













谷歌Fellow級大佬出走!17年老將吳永輝加盟字節,親自操刀大模型研發
谷歌17年老將,正式加入字節跳動。
據報道,吳永輝博士已確認離職谷歌,加盟字節負責AI基礎研究領域的工作。

他將在字節擔任大模型團隊Seed基礎研究負責人,專注于大模型基礎研究搜索、AI for Science科研工作,直接向CEO梁汝波匯報。

谷歌AI掃地僧,17年AI老將
2008年9月,吳永輝博士最初作為一名排序工程師加入谷歌,致力于改進谷歌核心網頁搜索排名的算法。

自2015年1月起,他轉入了Google Brain團隊,專注于深度學習及其應用研究。他是谷歌神經機器翻譯和RankBrain項目的核心貢獻者,推動了語音識別的技術發展。
直到2023年,他又晉升為谷歌DeepMind研究副總裁,Google Fellow級別。
要知道,Google Fellow是谷歌頂尖工程師才能享有的稱號,只有極少數的員工能夠獲得這個頭銜。
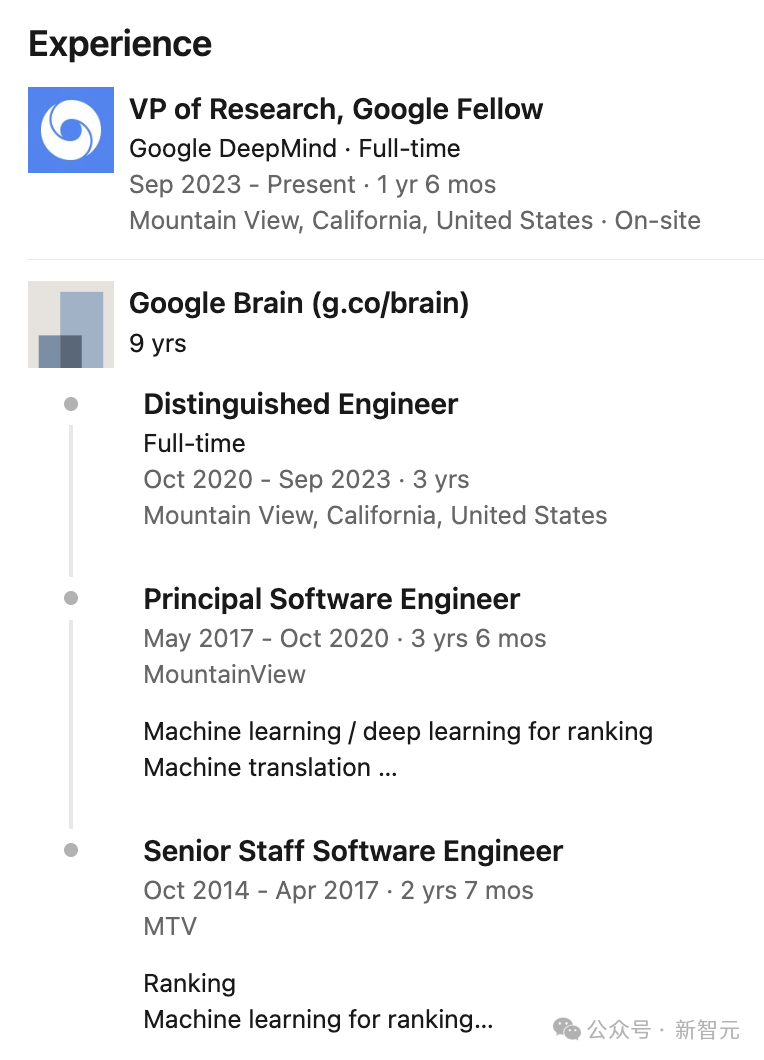
有網友為此,還做了非常詳細的解說,成為Google Fellow(10級)是一個終身榮譽。
值得一提的是,目前谷歌只有兩位Senior Fellow(11級,相當于高級副總裁):Sanjay Ghemawat和Jeff Dean。
以下是Google工程師的職級體系,從1級開始:
L1:IT支持人員
L2:應屆大學畢業生
L3:擁有碩士學位
L4:需要幾年工作經驗或博士學位
L5:大多數工程師的職業發展止步于此
L6:頂尖10%的工程師,他們的能力往往能決定項目的成敗
L7:具有長期優秀業績記錄的L6級工程師
L8:Principal Engineer(首席工程師),通常負責某個重要產品或基礎設施
L9:Distinguished Engineer(杰出工程師),令人敬仰的存在
L10:Google Fellow,這是終身榮譽,獲得者通常是該領域全球頂尖專家
L11:Google Senior Fellow,目前公司僅有的兩位11級工程師是Jeff Dean和Sanjay Ghemawat

