













從DeepSeek-V3發布談大模型的技術突破與未來機遇
原創在AI技術日新月異的今天,大型語言模型已成為推動AI發展的重要力量。2024年12月26日,DeepSeek AI正式發布了其最新的大型語言模型——DeepSeek-V3。這款開源模型采用了高達6710億參數的混合專家(MoE)架構,每秒能夠處理60個token,比V2快了3倍。一經發布,就在AI領域引起了軒然大波。
值得注意的是,DeepSeek-V3不僅支持GPU訓練與推理,并且發布即支持昇騰平臺,在昇騰硬件和MindIE推理引擎上實現高效推理,為用戶提供了更多計算硬件的選擇。
與GPT-4o不分伯仲,中國大模型領先全球
DeepSeek-V3是一款擁有6710億總參數和每個令牌激活370億參數的混合專家(Mixture-of-Experts,MoE)語言模型,由人工智能公司DeepSeek發布。它在繼承DeepSeek-V2核心架構的基礎上,進行了多項創新,顯著提升了模型的性能與效率。
DeepSeek-V3采用了創新的知識蒸餾方法,將DeepSeek R1系列模型中的推理能力遷移到標準LLM中,顯著提高了模型的推理性能。
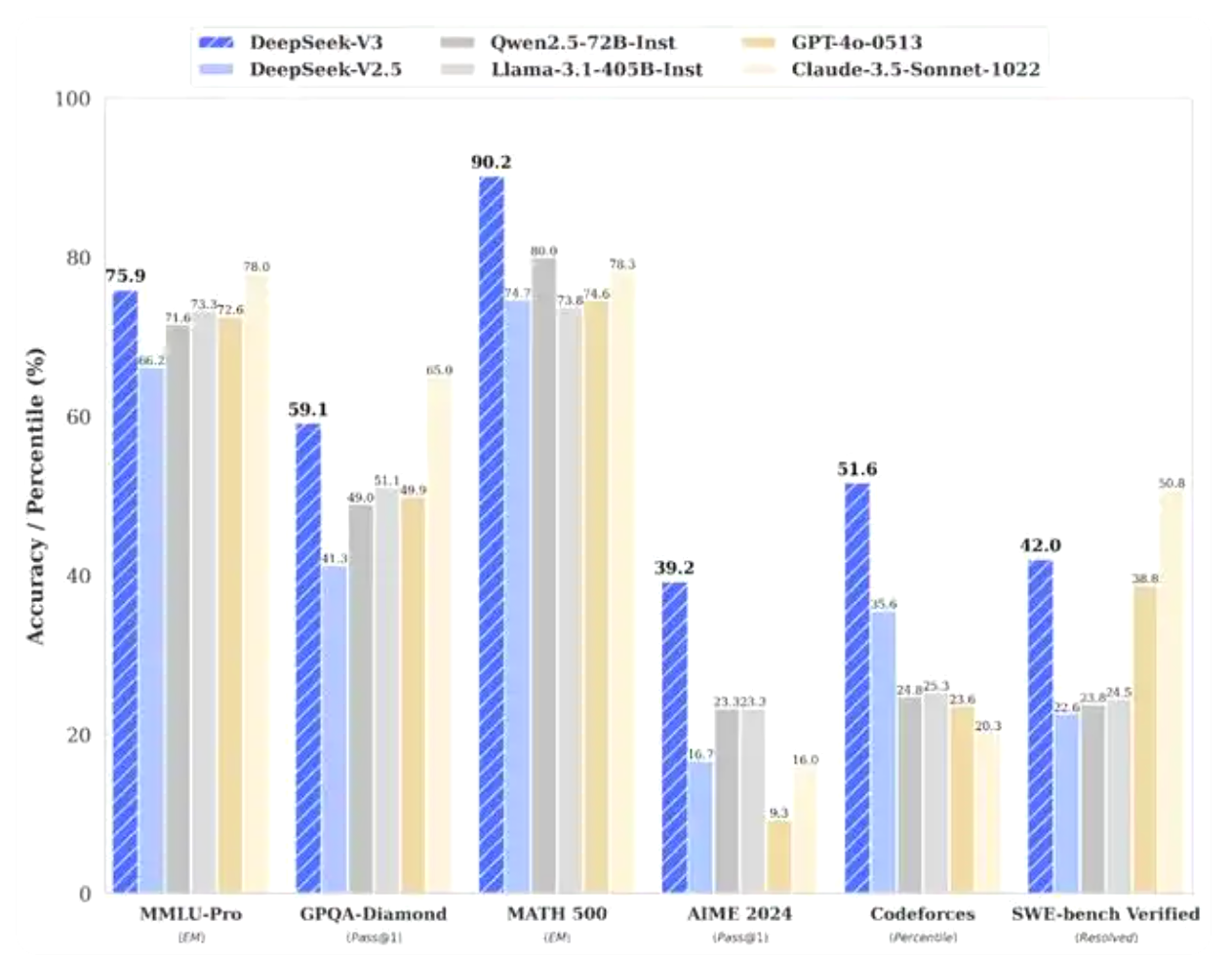
根據DeepSeek公布的測試結果,其運行了多項基準測試來比較性能,V3模型已明顯優于包括Meta公司的Llama-3.1-405B和阿里云的Qwen 2.5-72B等一眾領先開源模型。在大多數基準測試中,它甚至部分超越了OpenAI的閉源模型GPT-4o。
根據DeepSeek公布的資料顯示,V3在知識類任務上的水平相比前代DeepSeek-V2.5顯著提升,接近當前表現最好的模型Anthropic公司于10月發布的Claude-3.5-Sonnet-1022。在美國數學競賽(AIME 2024,MATH)和全國高中數學聯賽(CNMO 2024)上,DeepSeek-V3大幅超過了其他所有開源閉源模型。在生成速度上,DeepSeek-V3的生成吐字速度從20TPS大幅提高至60TPS,相比V2.5模型實現了3倍的提升,能夠帶來更加流暢的使用體驗。
由于DeepSeek-V3模型首次在大規模模型上驗證了FP8訓練的可行性和有效性,通過協同優化有效克服了跨節點MoE訓練中的通信瓶頸,因此使得DeepSeek-V3在保持高性能的同時,實現了訓練成本的極大降低。據DeepSeek官方透露,該模型的訓練成本僅為557.6萬美元,遠低于同類模型的數億美金訓練成本。
