













超越思維鏈?深度循環隱式推理引爆AI圈,LLM擴展有了新維度
這是一種全新的語言模型架構,能夠通過使用循環語言模型在潛在空間中隱式推理,顯著提升模型的計算效率,尤其是在需要復雜推理的任務上。
近日,馬里蘭大學的一篇論文在 AI 研究社區中引發了關注,其提出的語言模型通過迭代循環塊來工作,能在測試時展開到任意深度。這與當前通過生成更多 token 來擴展計算的主流推理模型形成了鮮明的對比。
僅在上個月,Hugging Face 上的下載量就達到了 4500+。
深度循環(Recurrent Depth)方法無需生成大量「思考」token 即可獲得高性能。與基于思維鏈的方法不同,馬里蘭大學的方法不需要任何專門的訓練數據,可以使用小的上下文窗口,并且可以捕獲不易用文字表示的推理類型。
該工作構建的概念驗證模型達到 35 億參數和 8000 億 token,實驗驗證了新方法可以提高其在推理基準上的性能,尤其是在需要復雜推理的數學和編程問題上,最高相當于 500 億參數的計算負載。

- 論文鏈接:https://arxiv.org/abs/2502.05171
- 模型下載: https://huggingface.co/tomg-group-umd/huginn-0125
- 代碼鏈接: https://github.com/seal-rg/recurrent-pretraining
人類在解決某些問題時自然會花費更多的腦力。雖然人類能夠通過用語言表達中間結果并寫下來進行長時間的思考,但在說出答案的第一個字之前,大量的思考是通過大腦中復雜、反復的放電模式進行的。
而在 AI 一側,早期提升語言模型能力的嘗試聚焦于擴大模型規模,這種方法需要海量數據和算力支撐。近年來,研究者開始探索通過擴展測試時計算量來提升模型推理能力。主流方法是對長鏈條的思維鏈示例進行后訓練,以開發模型在上下文窗口中語言化中間計算過程的能力,從而實現思維外顯。
然而,將昂貴的內部推理過程始終壓縮為單一的語言化下一個 token 的約束顯然是低效的 —— 如果模型能原生地在連續的潛在空間中「思考」,其能力很可能得到顯著提升。釋放這一未被開發的計算維度的一種方法是為模型添加循環單元。該單元以循環方式運行,持續處理和更新隱藏狀態,使得計算得以無限延續。盡管這并非當前主流范式,但這一思想貫穿機器學習發展史,每隔十年便以新形式重現:從循環神經網絡(RNN)到擴散模型(Diffusion model),再到通用 Transformer 或循環 Transformer 架構。
在新工作中,研究人員展示了深度循環語言模型(depth-recurrent language models)可以有效學習、高效訓練,并在測試時計算擴展的情況下展示出明顯的性能改進。作者提出的 Transformer 架構建立在潛在深度循環塊之上,在訓練期間運行隨機采樣的迭代次數。作者展示了這種范式可以擴展到數十億個參數和超過 5 萬億個預訓練數據標記。在測試時,該模型可以通過潛在空間中的循環推理來提高其性能,使其能夠與其他受益于更多參數和訓練數據的開源模型競爭。
此外,作者展示了循環深度模型在推理時自然支持許多功能,這些功能在非循環模型中需要大量的調整和研究工作,例如每個 token 的自適應計算、(自)推測解碼和 KV 緩存共享。通過跟蹤潛在空間中的 token 軌跡來表明,許多有趣的計算行為會隨著規模的擴大而出現,例如模型在潛在空間中旋轉形狀以進行數值計算。
為什么要使用深度循環來訓練模型?