吳永輝曾獲得了南京大學計算機學士學位,并于2008年獲得了加州大學河濱分校的數據科學碩士學位和計算機科學博士學位。

他的研究興趣包括信息檢索、排序學習、機器學習、機器翻譯、自然語言處理等領域。

Gemini背后核心貢獻者
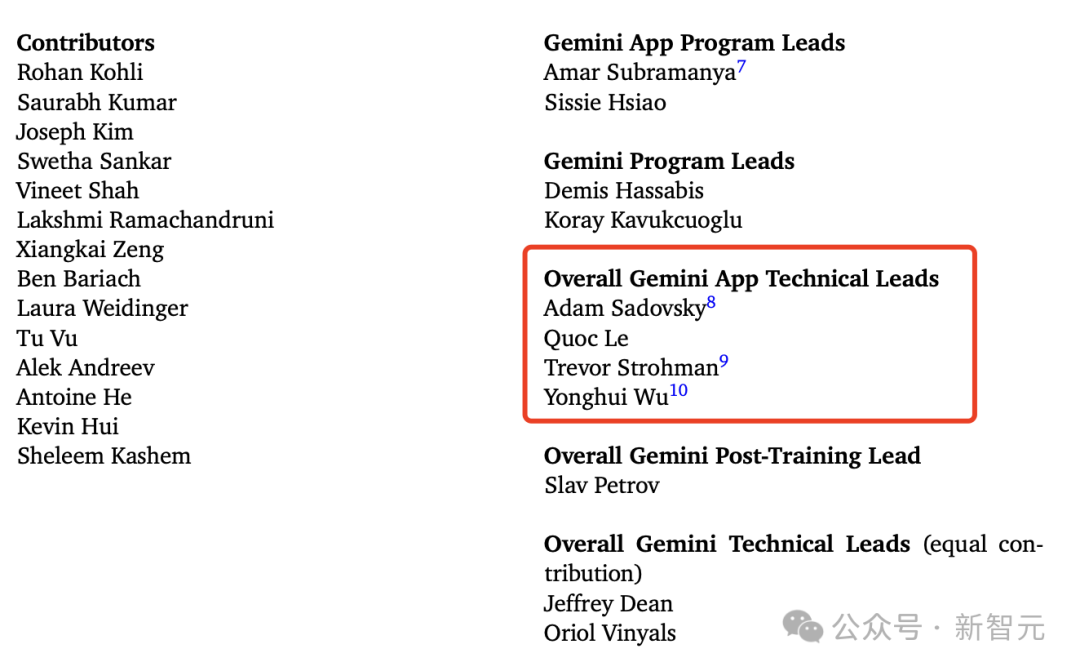
作為谷歌大牛,吳永輝參與了Gemini模型的開發,在團隊貢獻名單中,是Gemini應用總技術負責人之一。
他也參與了Gemini 1.5的研發,將大模型上下文擴展到100萬token。
論文地址:https://arxiv.org/pdf/2312.11805
他還是Palm 2大模型訓練團隊的核心貢獻者。

