Meta全新腦機接口模型,挑戰Neuralink!無需植入芯片實現「心靈感應」
腦機接口一直是全球關注的新技術。尤其是有著馬斯克光環加持下的Neuralink,更是備受矚目。
幾天前,Neuralink發文稱,過去一年中已經有三名癱瘓患者接受了Neuralink的植入。
通過植入物,這幾位患者僅憑思想就能控制手機和電腦,這種能力被Neuralink稱之為「心靈感應」(Telepathy)。

參與者已經累計使用「心靈感應」超過4900小時,其中大部分是獨立使用,這表明了該技術在現實生活中具有應用潛力。
其中一位名為Brad的參與者通過該項技術成功擺脫了對眼動追蹤器的依賴,能夠在各種環境下與人交流,甚至可以外出參加活動(下圖)。

盡管這些案例都清楚地表明了腦機接口近年來取得的顯著進展,然而,Neuralink的方案也并非完美。
主要的問題在于其使用的侵入性方法,如電極植入,這會帶來包括感染和長期維護問題在內的醫療風險。
Meta AI團隊幾天前剛剛發布的名為「Brain2Qwerty」的全新深度學習架構,正是為解決這一挑戰而來!

論文地址:https://ai.meta.com/research/publications/brain-to-text-decoding-a-non-invasive-approach-via-typing/
實驗表明效果還不錯。
這個新架構可以解碼參與者的腦電圖(EEG)或腦磁圖(MEG)信號。對于表現最好的參與者,該模型實現了19%的字符錯誤率,并且可以完美解碼訓練集之外的各種句子。
最關鍵的是,Brain2Qwerty是非侵入式的,它大大縮小了與侵入式方法之間的差距,為開發更加安全的腦機接口技術開辟了道路!
Meta團隊怎么做到的?
首先,研究者讓35名參與者在鍵盤上打出他們短暫記住的句子,同時通過腦電圖(EEG)或腦磁圖(MEG)記錄下他們的大腦活動。
然后,研究者開始訓練Brain2Qwerty——一個三階段的深度神經網絡——來從這些大腦信號中解碼出文字,并評估效果。
首先,第一階段卷積模塊(Convolutional Module)接收500毫秒的腦電圖(EEG)或腦磁圖(MEG)信號作為輸入,提取這些信號的特征。