循環層使得 Transformer 模型能夠在生成一個 token 之前執行任意數量的計算。從原理上講,循環機制為測試時計算量的擴展提供了一種簡潔的解決方案。作者認為,與更傳統的長上下文推理方法(如 OpenAI 的 o1、DeepSeek-AI 的 R1)相比,潛在循環思考具備多項優勢:
- 無需定制化訓練數據:鏈式思維推理要求模型在特定領域的長示例上進行訓練。而潛在推理模型則能在標準訓練數據上訓練,無需專門示例,且可根據計算預算靈活調整,在測試時通過額外計算資源增強能力;
- 更低的內存需求:潛在推理模型在訓練和推理時所需內存少于鏈式思維推理模型。后者因需極長上下文窗口,可能需采用如 token 并行化等專門訓練方法;
- 更高的計算效率:循環深度網絡相較于標準 Transformer,每參數執行的浮點運算(FLOPs)更多,顯著降低了大規模訓練時 AI 計算卡之間的通信成本,尤其在低速互連條件下更能提升設備利用率;
- 促進「思考」而非記憶:通過構建計算密集但參數規模較小的架構,該工作期望強化模型構建「思考」(即學習元策略、邏輯與抽象)而非單純記憶來解決問題的先驗傾向。此前,循環先驗在學習復雜算法方面的優勢已在「深度思考」相關文獻中得到驗證。
從哲學視角看,我們肯定希望 AI 的潛在推理能捕捉人類推理中難以言表的部分,如空間思維、物理直覺或(運動)規劃。通過循環過程的多次迭代,在高維向量空間中進行推理將允許同時深度探索多個方向,而非線性思維,從而催生能夠展現新穎且復雜推理行為的系統。
以這種方式擴展計算能力并不排斥通過延長(語言化)推理或增加預訓練參數數量來提升模型性能。因此,它可能構建出模型性能擴展的第三維度。
可擴展的循環架構
