













PyTorch Geometric框架下圖神經網絡的可解釋性機制:原理、實現與評估
在機器學習領域存在一個普遍的認知誤區,即可解釋性與準確性存在對立關系。這種觀點認為可解釋模型在復雜度上存在固有限制,因此無法達到最優性能水平,神經網絡之所以能夠在各個領域占據主導地位,正是因為其超越了人類可理解的范疇。
其實這種觀點存在根本性的謬誤。研究表明,黑盒模型在高風險決策場景中往往表現出準確性不足的問題[1],[2],[3]。因此模型的不可解釋性應被視為一個需要克服的缺陷,而非獲得高準確性的必要條件。這種缺陷既非必然,也非不可避免,在構建可靠的決策系統時必須得到妥善解決。
解決此問題的關鍵在于可解釋性。可解釋性是指模型具備向人類展示其決策過程的能力[4]。模型需要能夠清晰地展示哪些輸入數據、特征或參數對其預測結果產生了影響,從而實現決策過程的透明化。
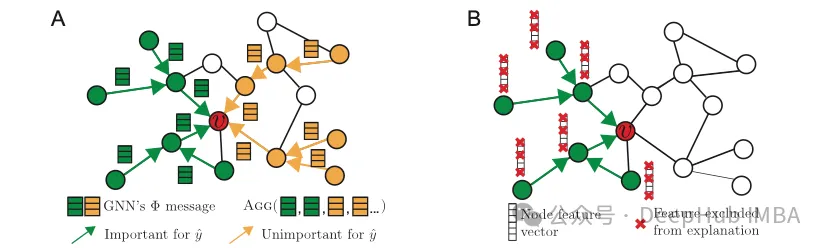
PyTorch Geometric的可解釋性模塊為圖機器學習模型提供了一套完整的可解釋性工具[5]。該模塊具有以下核心功能:
- 關鍵圖特性識別 — 能夠識別并突出顯示對模型預測具有重要影響的節點、邊和特征。
- 圖結構定制與隔離 — 通過特定圖組件的掩碼操作或關注區域的界定,實現針對性的解釋生成。
- 圖特性可視化 — 提供多種可視化方法,包括帶有邊權重透明度的子圖展示和top-k特征重要性條形圖等。
- 評估指標體系 — 提供多維度的定量評估方法,用于衡量解釋的質量。
可解釋性模塊的系統架構圖:
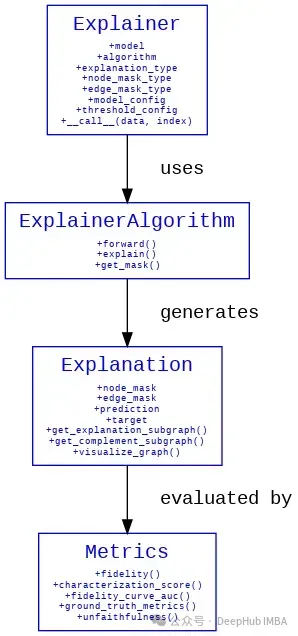
我們下面使用Reddit數據集來進行詳細的描述。
數據集
我們選用Reddit數據集作為實驗數據。該數據集是一個包含不同社區Reddit帖子的標準基準數據集,可通過PyTorch Geometric提供的公開數據集倉庫直接訪問。
Reddit數據集的規模較大,包含232,965個節點、114,615,892條邊,每個節點具有602維特征,共涉及41個分類類別。考慮到數據集規模,我們采用NeighborLoader類實現小批量處理。該類提供了一種高效的采樣機制,可以對大規模圖數據集中的節點及其k-跳鄰域進行小批量采樣。所以設置了三個NeighborLoader實例,分別用于訓練、測試和可解釋性分析。num_neighbors和batch_size參數可根據系統資源情況進行調整。
# 數據集加載與預處理
dataset = Reddit(root="/tmp/Reddit")
data = dataset[0]
train_loader = NeighborLoader(
data,
input_nodes=data.train_mask,
# a=第一層鄰居采樣數量
# b=第二層鄰居采樣數量
num_neighbors=[a, b]
batch_size=batch_size,
shuffle=True
)
test_loader = NeighborLoader(
data,
input_nodes=data.test_mask,
num_neighbors=num_neighbors,
batch_size=batch_size,
shuffle=False # 測試階段保持順序以確保可重復性
)
explain_loader = NeighborLoader(
data,
batch_size=batch_size,
num_neighbors=num_neighbors,
shuffle=True
)GraphSAGE
我們采用GraphSAGE作為基礎模型架構。GraphSAGE是一個專為歸納學習設計的圖神經網絡框架,其特點是能夠將預測能力泛化到未見過的節點。模型的高效鄰居采樣機制使其特別適合處理Reddit這樣的大規模圖數據集。以下代碼展示了模型的核心結構及其訓練、測試方法的實現。
# GNN模型定義
class SAGE(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
self.convs = torch.nn.ModuleList()
# 構建雙層網絡結構
self.convs.append(SAGEConv(in_channels, hidden_channels))
self.convs.append(SAGEConv(hidden_channels, out_channels))
def forward(self, x, edge_index):
for i, conv in enumerate(self.convs):
x = conv(x, edge_index)
if i < len(self.convs) - 1:
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
return x模型訓練實現
# 訓練過程實現
def train(model, loader, optimizer, device, num_train_nodes):