然后,轉換器模塊(Transformer Module)利用自注意力機制捕捉句子級別的上下文信息,優化按鍵預測,并輸出每個字符的logits。最后,預訓練語言模型(Pretrained Language Model)利用統計規律,修正轉換器的輸出,從而進一步提高解碼的準確性。
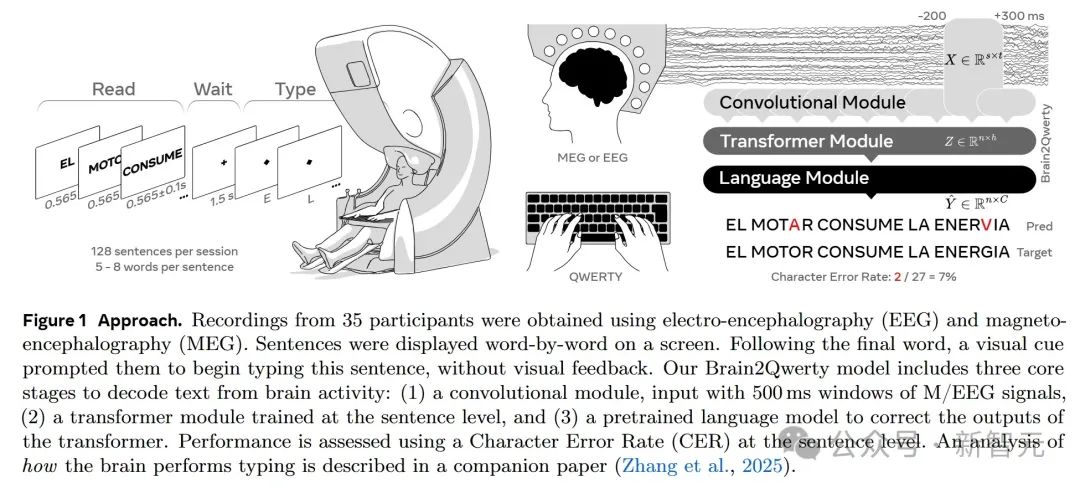
具體過程如下圖1,Brain2Qwerty模型利用腦電圖或腦磁圖信號,通過卷積、轉換器和語言模型3個階段來解碼鍵盤上輸入的文本。
實驗結果
研究人員首先關注左右手按鍵引起的誘發反應差異,結果顯示,腦磁圖(MEG)在手分類的準確率上優于腦電圖(EEG)。MEG的峰值準確率為74%(±1.3%標準誤差均值),而EEG的峰值準確率為64%(±0.8%)。
這些結果驗證了當前的實驗方法確實能在腦中產生預期的按鍵反應。
Brain2Qwerty在腦磁圖(MEG)數據上的表現明顯優于腦電圖(EEG )。具體來說,MEG的平均字符錯誤率(CER)為32%(±0.6%),EEG的平均字符錯誤率(CER)為67%(±1.5%)。
這種性能差異在統計學上非常顯著。
盡管平均性能上存在顯著差異,研究人員也注意到了個體之間的差異。EEG表現最差和最好受試者的CER分別為61%(±2.0%)和71%(±2.3%)。MEG表現最差和最好受試者的CER分別為45%(±1.2%)和19%(±1.1%)。也十分明顯。
不同模型的對比
為了評估Brain2Qwerty模型的性能,研究人員選擇了兩種經典的基線模型進行比較:線性模型和EEGNet(一種在腦機接口領域經常用的緊湊型卷積神經網絡)。
結果顯示,EEGNet在MEG數據上優于線性模型,但在EEG數據上的優勢不明顯。Brain2Qwerty模型在EEG和MEG數據上的表現均顯著優于EEGNet和線性模型。
這種優勢表明,Brain2Qwerty模型的三階段架構(卷積模塊、轉換器模塊和語言模型)對于解碼腦活動中的文本具有重要作用。
下圖A和B表明,左右手按鍵會在大腦皮層產生不同的神經活動模式,這些活動模式可以通過EEG和MEG檢測到;C和D驗證了分類器可以有效地區分左右手和不同字符的腦活動;
E-H比較了不同架構(包括線性模型、EEGNet以及Brain2Qwerty模型的不同變體)在手錯誤率(HER)和字符錯誤率(CER)上的表現。每個點代表一個受試者的平均得分。
消融實驗