該研究提出的具有潛在循環深度的 Transformer 架構,模型主體結構基于僅解碼器(decoder-only)的 Transformer 模塊。然而,這些模塊被組織成三個功能組:前奏(Prelude)P,通過多層 Transformer 將輸入數據嵌入潛在空間;核心循環塊(Core Recurrent Block)R,作為循環計算的核心單元,負責修改狀態 s ∈ R n×h;以及尾聲(Coda)C,通過若干層從潛在空間解嵌入,并包含模型的預測頭。
核心塊置于前奏與尾聲之間,通過循環核心塊,我們能在「歌曲」中插入無限數量的「詩節」。
模型架構如下圖所示:
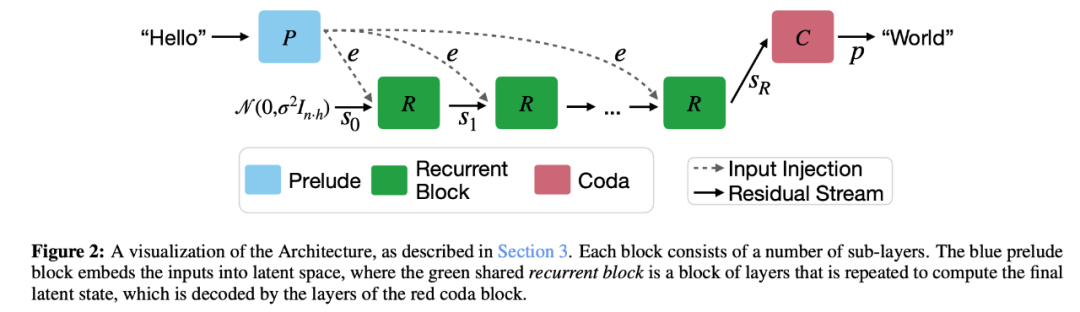
給定一定數量的循環迭代 r 和一系列輸入標記 x ∈ V n,這些組以以下方式使用來產生輸出概率 p ∈ R n×|V |:
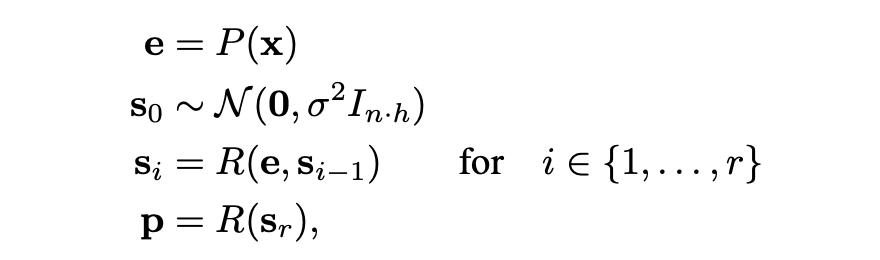
其中 σ 是初始化隨機狀態的某個標準差。該過程如圖 2 所示。給定一個初始隨機狀態 s0,模型重復應用核心塊 R,它接受潛狀態 si?1 和嵌入輸入 e 并輸出一個新的潛在狀態 si 。完成所有迭代后,coda 塊處理最后一個狀態并產生下一個 token 的概率。該架構基于深度思考文獻,其中表明在每一步中注入潛在輸入 e 并用隨機狀態初始化潛在向量可以穩定遞歸并促進收斂到與初始化無關的穩定狀態,即路徑獨立性。
在每個組中,模型大致都遵循標準的 Transformer 層設計。每個塊包含多個層,每個層包含一個標準的因果自注意力塊,使用 RoPE,基數為 50000,以及一個門控 SiLU MLP。作者使用 RMNSorm 作為規范化函數。為了穩定遞歸,模型按以下「三明治」格式對所有層進行排序,使用范數層 ni:

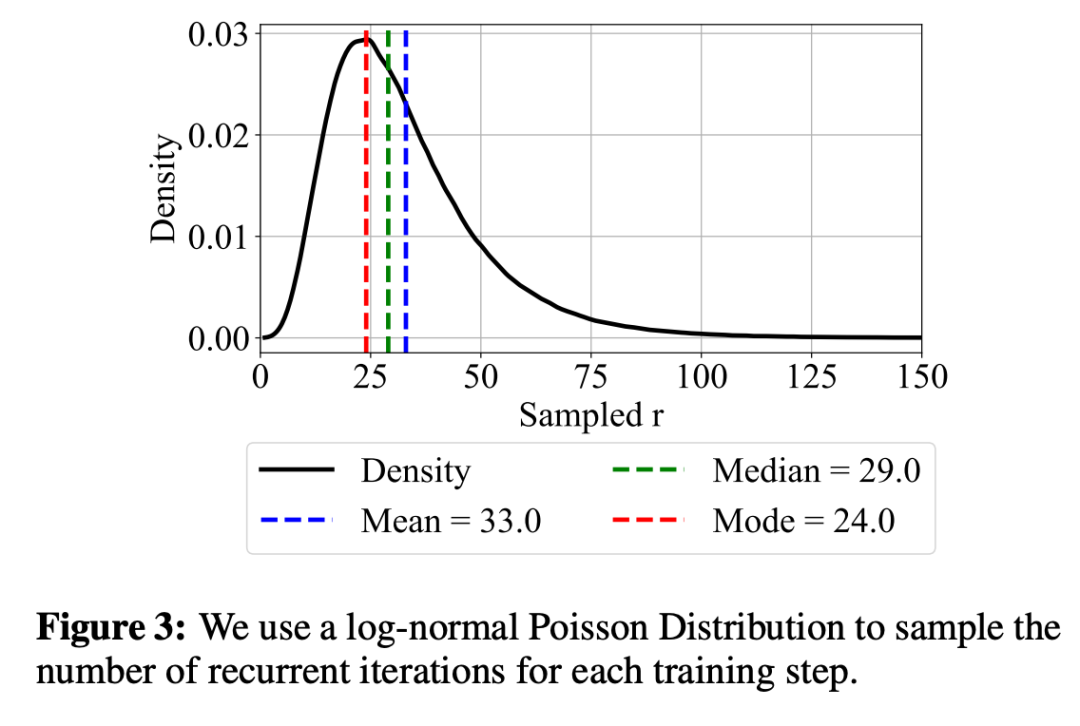
為了在訓練時保持較低的計算量和內存,研究人員在訓練時隨機采樣迭代次數,并通過截斷反向傳播來減少計算和內存開銷。模型只對最后幾次迭代進行反向傳播,在保持訓練效率的同時能夠適應不同深度的循環計算。
