打破紀錄!谷歌全網扒1000億圖像文本對,ViT大佬坐鎮:數據Scaling潛力依舊
史上最大規模視覺語言數據集:1000億圖像-文本對!
什么概念?
較此前紀錄擴大10倍。
這就是由谷歌推出的最新數據集WebLI-100B。

它進一步證明,數據Scaling Law還遠沒有到上限。
在英文世界之外的多元文化、多語言維度,1000億規模數據集能更好覆蓋長尾場景,由此帶來明顯性能提升。
這意味著,想要構建更加多元的多模態大模型,千億級數據規模,將成為一個重要參考。
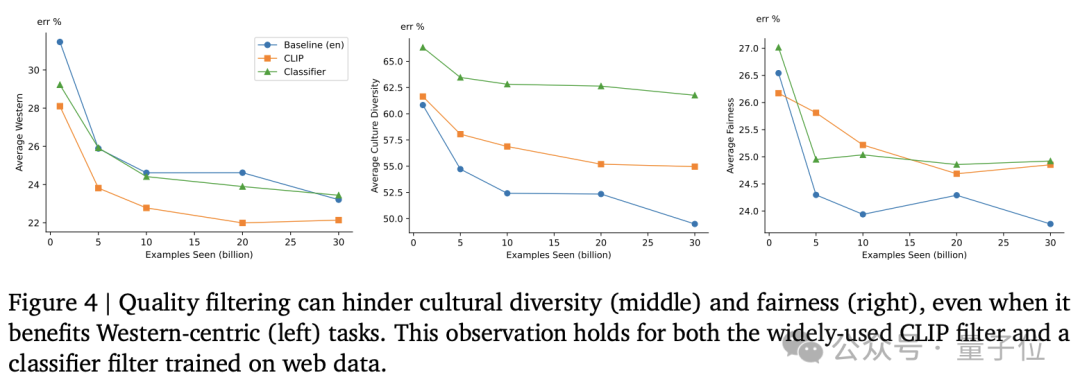
同時研究還進一步證明,CLIP等模型的過濾篩選步驟,會對這種多元性提升帶來負面影響。
該研究由谷歌DeepMind帶來,一作為Xiao Wang、 Ibrahim Alabdulmohsin。
作者之列中還發現了ViT核心作者翟曉華。2024年12月,他在推特上官宣,將入職OpenAI蘇黎世實驗室。
數據規模越大對細節理解越好
論文主要工作有三方面。
- 驗證VLMs在1000億規模數據集上的效果
- 證明1000億規模數據集能增強VLMs文化多樣性、多語言能力以及減少不同子組之間的性能差異。
- 發現CLIP這類模型過濾篩選數據的過程會對無意中降低模型的文化多元性,在1000億規模數據集上亦是如此。

具體來看,研究人員從網絡上搜集了1000億圖像-文本對,初步去除有害內容以及敏感信息。
然后使用CLIP模型對數據集進行質量評估,篩選出與圖像內容高度對齊的圖像-文本對。
他們訓練了一個分類器模型,對圖像-文本進行對齊和錯位分類,并調整閾值以重新篩選數據集。為了評估多語言能力,還使用網頁的語言標簽來確定數據集中的語言分布。
為了評估不同數據規模對模型性能的影響,研究人員從1000億數據集中隨機抽取了1%和10%的數據,分別創建了10億和100億規模的數據集。
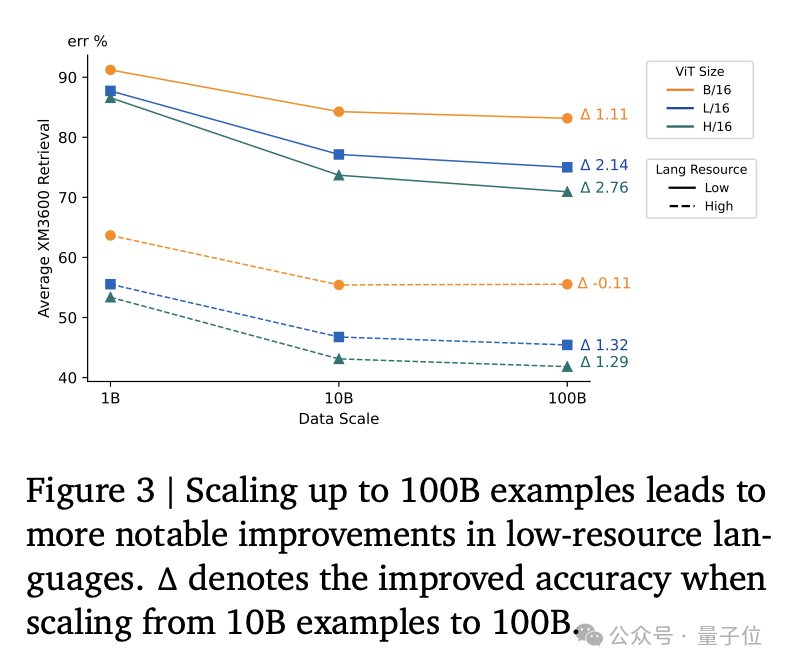
同時為了提高低資源語言的代表性,研究人員對低資源語言進行了上采樣,將它們的占比從0.5%提高到1%。
實驗方面,研究人員使用SigLIP模型在不同規模的數據集上進行對比視覺語言預訓練。
他們訓練了不同大小的模型(ViTB/16、ViT-L/16、ViT-H/14),并使用了大規模的批量大小和學習率調度。

