













RNN效率媲美Transformer,谷歌新架構兩連發(fā):同等規(guī)模強于Mamba
這一次,谷歌 DeepMind 在基礎模型方面又有了新動作。
我們知道,循環(huán)神經網絡(RNN)在深度學習和自然語言處理研究的早期發(fā)揮了核心作用,并在許多應用中取得了實功,包括谷歌第一個端到端機器翻譯系統(tǒng)。不過近年來,深度學習和 NLP 都以 Transformer 架構為主,該架構融合了多層感知器(MLP)和多頭注意力(MHA)。
Transformer 已經在實踐中實現(xiàn)了比 RNN 更好的性能,并且在利用現(xiàn)代硬件方面也非常高效。基于 Transformer 的大語言模型在從網絡收集的海量數(shù)據集上進行訓練,取得了顯著的成功。
縱然取得了很大的成功,但 Transformer 架構仍有不足之處,比如由于全局注意力的二次復雜性,Transformer 很難有效地擴展到長序列。此外,鍵值(KV)緩存隨序列長度線性增長,導致 Transformer 在推理過程中變慢。這時,循環(huán)語言模型成為一種替代方案,它們可以將整個序列壓縮為固定大小的隱藏狀態(tài),并迭代更新。但若想取代 Transformer,新的 RNN 模型不僅必須在擴展上表現(xiàn)出相當?shù)男阅埽冶仨殞崿F(xiàn)類似的硬件效率。
在谷歌 DeepMind 近日的一篇論文中,研究者提出了 RG-LRU 層,它是一種新穎的門控線性循環(huán)層,并圍繞它設計了一個新的循環(huán)塊來取代多查詢注意力(MQA)。
他們使用該循環(huán)塊構建了兩個新的模型,一個是混合了 MLP 和循環(huán)塊的模型 Hawk,另一個是混合了 MLP 與循環(huán)塊、局部注意力的模型 Griffin。

- 論文標題:Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
- 論文鏈接:https://arxiv.org/pdf/2402.19427.pdf
研究者表示,Hawk 和 Griffin 在 held-out 損失和訓練 FLOPs 之間表現(xiàn)出了冪律縮放,最高可以達到 7B 參數(shù),正如之前在 Transformers 中觀察到的那樣。其中 Griffin 在所有模型規(guī)模上實現(xiàn)了比強大 Transformer 基線略低的 held-out 損失。
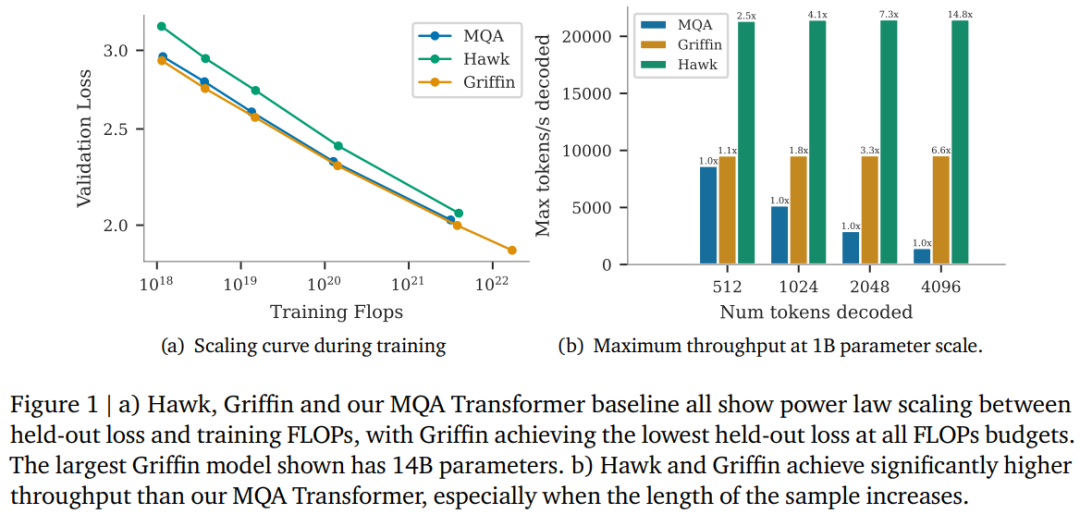
研究者針對一系列模型規(guī)模、在 300B tokens 上對 Hawk 和 Griffin 進行了過度訓練,結果顯示,Hawk-3B 在下游任務的性能上超越了 Mamba-3B,盡管訓練的 tokens 數(shù)量只有后者的一半。Griffin-7B 和 Griffin-14B 的性能與 Llama-2 相當,盡管訓練的 tokens 數(shù)量只有后者的 1/7。
此外,Hawk 和 Griffin 在 TPU-v3 上達到了與 Transformers 相當?shù)挠柧毿省S捎趯?RNN 層受內存限制,研究者使用了 RG-LRU 層的內核來實現(xiàn)這一點。
同時在推理過程中,Hawk 和 Griffin 都實現(xiàn)比 MQA Transformer 更高的吞吐量,并在采樣長序列時實現(xiàn)更低的延遲。當評估的序列比訓練中觀察到的更長時,Griffin 的表現(xiàn)比 Transformers 更好,并且可以有效地從訓練數(shù)據中學習復制和檢索任務。不過當在未經微調的情況下在復制和精確檢索任務上評估預訓練模型時,Hawk 和 Griffin 的表現(xiàn)不如 Transformers。
共同一作、DeepMind 研究科學家 Aleksandar Botev 表示,混合了門控線性循環(huán)和局部注意力的模型 Griffin 保留了 RNN 的所有高效優(yōu)勢和 Transformer 的表達能力,最高可以擴展到 14B 參數(shù)規(guī)模。