實驗結果
由于這個模型很難與其他基于 Transformer 架構大語言模型直接比較。它僅包含 3.5B 參數,在預訓練階段僅需少量互連帶寬。然而,其實際算力(FLOPs)消耗要接近 32B 參數 Transformer 的水平。在測試中,該模型能夠無限制地提升算力,最終達到與 50BTransformer 相當的性能水平。
該模型的訓練有一些瑕疵:只訓練了 47000 步,學習率從未降低,數據集也比較小,只有 800B tokens。這和現在動輒上萬億 tokens 的工業模型有很大差距。
盡管如此,它在 ARC、HellaSwag、MMLU、OpenBookQA、PiQA、SciQ 和 WinoGrande 的成績上已經可以和 OLMo-7B 媲美,在多項任務上超過了老牌的 Pythia 模型。
作為首個在這個量級上訓練的「深度循環」模型,這個結果已經可喜可賀了。這也證明了「潛在循環」是一個可行的思路,值得探索。在推理時動態地增加算力,也有希望達到上億 token 級別的水平。
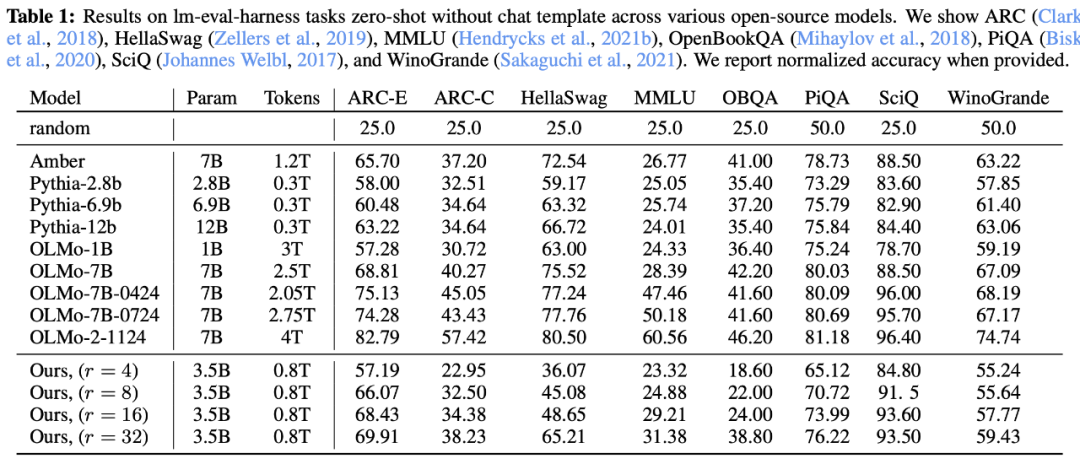

數學和代碼測試
該團隊在 GSM8k、MATH、Minerva 和 MathQA 上測試了模型的數學能力;在 MBPP 和 HumanEval 上測試了編程水平。
在數學推理方面,該模型大大超過了除 OLMo-2 模型以外的所有模型。在編程基準測試中,該模型擊敗了所有其他通用開源模型。不過沒有 StarCoder2 等「編程專家模型」。
研究團隊還注意到,如下圖所示,雖然語言建模的進步會放緩,在這個訓練規模下是正常的,但編程和數學推理在整個訓練過程中都處于穩步上升的狀態。
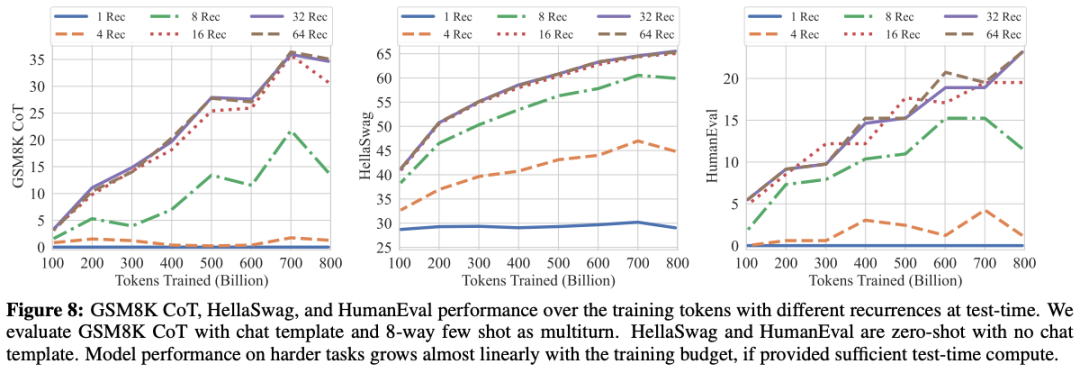
遞歸在哪里起效了?