研究人員重新訓練并評估了以下兩種消融版本的模型:(i)僅卷積模塊(Conv):移除了轉換器模塊和語言模型,僅使用卷積模塊進行解碼;(ii)卷積模塊+轉換器模塊(Conv+Trans):移除了語言模型,使用卷積模塊和轉換器模塊進行解碼。
然后研究者使用相同的數據集和超參數對這些消融模型進行訓練和評估,并使用手錯誤率(HER)和字符錯誤率(CER)來衡量性能。
結果顯示,僅卷積模塊 (Conv)在EEG和MEG數據上的性能均優于EEGNet。添加轉換器模塊后,卷積模塊+轉換器模塊 (Conv+Trans)在EEG和MEG數據上的CER均得到改善,這表明轉換器模塊在利用上下文信息方面發揮了關鍵作用。
使用語言模型后,完整的Brain2Qwerty在EEG的CER進一步改善了4%,MEG的CER進一步改善了6%。語言模型通過利用自然語言的統計規律性,有效地提高了解碼準確性。
解碼句子展示
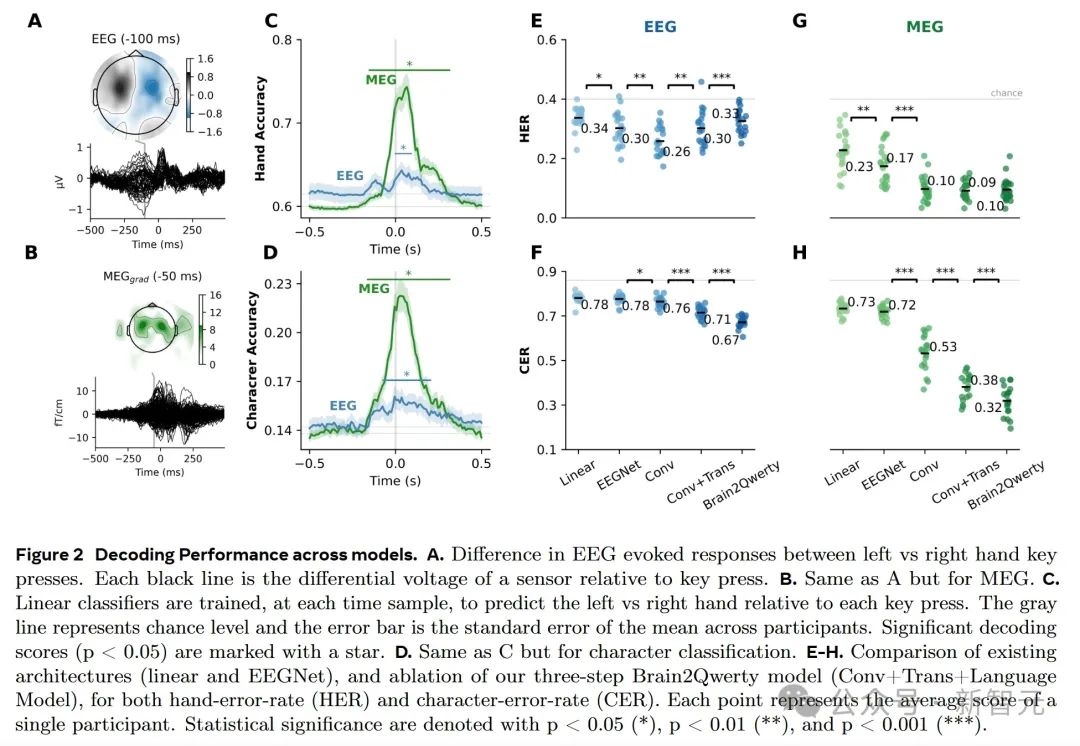
研究人員指出,MEG可以完美解碼一些句子。這表明Brain2Qwerty模型在MEG數據上具有相當高的解碼精度。例如,「la silla ocasiona las lesiones」這句話就被完美解碼。
更有趣的是,Brain2Qwerty的語言模型可以糾正受試者的輸入錯誤。例如,即使受試者輸入了「ek benefucui syoera kis ruesgis」,仍然被完美解碼出「el beneficio supera los riesgos」了。
相比之下,EEG的解碼效果較差,很少能產生可理解的文本。這與之前報告的統計結果一致,即MEG的解碼性能明顯優于EEG。
在EEG的例子中,解碼結果通常包含大量錯誤,如「la ciencia de la idea las mas de esos」,與原句「la ciencia de la idea rompe la vision」相差甚遠。
下圖3A顯示了Best(最佳)、Median(中位數)和Worst(最差)MEG受試者的句子字符錯誤率。每個點代表一個獨特的句子。圖3B顯示了兩個例句的解碼預測結果,其中使用了多個分割種子來獲取跨句子的預測。
鍵盤布局對Brain2Qwerty的影響
如果Brain2Qwerty模型依賴于運動皮層的腦活動,那么其解碼錯誤應該與QWERTY鍵盤的物理布局相關。也就是說,模型更容易將一個按鍵錯誤地預測為鍵盤上物理位置接近的按鍵。