來源:https://twitter.com/botev_mg/status/1763489634082795780
Griffin 模型架構
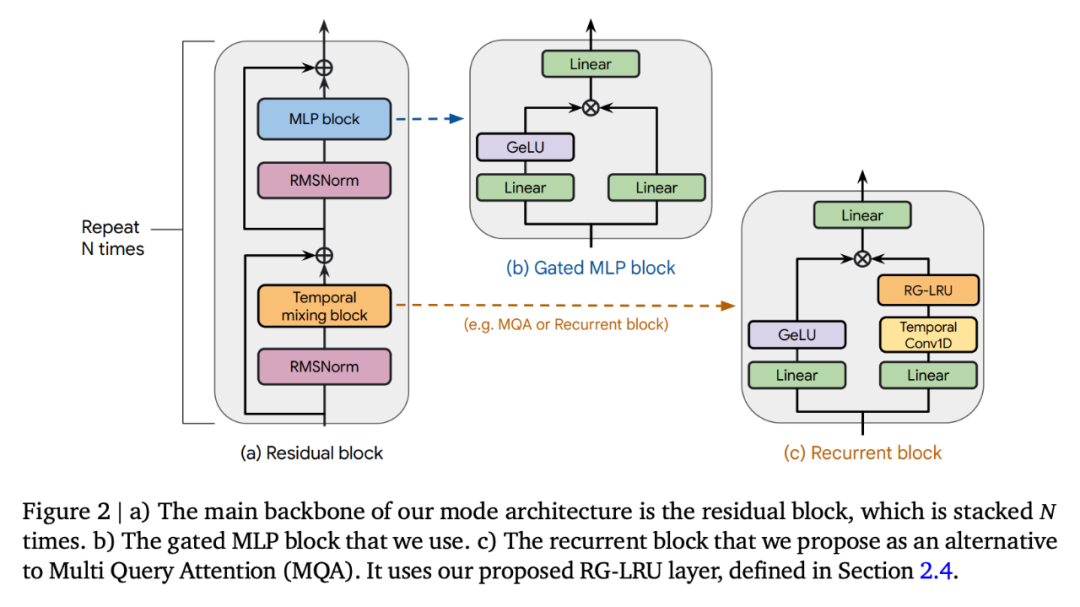
Griffin 所有模型都包含以下組成部分:(i) 一個殘差塊,(ii) 一個 MLP 塊,(iii) 一個時間混合塊。所有模型的 (i) 和 (ii) 都是相同的,但時間混合塊有三個:全局多查詢注意(MQA)、局部(滑動窗口)MQA 和本文提出的循環(huán)塊。作為循環(huán)塊的一部分,研究者使用了真實門控線性循環(huán)單元(RG-LRU)—— 一種受線性循環(huán)單元啟發(fā)的新型循環(huán)層。
如圖 2(a)所示,殘差塊定義了 Griffin 模型的全局結構,其靈感來自 pre-normTransformer。在嵌入輸入序列后,研究者將其通過 ?? 這樣的塊(?? 表示模型深度),然后應用 RMSNorm 生成最終激活。為了計算 token 概率,應用了最后的線性層,然后是 softmax。該層的權重與輸入嵌入層共享。
循環(huán)模型,縮放效率媲美 Transformer
縮放研究為如何調整模型的超參數(shù)及其在縮放時的行為提供了重要見解。
研究者定義了本研究中進行評估的模型,并提供了高達和超過 7B 參數(shù)的縮放曲線,并評估了模型在下游任務中的性能。
他們考慮了 3 個模型系列:(1)MQA-Transformer 基線;(2)Hawk:純 RNN 模型;(3)Griffin:混合模型,它將循環(huán)塊與局部注意力混合在一起。附錄 C 中定義了各種規(guī)模模型的關鍵模型超參數(shù)。
Hawk 架構使用了與 Transformer 基線相同的殘差模式和 MLP 塊,但研究者使用了帶有 RG-LRU 層的循環(huán)塊作為時序混合塊,而不是 MQA。他們將循環(huán)塊的寬度擴大了約 4/3 倍(即??_?????? ≈4??/3),以便在兩者使用相同的模型維度 ?? 時,與 MHA 塊的參數(shù)數(shù)量大致匹配。
Griffin。與全局注意力相比,循環(huán)塊的主要優(yōu)勢在于它們使用固定的狀態(tài)大小來總結序列,而 MQA 的 KV 緩存大小則與序列長度成正比增長。局部注意力具有相同的特性,而將循環(huán)塊與局部注意力混合則可以保留這一優(yōu)勢。研究者發(fā)現(xiàn)這種組合極為高效,因為局部注意力能準確模擬最近的過去,而循環(huán)層則能在長序列中傳遞信息。
Griffin 使用了與 Transformer 基線相同的殘差模式和 MLP 塊。但與 MQA Transformer 基線和 Hawk 模型不同的是,Griffin 混合使用了循環(huán)塊和 MQA 塊。具體來說,研究者采用了一種分層結構,將兩個殘差塊與一個循環(huán)塊交替使用,然后再使用一個局部(MQA)注意力塊。除非另有說明,局部注意力窗口大小固定為 1024 個 token。
主要縮放結果如圖 1(a)所示。三個模型系列都是在從 1 億到 70 億個參數(shù)的模型規(guī)模范圍內進行訓練的,不過 Griffin 擁有 140 億參數(shù)的版本。
在下游任務上的評估結果如表 1 所示:

Hawk 和 Griffin 的表現(xiàn)都非常出色。上表報告了 MMLU、HellaSwag、PIQA、ARC-E 和 ARC-C 的特征歸一化準確率,同時報告了 WinoGrande 的絕對準確率和部分評分。隨著模型規(guī)模的增大,Hawk 的性能也得到了顯著提高,Hawk-3B 在下游任務中的表現(xiàn)要強于 Mamba-3B,盡管其訓練的 token 數(shù)量只有 Mamba-3B 的一半。Griffin-3B 的性能明顯優(yōu)于 Mamba-3B,Griffin-7B 和 Griffin-14B 的性能可與 Llama-2 相媲美,盡管它們是在少了近 7 倍的 token 上訓練出來的。Hawk 能與 MQA Transformer 基線相媲美,而 Griffin 的表現(xiàn)則超過了這一基線。
在端側高效訓練循環(huán)模型
在開發(fā)和擴展模型時,研究者遇到了兩大工程挑戰(zhàn)。首先,如何在多臺設備上高效地分片處理模型。第二,如何有效地實現(xiàn)線性循環(huán),以最大限度地提高 TPU 的訓練效率。本文討論了這兩個難題,然后對 Griffin 和 MQA 基線的訓練速度進行實證比較。
研究者比較了不同模型大小和序列長度的訓練速度,以研究本文模型在訓練過程中的計算優(yōu)勢。對于每種模型大小,都保持每批 token 的總數(shù)固定不變,這意味著隨著序列長度的增加,序列數(shù)量也會按比例減少。
圖 3 繪制了 Griffin 模型與 MQA 基線模型在 2048 個序列長度下的相對運行時間。