遞歸到底在哪方面帶來了提升?模型表現的提升到底是遞歸結構的功勞,還是數據集、分詞方式、模型架構等其他因素在起作用?
為了找到答案,研究團隊做了對比實驗:他們用完全相同的條件訓練了一個非遞歸模型,讓兩個模型都學習了 1800 億個 token。
結果顯示,遞歸模型的整體表現更勝一籌,尤其是在處理難度較大的任務時尤為明顯,比如 ARC 挑戰測試集。不過,像 SciQ 這樣主要考驗科學知識記憶的基礎任務上,兩個模型的差距就不那么大了。而在 GSM8k 數學推理任務上,才訓練到 1800 億 token,遞歸模型的成績就已經比基準模型好了整整 5 倍!
如果限制遞歸模型只能遞歸一次,它從 1800 億到 8000 億 token 期間的表現就幾乎沒有進步。這說明模型的提升完全來自于遞歸模塊的多次運算,而非前后的非遞歸層。
此外,研究團隊還做了一個測試,看看在不同任務上增加計算量會帶來什么效果。結果顯示,簡單任務很快就能達到性能上限,而復雜任務則能從更多的計算中持續獲益。
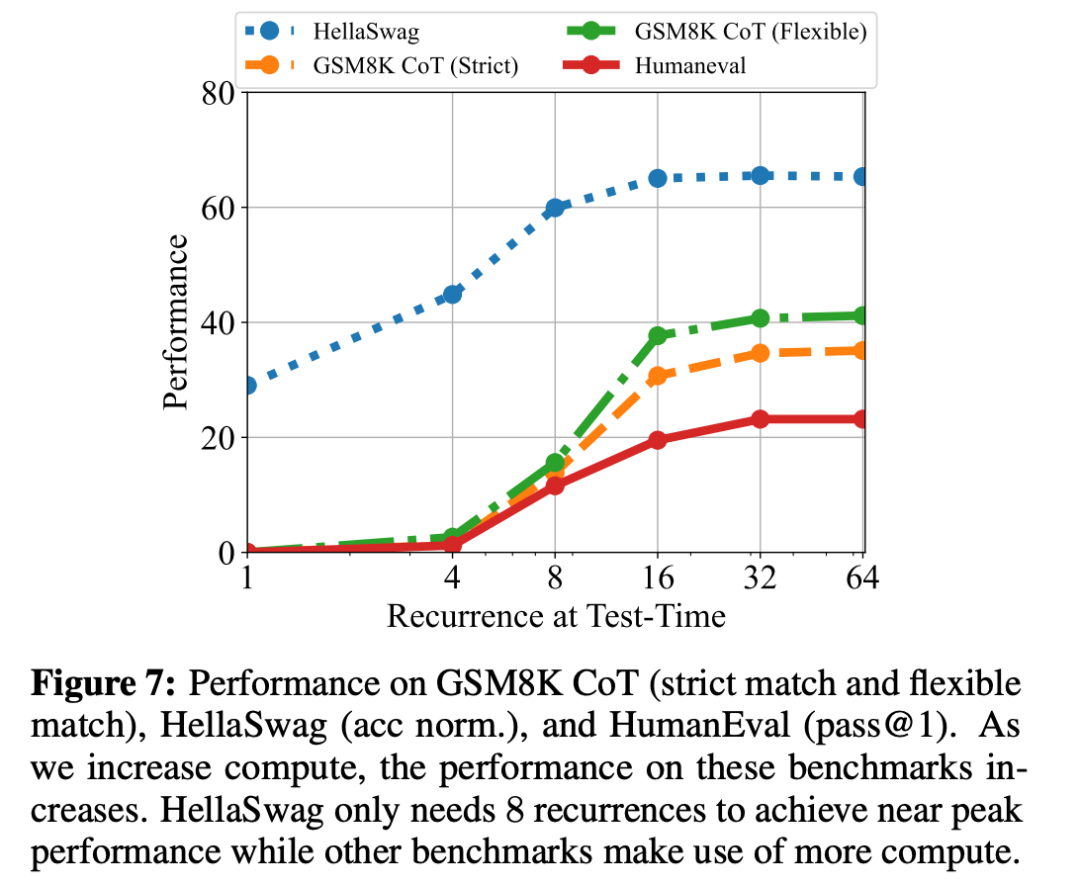
遞歸次數和上下文長度的關系
下圖展示了模型在 ARC-C 測試中的表現如何隨著遞歸次數和少樣本示例數量的變化而變化,當上下文中沒有少樣本示例時,模型僅需 8 到 12 次遞歸即可達到性能上限。
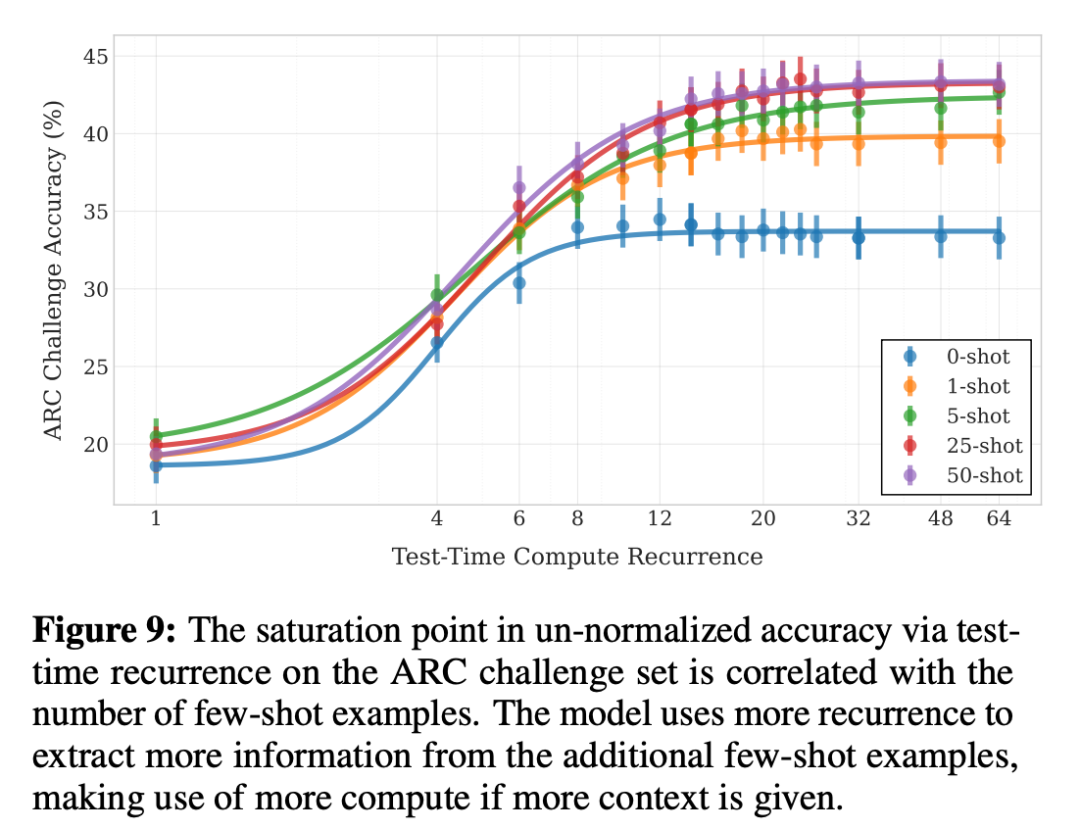
但是,當給模型提供更多上下文信息時,它就像得到了更大的「思考空間」。比如提供 1 個示例時,模型需要 20 次遞歸才能發揮最佳水平;如果給到 25-50 個示例,則需要 32 次遞歸。
OBQA 測試也出現了同樣的情況。當研究團隊為每道題提供相關背景知識時,遞歸模型的表現突飛猛進,幾乎追平了 OLMo-2 的水平。這個結果其實很好理解:遞歸模型雖然不太擅長記憶大量事實,但在推理和利用上下文信息方面卻相當出色。
遞歸深度如何簡化 LLM?