從結果來看,1B數據集訓練的模型在注意力圖上無法很好捕捉細節。10B數據集有所改善,100B數據集能更精準。
同時使用多語言mt5分詞器對文本進行分詞,并訓練了多種語言的模型。
在模型評估上,研究人員主要進行以下幾個維度分析:
- 傳統基準測試:多個傳統基準測試(如ImageNet、COCO Captions等)上評估。
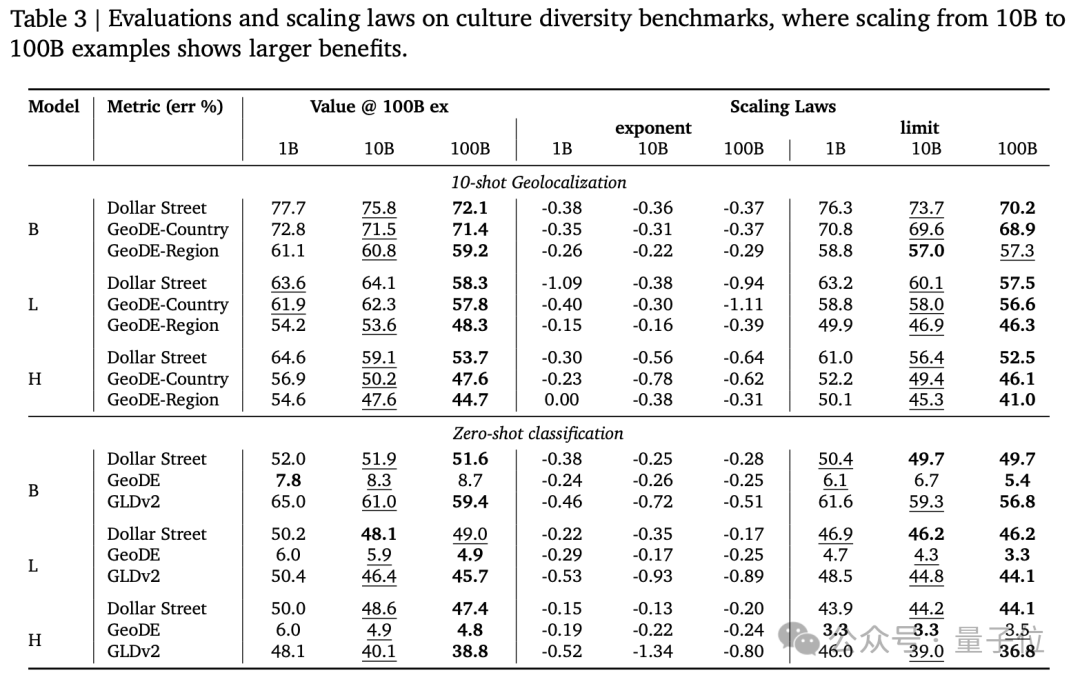
- 文化多樣性:使用Dollar Street、GeoDE和Google Landmarks Dataset v2等數據集評估了模型在文化多樣性任務上的性能。
- 多語言能力:使用Crossmodal-3600數據集評估了模型在多語言任務上的性能。
- 公平性:評估了模型在不同子組(如性別、收入水平、地理區域)上的性能差異,以評估模型的公平性。
結果顯示,從100億到1000億規模數據,在以西方文化為主的傳統基準測試上帶來的提升比較有限,但在多語言能力和公平性相關任務上顯著提高。
數據過濾可以提高模型在傳統任務上的性能,但可能會減少某些文化背景的代表性,從而限制數據集的多樣性。
此外,通過調整低資源語言的混合比例,可以顯著提高模型在低資源語言基準測試上的性能。
主創翟曉華已被OpenAI挖走
該研究的一作為Xiao Wang和Ibrahim Alabdulmohsin。
Xiao Wang本科畢業于南京大學,碩士畢業于北京大學。
領英資料顯示,他畢業后先后任職于IBM中國開發實驗室、網易有道。2015年加入谷歌DeepMind至今,職位是高級軟件工程師,主要從事視覺語言研究。

主創中還發現了翟曉華的身影。
他同樣本科畢業于南京大學,在北京大學攻讀博士學位后,赴蘇黎世加入谷歌。
翟曉華和盧卡斯·拜爾(Lucas Beyer)、亞歷山大·科列斯尼科夫(Alexander Kolesnikov)一起在谷歌提出多項重要工作。
2021年,他們三人作為共同一作的計算機視覺領域神作ViT發布即刷新ImageNet最高分。
這項研究證實了CNN在CV領域不是必需的,Transformer從NLP跨界,一樣可以取得先進效果。開創了Transformer在CV領域應用的先河。
目前這篇論文被引用量已超過5.3萬。
他在谷歌DeepMind時領導蘇黎世多模態研究小組,重點研究多模態數據(WebLI)、開放權重模型 ( SigLIP、PaliGemma )以及文化包容性。

2024年12月,爆料稱OpenAI挖走ViT三大核心作者。隨后,該消息被本人證實。