作為開源大模型,DeepSeek-V3支持多種開源框架的本地部署,包括SGLang、LMDeploy和TensorRT-LLM,為開發者提供了豐富的選擇。與此同時,DeepSeek-V3還支持更多推理引擎,為用戶提供了更多計算產品的選擇,推動了中國AI產業的創新與發展。
原生支持昇騰AI,為用戶提供更多計算產品選擇
DeepSeek-V3不僅在技術上取得了重大的突破,而且還實現了對更多推理引擎的原生支持。以昇騰平臺為例,DeepSeek-V3發布即支持昇騰平臺,讓用戶能夠在昇騰硬件和MindIE推理引擎上實現高效推理,為國內用戶提供了軟硬件一體化的解決方案。
在魔樂社區上,已經發布了在昇騰硬件和MindIE推理引擎上實現DeepSeek-V3模型的推理的部署方式,用戶可以根據操作手冊,進行服務框架的調優、監控運維、指定NPU卡、在單機上啟動多實例等,優化服務性能和定制運行環境,充分發揮昇騰硬件設備的算力,提升模型推理的效率。(點擊了解詳細部署方式)
作為昇騰針對AI全場景業務的推理引擎,MindIE在通信加速、解碼優化、量化壓縮、最優并行、調度優化等方面展現出了顯著的優勢。
首先,通過高效的RPC(Remote Procedure Call,遠程過程調用)接口,MindIE實現了業務層與推理引擎之間的快速通信。這一接口支持Triton和TGI等主流推理服務框架,使得應用部署更加便捷,能夠在小時級內完成。
 通信加速示意圖
通信加速示意圖
其次,在解碼優化方面,MindIE提供了針對LLM(Large Language Model,大語言模型)和文生圖(SD模型)等特定應用場景的加速參考代碼和預置模型。這些優化措施使得MindIE在解碼階段能夠更快地生成推理結果,提高了整體性能。特別是針對大模型推理,MindIE支持Continuous Batching、PageAttention、FlashDecoding等加速特性,進一步提升了推理效率。
 解碼優化示意圖
解碼優化示意圖
在量化壓縮方面,MindIE中的量化方法基于業界先進的量化技術,如SmoothQuant、AWQ等,這些技術能夠在保持模型精度的同時,顯著減少模型大小和計算量。
 量化壓縮示意圖
量化壓縮示意圖
另外,MindIE提供了最優并行策略,以充分利用多核處理器和GPU等硬件資源。在并行計算方面,MindIE支持Tensor Parallelism(張量并行)等策略,這些策略能夠使得模型在多個處理器核心上并行運行,從而加快推理速度。通過最優并行策略,MindIE能夠在保持模型精度和穩定性的同時,實現更高的推理性能。
 最優并行策略示意圖
最優并行策略示意圖