研究人員分析了錯誤預測字符的混淆模式,并計算了解碼字符和實際按鍵在鍵盤上的距離。
結果顯示,距離和混淆率之間存在顯著的相關性。這意味著,鍵盤上物理距離越近的按鍵,越容易被混淆。
下圖A表明模型解碼錯誤與鍵盤的物理布局有關,模型傾向于將按鍵混淆為物理位置接近的按鍵。圖B進一步證實了模型依賴運動表征。圖C顯示打字錯誤與較長的按鍵間隔相關。圖D證明打字錯誤會導致解碼性能下降,表明運動過程的準確性直接影響解碼質量。
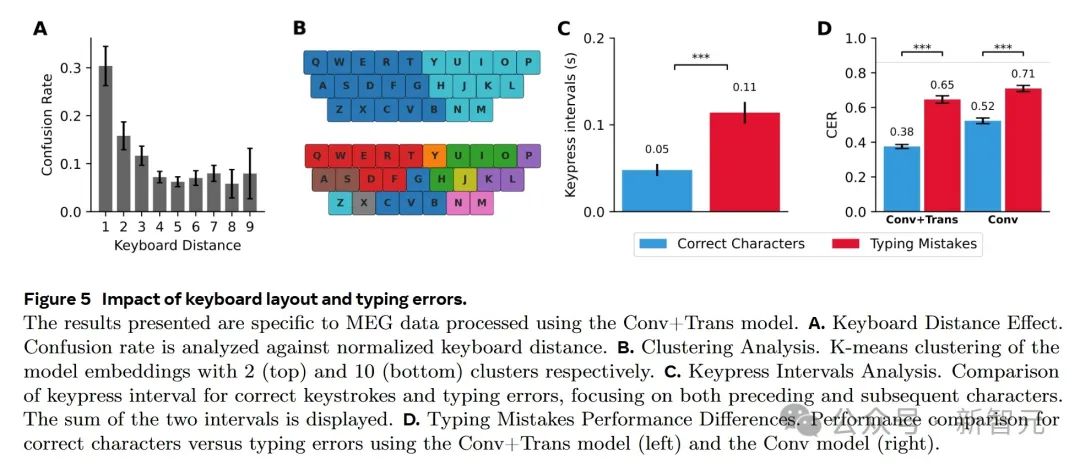
打字錯誤對Brain2Qwerty的影響
研究人員發現,打字錯誤占總按鍵次數的3.9%,65%的句子中都存在打字錯誤,實驗中不允許參與者使用退格鍵糾正錯誤。
錯誤按鍵的按鍵間隔明顯長于正確按鍵。具體而言,正確按鍵的平均間隔時間為50±7毫秒,而錯誤按鍵的平均間隔時間為114±12毫秒。
這種現象反映了打字錯誤時,參與者會出現猶豫或對錯誤進行監控的行為。
為了評估打字錯誤對解碼性能的影響,研究人員分別評估了正確按鍵和錯誤按鍵的字符錯誤率(CER)。使用 Conv+Trans模型時,正確按鍵的CER為38%,而錯誤按鍵的CER為65%。
這表明,正確按鍵的解碼性能顯著優于錯誤按鍵。
為了減少句子上下文對錯誤分析的影響,研究人員還評估了卷積模塊(Conv)的性能。即使僅使用卷積模塊,正確按鍵的CER(52%)仍然低于錯誤按鍵的CER(71%)。
這些結果表明,當運動過程執行不準確時,解碼性能就會下降。
發現、意義與局限性
Meta AI團隊開發的這款Brain2Qwerty模型可以通過非侵入式腦機接口解碼句子生成。為開發更安全、更易于訪問的非侵入式腦機接口打下了基礎。
雖然Brain2Qwerty模型的解碼性能縮小了與侵入式腦機接口之間的差距,但是差距仍然顯著。最新的侵入式腦機接口字符錯誤率僅為15.2%,使用糾錯模型時,打字速度可達每分鐘90個字符,離線字符錯誤率更是低于1%。
雖然腦磁圖(MEG)的效果優于腦電圖(EEG),但目前的腦磁圖系統,包括本研究中使用的系統,都還還不能穿戴。不過,隨著基于光泵磁力儀(OPM)的新型腦磁圖傳感器的發展有望解決這個問題。
Meta AI的Brain2Qwerty深度學習新架構展示了非侵入式腦機接口技術的巨大潛力。
這項研究不僅是技術上的突破,更是對未來人與機器交互方式的探索。