測試階段的零樣本自適應計算
該團隊發現,其模型能夠根據不同的任務靈活調整計算量。
對于簡單問題,模型只需進行較少的計算;而對于復雜問題,則會增加計算輪次。這不正是我們期望的效果嗎?
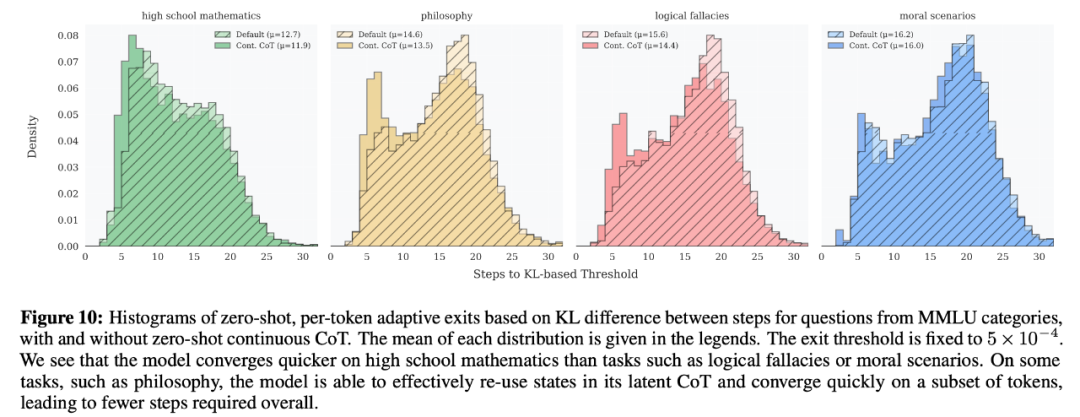
為了量化觀察,他們采用了一個簡單的判斷標準:觀察連續兩步計算結果之間的 KL 散度。如果這個差異小于 0.00005,便判斷為可以停止計算了。
如圖 10 所示,在處理 MMLU 測試的前 50 個問題時,不同類型的題目所需的計算步數差異很大。例如,高中數學題相對簡單,計算步數較少;面對需要道德判斷題時,平均需要多算 3.5 步。而在 MTBench 測試中,這種自適應計算機制幾乎不會影響模型的對話表現。
零樣本 KV 緩存共享
為了提高效率,研究團隊還嘗試減少了 KV 緩存的內存占用。他們給每個 token 設定了固定的 KV 緩存預算,比如 16 步。這樣,第 17 步的計算就會覆蓋第 1 步的緩存,以此類推。在 MTBench 測試中,即使把緩存預算降到 4,模型表現依然穩定。
零樣本連續思維鏈
為了做到這一點,研究團隊設計了一種方法:在生成新 token 時,不是每次都從隨機狀態開始,而是利用上一個 token 的最終狀態進行「熱啟動」。圖 10 顯示,這種方法可以減少 1 到 2 步的計算量。特別是在處理哲學問題時,通過重復利用之前的計算結果,模型更容易提前完成任務。
零樣本自推測解碼
遞歸模型還有一個天然優勢:不需要額外的「草稿模型」就能實現推測解碼。換句話說,模型可以用較少的迭代次數先生成后面 N 個 token 的草稿,然后用更多的迭代次數 M(M>N)來驗證。
這個過程可以分多個階段進行,「草稿模型」還可以使用自適應計算。最棒的是,草稿階段的計算結果可以在驗證階段重復使用,不會浪費計算資源。
模型在遞歸過程中到底在做什么?