推理速度
LLM 的推理由兩個階段組成。「預填充 」階段是接收并處理 prompt。這一步實際上是對模型進行前向傳遞。由于 prompt 可以在整個序列中并行處理,因此在這一階段,大多數(shù)模型操作都是計算受限的因此,研究者預計 Transformers 模型和循環(huán)模型在預填充階段的相對速度與前文討論的那些模型在訓練期間的相對速度相似。
預填充之后是解碼階段,在這一階段,研究者從模型中自回歸地采 token。如下所示,尤其是對于序列長度較長時,注意力中使用的鍵值(KV)緩存變得很大,循環(huán)模型在解碼階段具有更低的延遲和更高的吞吐量。
評估推斷速度時有兩個主要指標需要考慮。第一個是延遲,它衡量在特定批量大小下生成指定數(shù)量 token 所需的時間。第二個是吞吐量,它衡量在單個設備上采樣指定數(shù)量 token 時每秒可以生成的最大 token 數(shù)。因為吞吐量由采樣的 token 數(shù)乘以批量大小除以延遲得出,所以可以通過減少延遲或減少內存使用以在設備上使用更大的批量大小來提高吞吐量。對于需要快速響應時間的實時應用來說,考慮延遲是有用的。吞吐量也值得考慮,因為它可以告訴我們在給定時間內可以從特定模型中采樣的最大 token 數(shù)量。當考慮其他語言應用,如基于人類反饋的強化學習(RLHF)或評分語言模型輸出(如 AlphaCode 中所做的)時,這個屬性是有吸引力的,因為能夠在給定時間內輸出大量 token 是一個吸引人的特性。
在此,研究者研究了參數(shù)為 1B 的模型推理結果。在基線方面,它們與 MQA Transformer 進行了比較,后者在推理過程中的速度明顯快于文獻中常用的標準 MHA 變換器。研究者比較的模型有:i) MQA 變換器,ii) Hawk 和 iii) Griffin。為了比較不同的模型,我們報告了延遲和吞吐量。
如圖 4 所示,研究者比較了批量大小為 16、空預填充和預填充 4096 個 token 的模型的延遲。

圖 1(b)中比較了相同模型在空提示后分別采樣 512、1024、2048 和 4196 個 token 時的最大吞吐量(token / 秒)。
長上下文建模
本文還探討了 Hawk 和 Griffin 使用較長上下文來改進下一個 token 預測的有效性,并研究它們在推理過程中的外推能力。此外還探討了 Griffin 在需要復制和檢索能力的任務中的表現(xiàn),既包括在此類任務中訓練的模型,也包括在使用預訓練的語言模型測試這些能力時的表現(xiàn)。
從圖 5 左側的曲線圖中,可以觀察到,在一定的最大長度范圍內,Hawk 和 Griffin 都能在更長的上下文中提高下一個 token 的預測能力,而且它們總體上能夠推斷出比訓練時更長的序列(至少 4 倍)。尤其是 Griffin,即使在局部注意力層使用 RoPE 時,它的推理能力也非常出色。

如圖 6 所示,在選擇性復制任務中,所有 3 個模型都能完美地完成任務。在比較該任務的學習速度時, Hawk 明顯慢于 Transformer,這與 Jelassi et al. (2024) 的觀察結果類似,他們發(fā)現(xiàn) Mamba 在類似任務上的學習速度明顯較慢。有趣的是,盡管 Griffin 只使用了一個局部注意力層,但它的學習速度幾乎沒有減慢,與 Transformer 的學習速度不相上下。

更多細節(jié),請閱讀原論文。




























