新功能。
為了使用本文中的代碼,首先應該安裝如下一些軟件包:
pip install langchain_milvus==0.1.6
pip install langchain-huggingface==0.1.0
pip install "pymilvus[model]==2.4.8"然后,進行如下導入:
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_milvus.utils.sparse import BM25SparseEmbedding
from langchain_milvus.vectorstores import Milvus你還可以在鏈接https://gist.github.com/omriel1/3b8ea57cc14b896237c47d5417eaec8f處查看和克隆整個代碼。
接下來,我們正式開始。
密集嵌入
使用向量存儲的最常見方式是使用密集嵌入。在這里,我們使用預先訓練的模型將數據(通常是文本,但也可以是其他媒體,如圖像等)嵌入到高維向量中,并將其存儲在向量數據庫中。向量有幾百(甚至幾千)個維度,每個條目都是浮點數。通常,向量中的所有條目都對應非零值,因此稱為“密集”。給定一個查詢,我們使用相同的模型將其嵌入,向量存儲根據向量相似性檢索相似的相關數據。借助于langchain-milvus這個框架,只需幾行代碼即可實現這一點。讓我們具體看一下這是如何完成的。
首先,我們使用來自HuggingFace的模型定義向量存儲:
dense_embedding = HuggingFaceEmbeddings(model_name=
"sentence-transformers/all-MiniLM-L6-v2")
vector_store = Milvus(
embedding_function=dense_embedding,
connection_args={"uri": "./milvus_dense.db"}, # Using milvus-lite for simplicity
auto_id=True,
)然后,我們將數據插入到向量存儲中:
document = [
"Today was very warm during the day but cold at night",
"In Israel, Hot is a TV provider that broadcasts 7 days a week",
]
vector_store.add_texts(documents)在后臺,每個文檔都使用我們提供的模型嵌入到向量中,并與原始文本一起存儲。
最后,我們可以搜索查詢并打印得到的結果:
query = "What is the weather? is it hot?"
dense_output = vector_store.similarity_search(query=query, k=1)
print(f"Dense embeddings results:\n{dense_output[0].page_content}\n")
# 輸出——密集嵌入的結果如下:
# Today was very warm during the day but cold at night在這里,查詢被嵌入,向量存儲執行(通常是近似的)相似性搜索并返回找到的最接近的內容。
密集嵌入模型經過訓練,可以捕獲數據的語義含義并將其表示在多維空間中。其優勢很明顯——它支持語義搜索;這意味著,結果基于查詢的含義。但是,有時僅僅這些還不夠。譬如,如果你尋找特定的關鍵字,甚至是沒有更廣泛含義的單詞(如名稱),語義搜索就會誤導你,這種方法就會失敗。
稀疏嵌入
在LLM成為現實之前,學習模型還沒有那么流行,搜索引擎使用傳統方法(如TF-IDF算法或其現代增強版的BM25算法——因其在開源分布式搜索引擎Elasticsearch中的使用而聞名)來搜索相關數據。使用這些方法,維度的數量就是詞匯量(通常為數萬,比密集向量空間大得多),每個條目代表關鍵字與文檔的相關性,同時這也考慮到該術語的頻率及其在文檔語料庫中的稀有性。對于每個數據點,大多數條目都是零(表示未出現的單詞),因此稱為“稀疏”。雖然底層實現不同,但使用langchain-milvus接口后,它變得非常相似。讓我們看看它的實際效果:
sparse_embedding = BM25SparseEmbedding(corpus=documents)
vector_store = Milvus(
embedding_function=sparse_embedding,
connection_args={"uri": "./milvus_sparse.db"},
auto_id=True,
)
vector_store.add_texts(documents)
query = "Does Hot cover weather changes during weekends?"
sparse_output = vector_store.similarity_search(query=query, k=1)
print(f"Sparse embeddings results:\n{sparse_output[0].page_content}\n")
#輸出:稀疏嵌入結果:
# In Israel, Hot is a TV provider that broadcast 7 days a weekBM25適用于精確關鍵字匹配,這對于缺乏明確語義含義的術語或名稱非常有用。但是,它不會捕捉查詢的意圖,并且在需要語義理解的許多情況下會產生較差的結果。
【注意】“稀疏嵌入”一詞也指SPLADE或Elastic Elser等高級方法。這些方法也可以與Milvus一起使用,并可以集成到混合搜索中!