model.train()
total_loss = 0
total_correct = 0
for batch in tqdm(loader, desc="Training"):
# 數據遷移至指定計算設備
batch = batch.to(device)
# 前向傳播計算
optimizer.zero_grad()
out = model(batch.x, batch.edge_index)
# 損失計算與反向傳播
loss = F.cross_entropy(out[batch.train_mask], batch.y[batch.train_mask])
loss.backward()
optimizer.step()
# 計算當前批次訓練節點的預測準確率
pred = out[batch.train_mask].argmax(dim=-1)
total_correct += int((pred == batch.y[batch.train_mask]).sum())
total_loss += loss.item()
return total_loss / len(loader), total_correct / num_train_nodes模型評估實現
# 測試過程實現
def test(model, loader, device):
model.eval()
total_correct = 0
total_test_nodes = 0
for batch in tqdm(loader, desc="Testing"):
batch = batch.to(device)
# 預測計算
with torch.no_grad():
out = model(batch.x, batch.edge_index)
pred = out.argmax(dim=-1)
# 評估測試節點的預測準確率
mask = batch.test_mask
total_correct += int((pred[mask] == batch.y[mask]).sum())
total_test_nodes += mask.sum().item()
# 計算整體測試準確率
accuracy = total_correct / total_test_nodes
return accuracyExplainer模塊配置
要啟用可解釋性分析功能,首先需要完成Explainer的初始化配置。以下是相關參數的詳細說明:
model: torch.nn.Module,
algorithm: ExplainerAlgorithm,
explanation_type: Union[ExplanationType, str],
node_mask_type: Optional[Union[MaskType, str]] = None,
edge_mask_type: Optional[Union[MaskType, str]] = None,
model_config: Union[ModelConfig, Dict[str, Any]],
threshold_config: Optional[ThresholdConfig] = None下面對各參數進行詳細說明:
**model: torch.nn.Module** — 指定需要進行可解釋性分析的PyG模型實例。
**algorithm: ExplainerAlgorithm** — 可選的解釋器算法:
這里主要要使用_GNNExplainer
- DummyExplainer: 用于生成隨機解釋的基準測試器
- GNNExplainer: 基于"GNNExplainer: Generating Explanations for Graph Neural Networks"論文實現[6]
- CaptumExplainer: 集成Captum開源庫的解釋器[7]
- PGExplainer: 基于"Parameterized Explainer for Graph Neural Network"論文實現[8]
- AttentionExplainer: 基于注意力機制的解釋器[9]
- GraphMaskExplainer: 基于Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking論文實現[10]
**explanation_type: Union[ExplanationType, str]** — 解釋類型配置,包含兩種選項:
"model": 針對模型預測機制的解釋
調用Explainer時可通過index參數指定待解釋的節點、邊或圖的索引,實現精確定位分析。
"phenomenon": 針對數據內在特征的解釋
調用時需要通過target參數指定包含所有節點真實標簽的張量。這使得Explainer能夠比對模型預測與真實標簽,從而識別圖中對模型決策過程最具影響力的組件(節點、邊或特征),并評估其與真實數據分布的一致性。
mask_type參數配置