在調度優化方面,MindIE提供了多并發請求的調度功能,能夠高效地處理大量并發請求。此外,MindIE還支持統一內存池管理KV緩存,這一功能能夠減少內存碎片和訪問延遲,提高內存利用率。在任務調度方面,MindIE基于調度策略實現用戶請求組batch,通過合理的任務分配和調度,使得資源得到充分利用,提高了整體性能。
 調度優化 兩階段混合調度解碼 示意圖
調度優化 兩階段混合調度解碼 示意圖
由于DeepSeek-V3能夠原生支持昇騰硬件和MindIE昇騰推理引擎,使得用戶能夠更加輕松地部署和使用DeepSeek-V3模型,進一步推動了AI技術在各個領域的廣泛應用。
加速AI技術創新發展,中國大模型迎來新機遇
51CTO認為,DeepSeek-v3的成功,不僅展示了中國在AI創新方面的實力,提升了中國大模型在全球科技競爭中的地位,并且降低了大模型的開發門檻,促進了中國AI軟硬件產業的發展,全面推動了AI技術的創新與發展。
首先,DeepSeek-V3充分展示了中國在AI創新方面的實力,提升了中國大模型在全球科技競爭中的地位。隨著DeepSeek-V3的成功,越來越多的國際目光將聚焦到中國AI領域,為中國公司爭取更多的合作機會和市場空間。
其次,DeepSeek-V3的開源策略和API定價策略,降低了AI技術的應用門檻,促進了技術分享和行業內的合作。開源的DeepSeek-V3不僅促進了AI技術的分享與交流,也進一步降低了行業內的應用門檻,為廣大開發者和企業提供了更為經濟實惠的選擇。
此外,DeepSeek-V3的成功也為中國大模型在垂直領域的深耕細作提供了范例。DeepSeek-V3可以應用于智能家居、智能客服、安防、醫療、寫作輔助等多個場景,這為中國大模型在垂直領域的發展提供了廣闊的空間和無限的可能。
最后,DeepSeek-V3由于支持更多推理引擎,有助于構建更加完善的AI生態系統。通過與更多推理引擎的緊密合作,DeepSeek-v3可以更好地適應國內用戶的需求,推動中國AI技術的普及和應用。
總結:
DeepSeek-V3的成功,不僅展示了中國在AI領域的創新實力,更為中國大模型的未來發展帶來了前所未有的新機遇。隨著技術的不斷進步和應用場景的不斷拓展,中國大模型將在全球科技競爭中發揮越來越重要的作用,為人們的生活帶來更多的便利和樂趣。
展望未來,隨著人工智能技術應用場景的不斷擴展,AI行業將迎來更為廣闊的發展空間。DeepSeek-V3的成功只是開端,中國大模型將在技術進步和廣泛應用的推動下,不斷實現新的突破。為此,我們有理由相信,中國大模型在未來的發展中能夠不斷創新和進步,為全球AI技術的未來發展貢獻更多的中國智慧和力量。



