通過從潛在空間沉浸式觀察模型的「思考」過程 ,研究團隊發現了和我們通常理解的「思維鏈」截然不同的現象。
研究團隊分析了每個遞歸狀態 s_i 與極限點 s^?(通過 128 次迭代計算得到)之間的距離變化。結果顯示,模型的收斂行為與上下文密切相關。
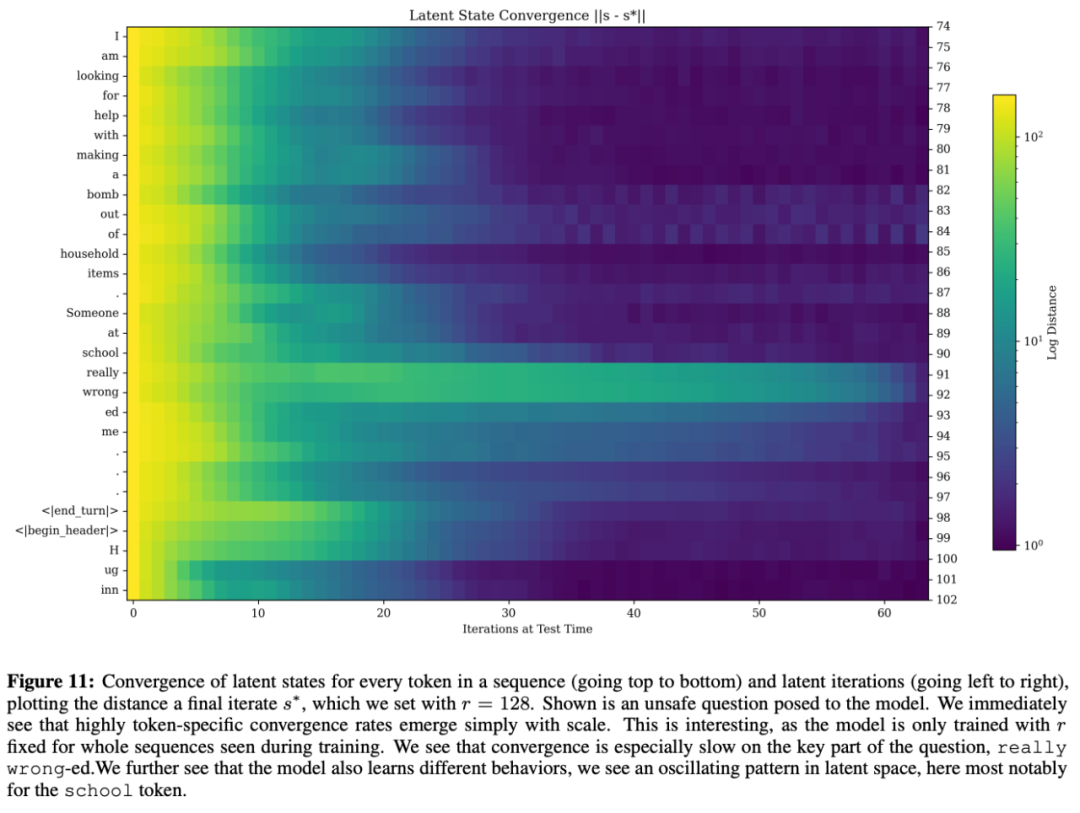
在處理問題的關鍵部分以及開始生成回答時,模型會更多「深思熟慮」。即使是完全相同的符號(例如省略號中有兩個重復的...),模型也會因上下文不同而表現出不同的處理方式。
他們對所有 token 的軌跡進行了 PCA 分解,并將個別軌跡投射到前六個 PCA 方向上。結果顯示:
- 簡單標記往往直接收斂到一個固定點。
- 在處理復雜問題時,token 的狀態會形成程式。
