首個標注詳細解釋的多模態科學問答數據集,深度學習模型推理有了思維鏈
在回答復雜的問題時,人類可以理解不同模態的信息,并形成一個完整的思維鏈(Chain of Thought, CoT)。深度學習模型是否可以打開「黑箱」,對其推理過程提供一個思維鏈呢?近日,UCLA 和艾倫人工智能研究院(AI2)提出了首個標注詳細解釋的多模態科學問答數據集 ScienceQA,用于測試模型的多模態推理能力。在 ScienceQA 任務中,作者提出 GPT-3 (CoT) 模型,即在 GPT-3 模型中引入基于思維鏈的提示學習,從而使得模型能在生成答案的同時,生成相應的推理解釋。GPT-3 (CoT) 在 ScienceQA 上實現了 75.17% 的準確率;并且人類評估表明,其可以生成較高質量的解釋。
像人類一樣有效地學習并完成復雜的任務是人工智能追求的長遠目標之一。人類在決策過程中可以遵循一個完整的思維鏈(CoT)推理過程,從而對給出的答案做出合理的解釋。
然而,已有的機器學習模型大多依賴大量的輸入 - 輸出樣本訓練來完成具體的任務。這些黑箱模型往往直接生成最終的答案,而沒有揭示具體的推理過程。
科學問答任務(Science Question Answering)可以很好地診斷人工智能模型是否具有多步推理能力和可解釋性。為了回答科學問題,一個模型不僅需要理解多模態內容,還需要提取外部知識以得出正確答案。同時,一個可靠的模型還應該給出揭示其推理過程的解釋。然而,目前的科學問答數據集大多缺乏對答案的詳細解釋,或者局限于文字模態。
因此,作者收集了全新的科學問答數據集 ScienceQA,它包含了 21,208 道來自中小學科學課程的問答多選題。一道典型的問題包含多模態的背景(context)、正確的選項、通用的背景知識(lecture)以及具體的解釋(explanation)。

ScienceQA 數據集的一個例子。
要回答上圖所示的例子,我們首先要回憶關于力的定義:「A force is a push or a pull that ... The direction of a push is ... The direction of a pull is ... 」,然后形成一個多步的推理過程:「The baby’s hand applies a force to the cabinet door. → This force causes the door to open. → The direction of this force is toward the baby’s hand. 」,最終得到正確答案:「This force is a pull. 」。
在 ScienceQA 任務中,模型需要在預測答案的同時輸出詳細地解釋。在本文中,作者利用大規模語言模型生成背景知識和解釋,作為一種思維鏈(CoT)來模仿人類具有的多步推理能力。
實驗表明,目前的多模態問答方法在 ScienceQA 任務不能取得很好的表現。相反,通過基于思維鏈的提示學習,GPT-3 模型能在 ScienceQA 數據集上取得 75.17% 的準確率,同時可以生成質量較高的解釋:根據人類評估,其中 65.2% 的解釋相關、正確且完整。思維鏈也可以幫助 UnifiedQA 模型在 ScienceQA 數據集上取得 3.99% 的提升。

- 論文鏈接:https://arxiv.org/abs/2209.09513
- 代碼鏈接:https://github.com/lupantech/ScienceQA
- 項目主頁:https://scienceqa.github.io/
- 數據可視化:https://scienceqa.github.io/explore.html
- Leaderboard:https://scienceqa.github.io/leaderboard.html
1、ScienceQA 數據集
數據集統計
ScienceQA 的主要統計信息如下所示。

ScienceQA 數據集的主要信息
ScienceQA 包含 21208 個例子, 其中有 9122 個不同的問題(question)。10332 道(48.7%)有視覺背景信息,10220 道(48.2%)有文本背景信息,6532 道(30.8%)有視覺 + 文本的背景信息。絕大部分問題標注有詳細的解釋:83.9% 的問題有背景知識標注(lecture),而 90.5% 的問題有詳細的解答(explanation)。

ScienceQA 數據集中問題和背景分布。
數據集主題分布
不同于已有的數據集,ScienceQA 涵蓋自然科學、社會科學和語言學三大學科分支,包含 26 個主題(topic)、127 個分類(category)和 379 個知識技能(skill)。

ScienceQA 的主題分布。
數據集詞云分布
如下圖的詞云分布所示,ScienceQA 中的問題具有豐富的語義多樣性。模型需要理解不同的問題表達、場景和背景知識。
ScienceQA 的詞云分布。
數據集比較
ScienceQA 是第一個標注詳細解釋的多模態科學問答數據集。相比于已有的數據集,ScienceQA 的數據規模、題型多樣性、主題多樣性等多個維度體現了優勢。