**node_mask_type: Optional[Union[MaskType, str]] = None**
**edge_mask_type: Optional[Union[MaskType, str]] = None**
提供四種掩碼策略:
- None: 不進行掩碼處理
- "object": 整體掩碼策略,每次掩碼一個完整的節點/邊
- "common_attributes": 全局特征掩碼,對所有節點/邊的指定特征進行掩碼
- "attributes": 局部特征掩碼,僅對指定節點/邊的特定特征進行掩碼
**model_config: Union[ModelConfig, Dict[str, Any]]** — 模型配置參數集
主要包括:
1.mode: 預測任務類型配置,可選值包括:'binary_classification'、'multiclass_classification'或'regression'
2.task_level: 預測任務級別,可選值包括:'node'、'edge'或'graph'
3.return_type: 模型輸出格式配置,可選值包括:'probs'、'log_probs'或'raw'
**threshold_config: Optional[ThresholdConfig]** — 閾值控制參數,用于精確控制掩碼應用的范圍和方式。
1.threshold_type: 閾值類型配置,包含以下選項:
- None: 保持原始狀態,保留所有重要性分數
- "hard": 采用固定閾值截斷策略,將低于指定值的重要性分數置零
- "topk": 保留重要性分數最高的k個元素(節點、邊或特征),其余置零
- "topk_hard": 類似于"topk",但將保留元素的重要性分數統一設為1,實現二值化表示
2.value: 閾值參數設置
- 對于threshold_type = "hard",value取值范圍為[0,1]
- 對于threshold_type = "topk"或"topk_hard",value表示保留的元素數量k
閾值參數配置的關鍵考慮:
- k值過小可能導致重要信息丟失
- k值過大可能引入噪聲信息
- 存在性能指標發生突變的臨界閾值
- 最優閾值的確定通常需要針對具體應用場景進行實驗驗證
Explainer調用實現
Explainer的調用需要配置以下參數:
x: Union[Tensor, Dict[str, Tensor]],
edge_index: Union[Tensor, Dict[Tuple[str, str, str], Tensor]],
target: Optional[Tensor] = None,
index: Optional[Union[int, Tensor]] = None各參數說明:
- x: 節點特征矩陣(對應data.x或batch.x)
- edge_index: 邊索引張量(對應data.edge_index或batch.edge_index)
- target: 真實標簽張量(對應data.y或batch.y)
- index: 指定待解釋的節點、邊或圖的索引,可以是單個整數、整數張量或None(表示解釋所有輸出)
實例分析
假設模型將索引為x=10的帖子分類到某個特定subreddit,我們可以分析這一預測的依據,確定哪些特征對該預測結果產生了關鍵影響。下面展示如何初始化和調用Explainer來實現這一分析:
index = 143
model_explainer = Explainer(
model=model,
algorithm=GNNExplainer(epochs=50),
explanation_type='model',
node_mask_type='attributes',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
)
threshold_config=dict(threshold_type='topk', value=20)
)說明:
- 選擇explanation_type='model'用于分析模型的預測機制
- 設置node_mask_type='attributes'以研究特征重要性,同時保持node_edge_type=None以專注于節點分析
- model_config配置反映了數據集特點:41個類別的多分類問題(mode = 'multiclass_classification'),節點級預測任務(task_level = 'node'),使用對數概率輸出(return_type = 'log_probs')
- threshold_config設置為保留最重要的20個節點(threshold_type='topk', value=20)
執行分析:
model_explanation = model_explainer(
batch.x,
batch.edge_index,
index=index
)由于設置了explanation_type = 'model',此處無需指定target參數,執行完成后返回Explanation對象,包含完整的解釋結果