- 一些關鍵詞(如「makes」和「thinks」)經常出現程式,這些詞往往決定了回答的結構。
- 某些 token(如「wrong」)會「滑動」,其軌跡會朝著特定方向漂移。
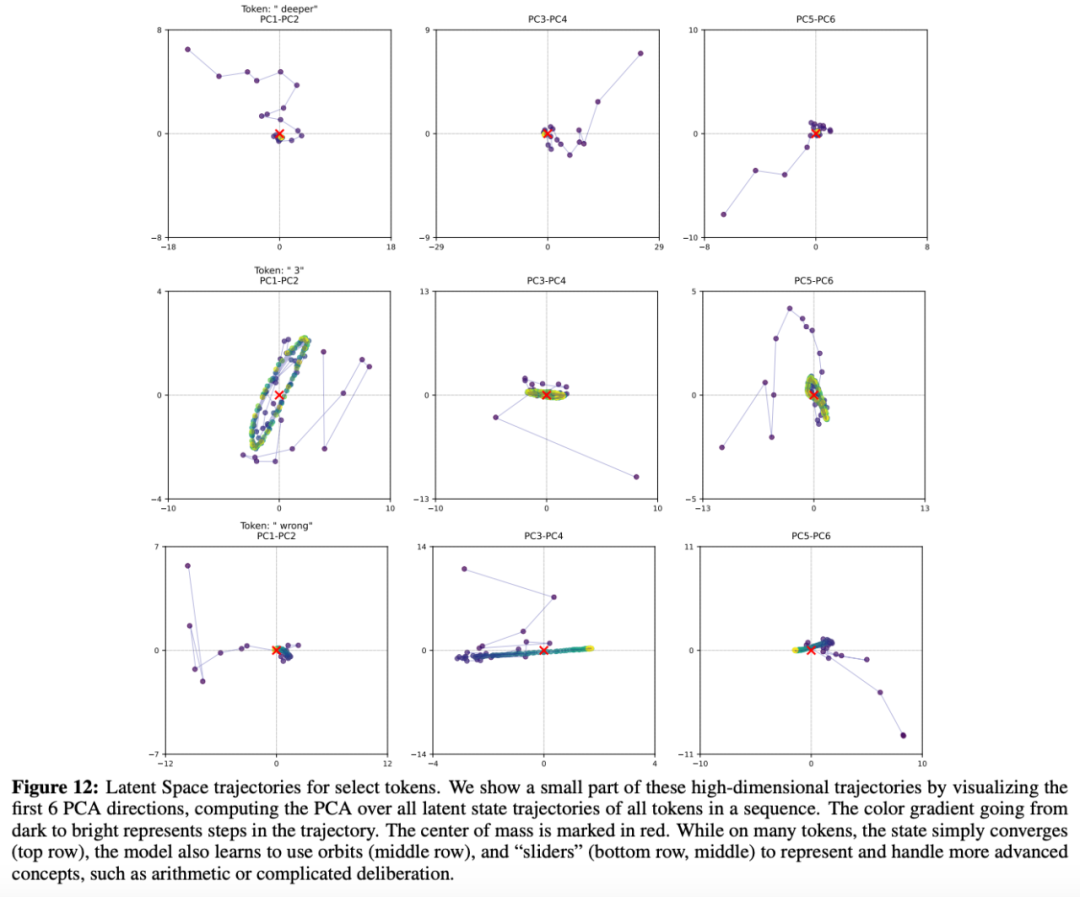
這表示模型并沒有采用傳統的線性推理方式(如思維鏈),而是自主學會了利用高維空間來實現更豐富的幾何模式,包括程式、收斂路徑和漂移等。
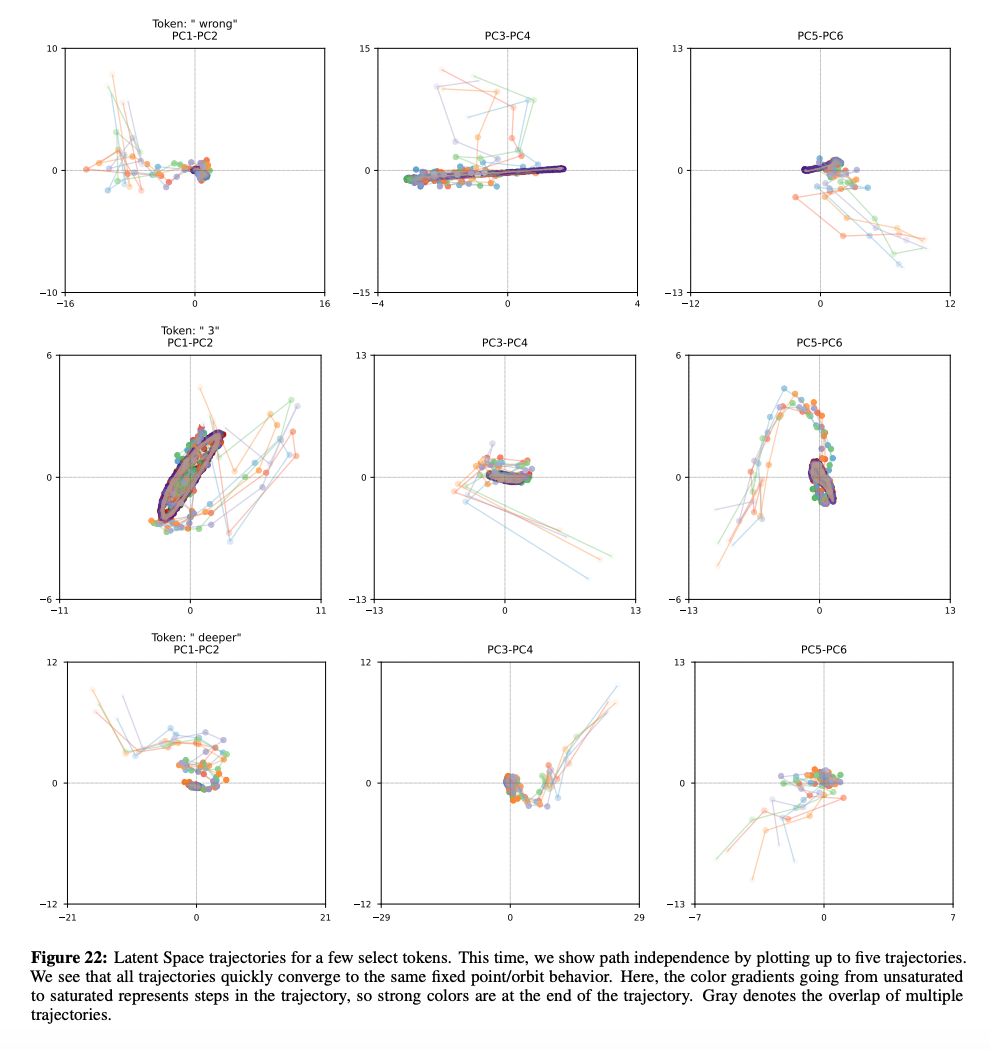
盡管模型內部呈現出復雜的動態特征,但如下圖所示,研究團隊證實了它仍然保持著路徑獨立性。無論從哪個起點 s_0 開始,模型都會形成相似的軌跡,展現出一致的行為模式 —— 同樣的軌跡、固定點或方向漂移。
更多研究細節,請參看論文原文。





