ScienceQA 數據集與其它科學問答數據集的比較。
2、模型和方法
Baselines
作者在 ScienceQA 數據集了評估不同的基準方法,包括 VQA 模型如 Top-Down Attention、MCAN、BAN、DFAF、ViLT、Patch-TRM 和 VisualBERT,大規模語言模型如 UnifiedQA 和 GPT-3,以及 random chance 和 human performance。對于語言模型 UnifiedQA 和 GPT-3,背景圖片會被轉換成文本形式的注釋(caption)。
GPT-3 (CoT)
最近的研究工作表明,在給定合適的提示后,GPT-3 模型可以在不同的下游任務表現出卓越的性能。為此,作者提出 GPT-3 (CoT) 模型,在提示中加入思維鏈(CoT),使得模型在生成答案的同時,可以生成對應的背景知識和解釋。
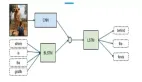
具體的提示模板如下圖所示。其中 Ii 表示訓練例子,It 表示測試例子。訓練例子包含問題(Question)、選項(Options)、背景(Context)和答案(Answer)元素,其中答案由正確答案、背景知識(Lecture)和解釋(Explanation)組成。GPT-3 (CoT) 會根據輸入的提示信息,補全測試例子的預測答案、背景知識和解釋。

GPT-3 (CoT) 采用的提示模板。
3、實驗與分析
實驗結果
不同的基準和方法在 ScienceQA 測試集上的準確率結果如下表所示。當前最好的 VQA 模型之一的 VisualBERT 只能達到 61.87% 的準確率。在訓練的過程引入 CoT 數據,UnifiedQA_BASE 模型可以實現 74.11% 的準確率。而 GPT-3 (CoT) 在 2 個訓練例子的提示下,實現了 75.17% 的準確率,高于其它基準模型。人類在 ScienceQA 數據集上表現優異,可以達到 88.40% 的總體準確率,并且在不同類別的問題上表現穩定。

不同的方法在 ScienceQA 測試集上的結果。
生成解釋的評估
作者用自動評估指標如 BLEU-1、BLEU-2、ROUGE-L 和 Sentence Similarity 評估了不同方法生成的解釋。由于自動評估指標只能衡量預測結果和標注內容的相似性,因此作者進一步采用了人工評估的方法,來評估生成解釋的相關性、正確性和完整性。可以看到,GPT-3 (CoT) 生成的解釋中 65.2% 符合了 Gold 標準。
不同評估方法對生成解釋的結果。
不同的提示模板
作者比較了不同的提示模板對 GPT-3 (CoT) 準確率的影響。可以看到在 QAM-ALE 的模板下,GPT-3 (CoT) 可以獲得最大的平均準確率和最小的方差。另外,GPT-3 (CoT) 在 2 個訓練例子的提示下,表現最佳。
不同提示模板的結果比較。
模型上限
為了探索 GPT-3 (CoT) 模型的性能上限,作者把標注的背景知識和解釋加入模型的輸入(QCMLE*-A)。我們可以看到 GPT-3 (CoT) 可以實現高達 94.13% 的準確率。這也提示了模型提升的一個可能方向:模型可以進行分步推理,即先檢索到準確的背景知識和生成準確的解釋,然后把這些結果作為輸入。這個過程和人類解決復雜問題的過程很相似。

GPT-3 (CoT) 模型的性能上限。
不同的 ALE 位置
作者進一步討論了 GPT-3 (CoT) 在生成預測時,不同的 ALE 位置對結果的影響。在 ScienceQA 上的實驗結果表明,如果 GPT-3 (CoT) 先生成背景知識 L 或解釋 E,再生成答案 A,其預測準確率會大幅下降。其主要原因是背景知識 L 和解釋 E 有較多的詞語數量,如果先生成 LE,GPT-3 模型有可能用完最大詞數,或者提前停止生成文本,從而不能得到最終的答案 A。
 不同的 LE 位置。
不同的 LE 位置。
成功案例
如下 4 個例子中,GPT-3 (CoT) 不但能生成正確的答案,也能給出相關、正確且完整的解釋。這說明 GPT-3 (CoT) 在 ScienceQA 數據集上表現出較強的多步推理和解釋能力。




GPT-3 (CoT) 生成正確答案和解釋的例子。
失敗案例 I
在下面的三個例子中,GPT-3 (CoT) 雖然生成了正確的答案,但是生成的解釋不相關、不正確或者不完整。這說明 GPT-3 (CoT) 對于生成邏輯一致的長序列還面臨較大的困難。



GPT-3 (CoT) 能生成正確答案、但是生成的解釋不正確的例子。
失敗案例 II
在下面的四個例子中,GPT-3 (CoT) 不能生成正確的答案,也不能生成正確的解釋。其中的原因有:(1)當前的 image captioning 模型還不能準確地描述示意圖、表格等圖片的語義信息,如果用圖片注釋文本表示圖片,GPT-3 (CoT) 還不能很好地回答包含圖表背景的問題;(2)GPT-3 (CoT) 生成長序列時,容易出現前后不一致(inconsistent)或不連貫(incoherent)的問題;(3)GPT-3 (CoT) 還不能很好地回答需要特定領域知識的問題。




GPT-3 (CoT) 能生成錯誤答案和解釋的例子。
4、結論與展望
作者提出了首個標注詳細解釋的多模態科學問答數據集 ScienceQA。ScienceQA 包含 21208 道來自中小學科學學科的多選題,涵蓋三大科學領域和豐富的話題,大部分問題標注有詳細的背景知識和解釋。ScienceQA 可以評估模型在多模態理解、多步推理和可解釋性方面的能力。作者在 ScienceQA 數據集上評估了不同的基準模型,并提出 GPT-3 (CoT) 模型在生成答案的同時,可以生成相應的背景知識和解釋。大量的實驗分析和案例分析對模型的改進提出了有利的啟發。