Explanation類封裝了可解釋性模塊產生的關鍵分析信息[11]。其結構設計如下:
x: Optional[Tensor] = None,
edge_index: Optional[Tensor] = None,
edge_attr: Optional[Tensor] = None,
y: Optional[Union[Tensor, int, float]] = None,
pos: Optional[Tensor] = None,
time: Optional[Tensor] = None核心屬性說明:
- x: 節點特征矩陣,維度為[num_nodes, num_features]
- edge_index: 邊索引矩陣,維度為[2, num_edges]
- edge_attr: 邊特征矩陣,維度為[num_edges, num_edge_features]
- y: 真實標簽,可以是回歸問題的目標值或分類問題的類別標簽
- pos: 節點空間坐標矩陣,維度為[num_nodes, num_dimension]
- time: 時序信息張量,格式根據具體時間特征定義(如,time = [2022, 2023, 2024]表示節點0-2的時間戳)
解釋結果分析方法
預測行為分析
以下代碼用于獲取模型的初始預測結果:
model.eval()
with torch.no_grad():
predictions = model_explainer.get_prediction(batch.x, batch.edge_index)要分析特定圖屬性掩碼對預測的影響,可使用get_masked_prediction方法。例如,分析掩碼節點5對預測的影響:
# 構建掩碼矩陣
node_mask = torch.ones_like(batch.x)
node_mask[5] = 0 # 對節點5進行掩碼處理
with torch.no_grad():
masked_predictions = model_explainer.get_masked_prediction(batch.x, batch.edge_index, node_mask=node_mask)進行預測差異分析:
difference = predictions - masked_predictions
mean_difference = difference.mean(dim=0).cpu().numpy()
plt.figure(figsize=(10, 6))
plt.plot(mean_difference, color="olive", label="Mean Difference")
plt.title('原始預測與掩碼預測的差異分析')
plt.xlabel('類別')
plt.ylabel('Logits差異均值')
plt.legend()
plt.show()
該圖展示了節點5掩碼對各類別預測logits的平均影響。正值表示掩碼導致該類別的預測概率增加,負值則表示減少。這種可視化有助于理解特定節點對模型決策的影響程度和方向。
除了均值分析,還可以采用其他評估指標,如:
- 絕對差異
- 相對差異
- 均方誤差(MSE)
- 自定義評估指標
關鍵子圖提取
為了深入分析圖結構中的重要組件,可以使用以下方法:
get_explanation_subgraph():提取對解釋具有非零重要性的節點和邊,返回一個新的Explanation對象。這有助于隔離對預測最具影響力的圖結構組件。
get_complement_subgraph():提取重要性為零的節點和邊,返回一個新的Explanation對象。這有助于理解模型認為不重要的圖結構部分。
這些方法的主要價值在于能夠分離和聚焦于感興趣的圖結構組件,尤其是get_explanation_subgraph()可以有效降低來自無關節點和邊的干擾。
關鍵特征提取
以下代碼展示了如何提取影響節點預測的關鍵特征。這段代碼改編自visualize_feature_importance方法
node_mask = model_explanation.get('node_mask')
if node_mask is None:
raise ValueError(f"The attribute 'node_mask' is not available "
f"in '{model_explanation.__class__.__name__}' "
f"(got {model_explanation.available_explanations})")
if node_mask.dim() != 2 or node_mask.size(1) <= 1:
raise ValueError(f"Cannot compute feature importance for "
f"object-level 'node_mask' "
f"(got shape {node_mask.size()})")
score = node_mask.sum(dim=0)