論文地址:https://arxiv.org/pdf/2305.10403
根據谷歌Scholar個人介紹,截至目前,吳永輝總被引數超5萬,h-index為72。
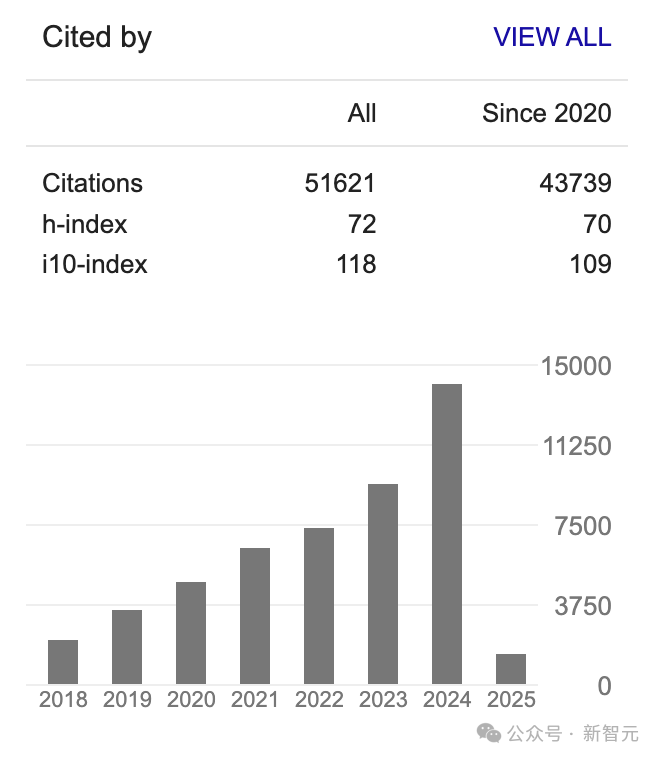
其中,被引數最高的文章便是2016年發表的——Google's Neural Machine Translation System。

論文地址:https://arxiv.org/pdf/1609.08144
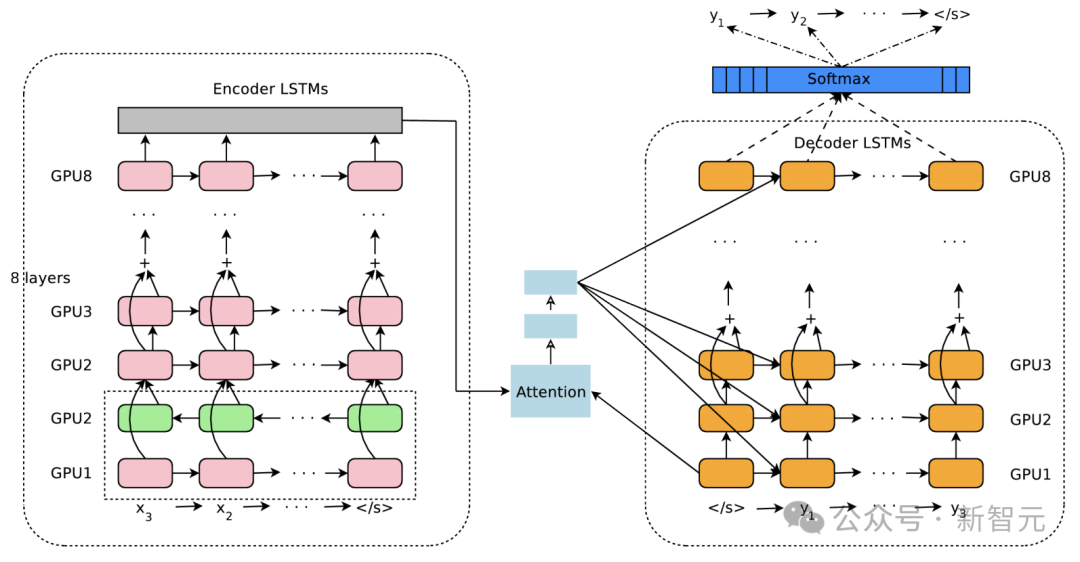
這篇論文主要提出了神經機器翻譯系統:GNMT,由一個深度LSTM網絡構成,包含8層編碼器和8層解碼器,使用了注意力機制和殘差連接。
為了提高并行性并縮短訓練時間,注意力機制將解碼器的底層連接到編碼器的頂層。
為了更好地處理稀有詞匯,作者還將詞匯分解為一組有限的常見子詞單元(wordpieces),同時用于輸入和輸出。這種方法在「字符」分隔模型的靈活性和「詞」分隔模型的高效性之間提供了良好的平衡,能夠自然處理稀有詞匯的翻譯,最終提高了系統的整體準確性。
在WMT’14 英語-法語和英語-德語基準測試中,通過對一組獨立簡單句子的人工對比評估,相比于谷歌基于短語的生產系統,GNMT將翻譯錯誤減少了60%。
其次,被引第二高是2020年發表的Conformer,一個語音識別模型,基于Transformer改進而來。
主要改進的點在于,提取長序列依賴的時候更有效,而卷積則擅長提取局部特征,因此將卷積應用于Transformer的Encoder層,同時提升模型在長期序列和局部特征上的效果。
實際證明,該方法確實有效,在當時的LibriSpeech測試集上取得了最好的效果。

























