













DeepSeek開源通用矩陣乘法庫,300行代碼加速V3、R1,R2被曝五月前問世
DeepSeek 的開源周已經進行到了第三天(前兩天報道見文末「相關閱讀」)。今天開源的項目名叫 DeepGEMM,是一款支持密集型和專家混合(MoE)GEMM 的 FP8 GEMM 庫,為 V3/R1 的訓練和推理提供了支持,在 Hopper GPU 上可以達到 1350+ FP8 TFLOPS 的計算性能。

具體來說,DeepGEMM 是一個旨在實現簡潔高效的 FP8 通用矩陣乘法(GEMM)的庫,它采用了 DeepSeek-V3 中提出的細粒度 scaling 技術。該庫支持普通 GEMM 以及專家混合(MoE)分組 GEMM。該庫采用 CUDA 編寫,在安裝過程中無需編譯,而是通過一個輕量級的 Just-In-Time(JIT)模塊在運行時編譯所有內核。
目前,DeepGEMM 僅支持英偉達 Hopper 張量核心。為了解決 FP8 張量核心累加不精確的問題,它采用了 CUDA 核心的兩級累加(提升)機制。盡管它借鑒了 CUTLASS 和 CuTe 的一些概念,但避免了對其模板或代數的重度依賴。相反,該庫的設計注重簡潔性,僅包含一個核心內核函數,代碼量僅為 300 行。這使其成為學習 Hopper FP8 矩陣乘法和優化技術的一個簡潔且易于獲取的資源。
盡管設計輕量,DeepGEMM 在各種矩陣形狀上的性能與專家調優的庫相當,甚至在某些情況下更優。

開源地址:https://github.com/deepseek-ai/DeepGEMM
早期試用者評價說,「DeepGEMM 聽起來就像是數學界的超級英雄。它比高速計算器還快,比多項式方程還強大。我試著用了一下,現在我的 GPU 都在炫耀它的 1350+ TFLOPS,仿佛已經準備好參加 AI 奧賽了!」

這個計算性能如果加上高質量的數據,沒準兒能貢獻更大的驚喜?
除了性能,「300 行代碼的性能超越了專家調優的內核」同樣讓不少人感到驚訝,有人認為「要么 DeepSeek 破解了 GPU 矩陣的奧秘,要么我們剛剛見證了最高等級的編譯器魔法。」

看來,DeepSeek 團隊里有一批掌握編譯器神秘技巧的頂級 GPU 工程師。
還有人評價說,「DeepGEMM 正在改變我們使用 FP8 GEMM 庫的方式,它簡潔、快速且開源。這正是 AI 計算的未來。」
在項目的貢獻者列表中,有人發現了一個姓 Liang 的工程師,難道是 DeepSeek 創始人梁文鋒(真實性有待考證)?

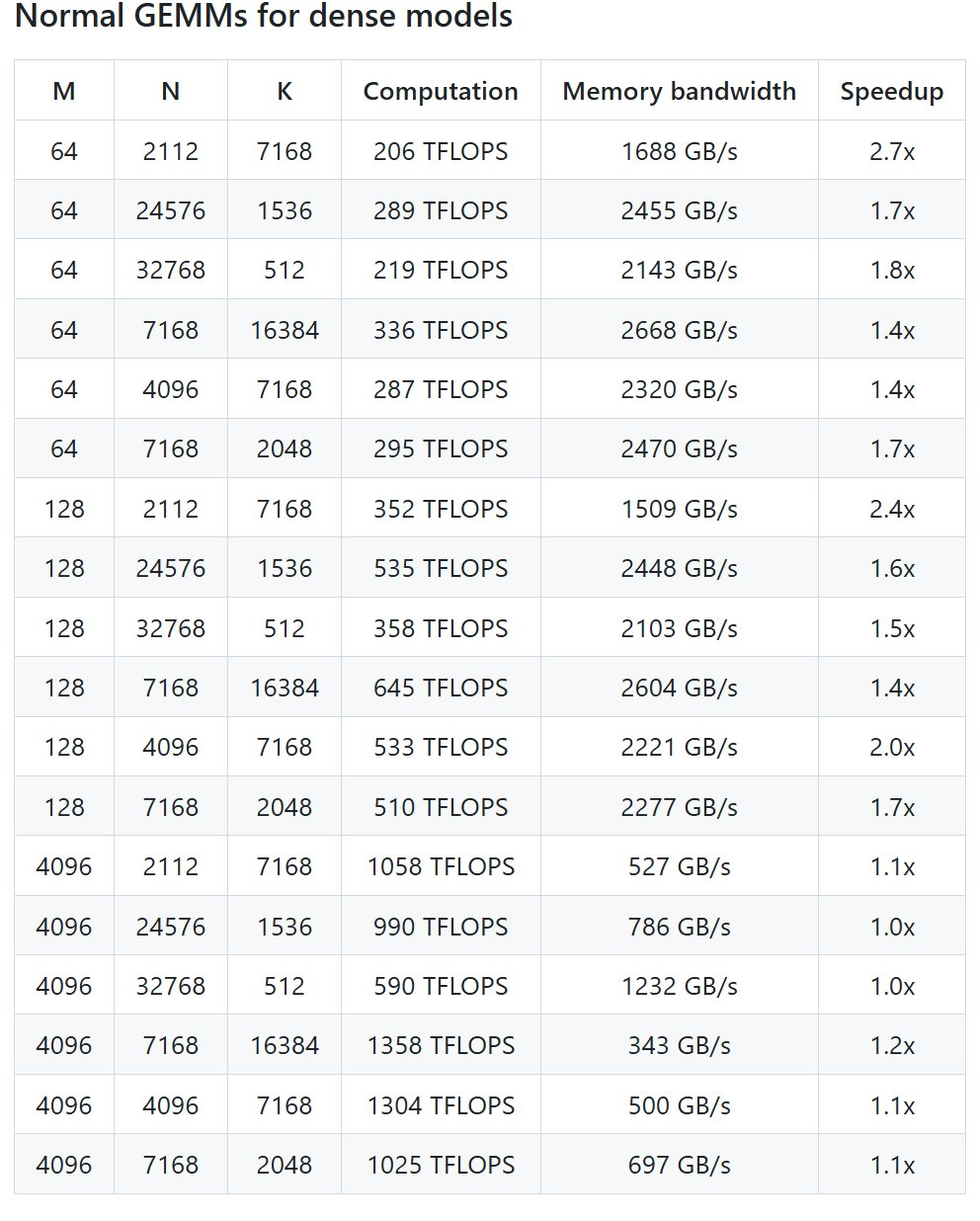
性能
DeepSeek 在 H800 上使用 NVCC 12.8 測試了 DeepSeek-V3/R1 推理中可能使用的所有形狀(包括預填充和解碼,但不包括張量并行),最高可以實現 2.7 倍加速。所有加速指標均基于內部精心優化的 CUTLASS 3.6 實現。
但根據項目介紹,DeepGEMM 在某些形狀上表現不佳。