non_zero_indices = torch.nonzero(score, as_tuple=True)[0]
non_zero_scores = score[non_zero_indices]
# 特征重要性排序
sorted_indices = non_zero_indices[torch.argsort(non_zero_scores, descending=True)]
print(sorted_indices)輸出示例:
tensor([555, 474, 43, 210, 446, 158, 516, 273, 417, 531], device='cuda:0')該實現的關鍵步驟:
- 計算每個特征在所有節點上的累積重要性
- 篩選出具有非零重要性的特征
- 特征列表的長度由Explainer初始化時的ThresholdConfig決定(示例中為10,因為設置了threshold_config = dict(threshold_type='topk', value=10))
解釋結果可視化
圖結構可視化
visualize_graph方法用于直觀展示對模型預測有影響的節點和邊。該方法的一個重要特性是通過邊的不透明度表示其重要性(不透明度越高表示重要性越大)。需要注意的是,使用此方法時Explainer不能設置edge_mask_type=None
方法定義:
visualize_graph(path: Optional[str] = None,
backend: Optional[str] = None,
node_labels: Optional[List[str]] = None)參數說明:
- path: 可視化結果保存路徑
- backend: 可視化后端選擇,支持graphviz或networkx
- node_label: 節點標識符列表
下面通過兩個示例展示不同配置下的可視化效果:
示例1:基礎特征屬性分析
配置:node_mask_type='attributes',不設置閾值
visual_explainer_1 = Explainer(
model=model,
algorithm=GNNExplainer(epochs=50),
explanation_type='model',
node_mask_type='attributes',
edge_mask_type='object',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
)
)
index = 143
visual_explanation_1 = visual_explainer_1(
batch.x,
batch.edge_index,
index=index
)生成可視化結果:
visual_explanation_1.visualize_graph('visual_graph_1.png', backend="graphviz")
可視化結果展示了與節點143相連的所有節點,這些節點的特征都對節點143的預測產生了影響。圖中邊的不透明度差異反映了不同連接對預測結果的影響程度。由于未設置閾值,可視化結果包含了較多的節點和邊,這有助于全面理解模型的決策過程,但可能不夠聚焦。
示例2:重要性篩選分析
配置:node_mask_type='attributes',threshold_cnotallow=dict(threshold_type='topk', value=10),edge_mask_type=None
本示例通過設置閾值來篩選最重要的節點,提供更聚焦的分析視圖:
visual_explainer_2 = Explainer(
model=model,
algorithm=GNNExplainer(epochs=50),
explanation_type='model',
node_mask_type='attributes',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
),
threshold_config=dict(threshold_type='topk', value=10)
)
index = 143
visual_explanation_2 = visual_explainer_2(
batch.x,
batch.edge_index,
index=index
)
# 生成可視化結果
visual_explanation_2.visualize_graph('visual_graph_2.png', backend="graphviz")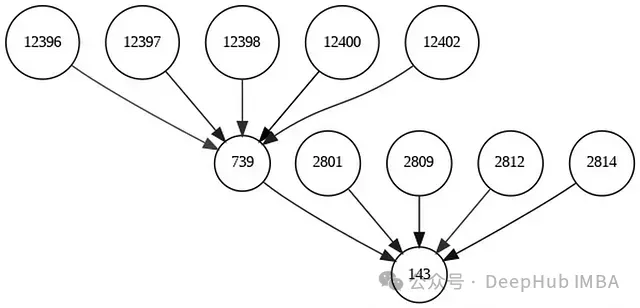
第二種可視化方法通過限制顯示最重要的10個節點,提供了更加精煉的分析視圖。邊的不透明度變化不太明顯,這說明這些保留下來的邊對預測結果具有相近的影響程度。這種篩選后的可視化更適合用于識別和分析關鍵影響因素。
特征重要性可視化