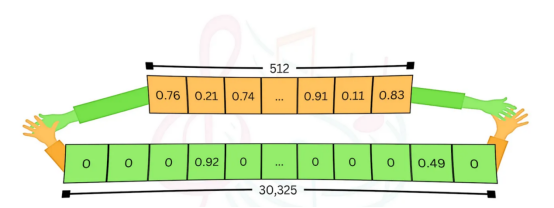
作者本人提供的圖片
混合搜索
如果你在上面兩個示例之間交換查詢,并將每個查詢與另一個嵌入一起使用,則兩者都會產生錯誤的結果。這表明每種方法都有其優點,也有其缺點。混合搜索將兩者結合起來,旨在充分利用兩者的優點。通過使用密集和稀疏嵌入對數據進行索引,我們可以執行同時考慮語義相關性和關鍵字匹配的搜索,并根據自定義權重平衡結果。同樣,內部實現更復雜,但langchain-milvus庫使得這一過程非常容易。讓我們看看它是如何工作的:
vector_store = Milvus(
embedding_function=[
sparse_embedding,
dense_embedding,
],
connection_args={"uri": "./milvus_hybrid.db"},
auto_id=True,
)
vector_store.add_texts(documents)在此設置中,稀疏和密集嵌入均適用。下面,讓我們測試一下具有相等權重的混合搜索:
query = "Does Hot cover weather changes during weekends?"
hybrid_output = vector_store.similarity_search(
query=query,
k=1,
ranker_type="weighted",
ranker_params={"weights": [0.49, 0.51]}, # Combine both results!
)
print(f"Hybrid search results:\n{hybrid_output[0].page_content}")
#輸出:混合搜索結果:
# In Israel, Hot is a TV provider that broadcast 7 days a week這將使用每個嵌入函數搜索相似的結果,為每個分數賦予權重,并返回具有最佳加權分數的結果。我們可以看到,如果對密集嵌入賦予稍微多一點的權重,我們就會得到想要的結果。對于第二個查詢也是如此。
如果我們對密集嵌入賦予更多權重,我們將再次得到不相關的結果,就像單獨使用密集嵌入一樣:
query = "When and where is Hot active?"
hybrid_output = vector_store.similarity_search(
query=query,
k=1,
ranker_type="weighted",
ranker_params={"weights": [0.2, 0.8]}, # Note -> the weights changed
)
print(f"Hybrid search results:\n{hybrid_output[0].page_content}")
# 輸出:混合搜索結果:
# Today was very warm during the day but cold at night在密集和稀疏之間找到適當的平衡并非易事,可以看作是更廣泛的超參數優化問題的一部分。目前正在進行的研究和工具試圖解決該領域的此類問題,例如IBM的AutoAI for RAG。
你可以通過更多方式調整和使用混合搜索方法。例如,如果每個文檔都有一個關聯的標題,則可以使用兩個密集嵌入函數(可能使用不同的模型)——一個用于標題,另一個用于文檔內容——并對兩個索引執行混合搜索。Milvus目前支持多達10個不同的向量字段,為復雜的應用程序提供了靈活性。還有用于索引和重新排名方法的其他配置,你可以查看有關可用參數和選項的Milvus文檔。
結束語
現在,可以通過LangChain訪問Milvus的多向量搜索功能,你可以輕松地將混合搜索集成到自己的應用程序中。這為在你的應用程序中應用不同的搜索策略開辟了新的可能性,從而可以輕松地定制搜索邏輯以適應特定使用場景。對我們來說,這是為開源項目做貢獻的好機會。我們日常使用的許多庫和工具都是開源的,回饋社區是件好事。希望這對其他人有所幫助。
最后,我要大聲感謝Erick Friis和Cheng Zi為langchain-milvus所做的所有努力。沒有他們,這項工作就不可能完成。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Dance Between Dense and Sparse Embeddings: Enabling Hybrid Search in LangChain-Milvus,作者:Omri Levy,Ohad Eytan