快速啟動
首先需要這些配置
- Hopper 架構的 GPU,必須支持 sm_90a;
- Python 3.8 或更高版本;
- CUDA 12.3 或更高版本,但為了獲得最佳性能,DeepSeek 強烈推薦使用 12.8 或更高版本;
- PyTorch 2.1 或更高版本;
- CUTLASS 3.6 或更高版本(可通過 Git 子模塊克隆)。
配置完成后,就是部署:
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py然后是安裝:
python setup.py install最后在你的 Python 項目中導入 deep_gem,就可以使用了。
更多信息請參見 GitHub 開源庫。
路透社:DeepSeek R2 大模型又提前了,5 月之前發布
就在 DeepSeek 緊鑼密鼓地開源的同時,人們也在四處探尋該公司下一代大模型的信息。昨天晚上,路透社突然爆料說 DeepSeek 可能會在 5 月之前發布下一代 R2 模型,引發了關注。

據多位知情人士透露,DeepSeek 正在加速推出 R1 強推理大模型的后續版本。其中有兩人表示,DeepSeek 原本計劃在 5 月初發布 R2,但現在希望盡早發布。DeepSeek 希望新模型擁有更強大的代碼生成能力,并能夠推理除英語以外的語言。
可見在 Grok 3、Claude 3.7、Qwen 2.5-Max 等競品面世之后,DeepSeek 又加快了技術演進的步伐。
值得一提的是,媒體也介紹了該公司的一些情況。DeepSeek 在北京開設的辦公室距離清華、北大很近(步行可至)。據兩名前員工稱,梁文鋒經常會與工程師們深入研究技術細節,并樂于與實習生、應屆畢業生一起工作。他們還描述了通常在協作氛圍中每天工作八小時的情況。
據三位了解 DeepSeek 薪酬情況的人士稱,這幻方量化與 DeepSeek 都以薪酬豐厚而聞名。有人表示在幻方的高級數據科學家年薪 150 萬元人民幣并不罕見,而競爭對手的薪酬很少超過 80 萬元。
幻方是 AI 交易的早期先驅,一位該公司高管早在 2020 年表示將「All in」人工智能,將公司 70% 的收入投資于人工智能研究。該公司在 2020 年和 2021 年斥資 12 億元人民幣建設了兩個超級計算 AI 集群。第二個集群 Fire-Flyer II 由約一萬塊英偉達 A100 芯片組成,主要用于訓練 AI 模型。
在 DeepSeek V3、R1 模型推出之后,全世界對于 AI 技術的期待已經進入了高點。科技公司都在消化 DeepSeek 提出的新技術,修正發展方向,消費者們則紛紛開始嘗試各類生成式 AI 應用。
或許下一次 DeepSeek 的發布,會是 AI 行業的又一次關鍵時刻。


