visualize_feature_importance方法提供了另一種可視化視角,用于展示影響節點預測的top-k重要特征。使用此方法時,Explainer的初始化配置中不能設置node_mask_type=None,詳細實現可參考方法的源代碼。
方法定義:
visualize_feature_importance(path: Optional[str] = None,
feat_labels: Optional[List[str]] = None,
top_k: Optional[int] = None)[source])參數說明:
- path: 可視化結果保存路徑
- feat_labels: 特征標簽列表,用于增強可讀性
- top_k: 顯示的重要特征數量示例調用:
model_explanation.visualize_feature_importance(top_k=10)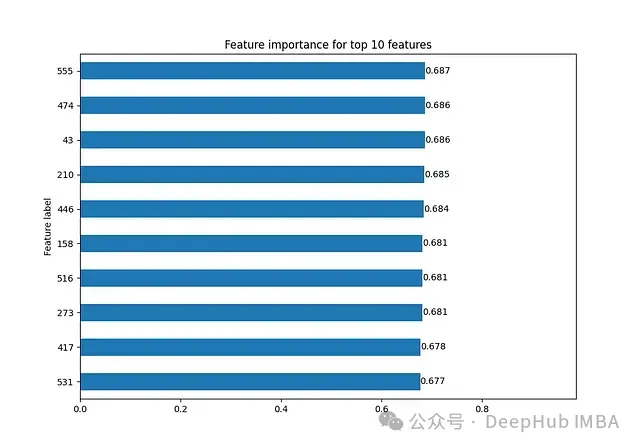
該圖顯示了對節點143預測結果影響最大的前10個特征。這些特征與我們之前通過分析得到的影響特征列表完全一致,提供了直觀的重要性排序視圖。
解釋質量評估
為了區分高質量解釋和低質量解釋,需要建立一套系統的評估機制。這一評估機制對于判斷不同解釋器(如DummyExplainer與專業解釋器)的性能差異尤為重要。系統提供了五種評估指標[12]:
基于真實標簽的評估
groundtruth_metrics用于評估生成的解釋掩碼與真實解釋掩碼之間的一致性。這個指標有助于判斷模型識別的重要特征是否與實際數據中的關鍵特征相符。
- 評估模型解釋與數據真實重要性特征的匹配程度
- 驗證模型的解釋能力是否符合領域知識
- 識別潛在的誤解釋情況
準確性評估
fidelity指標通過比較兩種場景下的預測差異來評估解釋的質量:
Fid+(保留重要特征):
- 僅保留解釋認定的重要部分
- 評估這些部分是否足以重現原始預測
Fid-(移除重要特征):
- 移除解釋認定的重要部分
- 評估這些部分的缺失是否會顯著改變預測結果
評估標準:
- 高質量解釋應具有高Fid+值,表明保留的重要特征能夠很好地支持原始預測
- 同時應具有低Fid-值,表明移除這些特征會導致預測結果發生顯著變化
綜合特征化評分
characterization_score將Fid+和Fid-兩個指標整合為單一評分,提供更全面的評估視角:
- Fid+:評估保留重要特征的效果(目標值接近1)
- Fid-:評估移除重要特征的影響(目標值接近0)
- 權重配置:默認兩者權重相等(各0.5),可根據具體應用場景調整
準確性曲線分析
fidelity_curve_auc提供了一個更加動態的評估視角,通過測量不同閾值下解釋質量的變化來生成完整的性能曲線:
評估機制:
- 通過調整重要特征的閾值進行多次準確性測量
- 計算測量結果的曲線下面積(AUC)
- 分析解釋質量隨特征數量變化的穩定性
結果解讀:
- AUC = 1:解釋在所有閾值下均保持高準確性
- AUC = 0:解釋在所有閾值下均表現不佳
- AUC值越高表明解釋的穩健性越好
相比特征化評分,曲線分析的優勢在于能夠提供全范圍閾值下的性能表現,而不是僅關注特定點的表現。
示例:
from torch_geometric.explain.metric import (
fidelity,
characterization_score,
fidelity_curve_auc,
unfaithfulness
)
# 驗證解釋結果
is_valid = model_explanation.validate()
# 計算準確性指標
fid_pos, fid_neg = fidelity(
explainer=metric_explainer,
explanation=metric_explanation
)
# 計算特征化評分
char_score = characterization_score(
fid_pos,
fid_neg,
pos_weight=0.7, # 提高正向影響的權重
neg_weight=0.3 # 降低負向影響的權重
)
# 準確性曲線AUC計算
pos_fidelity = torch.tensor([0.9, 0.8, 0.7, 0.6, 0.5])
neg_fidelity = torch.tensor([0.1, 0.2, 0.3, 0.4, 0.5])
# 定義評估閾值點
x = torch.tensor([0.1, 0.2, 0.3, 0.4, 0.5])
# 計算AUC
auc = fidelity_curve_auc(pos_fidelity, neg_fidelity, x)
# 輸出評估結果
print(f"準確性指標: {fid_pos}, {fid_neg}")
print(f"特征化評分: {char_score}")
print("準確性曲線AUC:", auc.item())總結
圖神經網絡的可解釋性研究對于提升模型的可信度和實用價值具有重要意義。通過PyTorch Geometric的可解釋性模塊,我們實現了對復雜模型決策過程的系統分析和理解。




























