













DeepSeek 開源 V3/R1 架構設計思路,原來 545% 的利潤率,它也只是被逼無奈?
開源周的最后一天,DeepSeek分享了DeepSeek-V3/R1的架構設計思路,讓大家能夠更系統更全面的了解其推理系統的設計過程,以及更深刻的理解之前開源的6個項目。

DeepSeek-V3/R1推理系統的核心目標是什么?
通過軟件架構的優化,達到:
- 更高的吞吐量;
- 更低的延時;
為什么DeepSeek要走這一條路?
曾經AI技術發展,GPU就是瓶頸。
GPU是瓶頸的時候,有兩條路可走:
- 其一,水平擴展scale out:囤卡,堆GPU;
- 其二,垂直擴展scale up:GPU升級換代;
但這兩條路,都被死死的卡在漂亮國的手里。
卡,限制你,不讓你囤。
先進的卡,不賣給你,誰叫你你落后5年。
為了突破瓶頸,DeepSeek被逼無奈的走出了第三條路:通過軟件優化架構優化。
為了達成目標,DeepSeek的核心方案是啥?
大規模的跨節點專家并行EP,Expert Parallelism。
通過提升專家并行EP的數量(batch size),提升GPU矩陣乘法的效率,提高吞吐;與此同時,多專家分散在不同的GPU,每個GPU只需要計算更少的專家,訪問更少的數據,從而降低延遲。
大規模的跨節點專家并行EP,會對軟件架構帶來什么新的挑戰?
- EP跨節點傳輸,要解決傳輸與計算并行的問題;
- EP多節點聯動,要解決數據分發匯總,負載均衡等問題;
大規模的跨節點專家并行EP的部署與策略是怎么樣的?
由于V3/R1的專家數量眾多,并且每層256個專家中僅激活其中8個,DeepSeek采用多機多卡間的專家并行策略來達到以下目的:
- Prefill預填充階段:路由專家EP-32、MLA和共享專家DP-32,一個部署單元是4節點,32個冗余路由專家,每張卡9個路由專家和1個共享專家;
- Decode解碼階段:路由專家EP-144、MLA和共享專家DP-144,一個部署單元是18節點,32個冗余路由專家,每張卡2個路由專家和1個共享專家;
這兩個階段的負載均衡策略各不相同。
如何解決計算與傳輸并行的問題?
多機多卡的專家并行會引入比較大的通信開銷,所以DeepSeek使用雙向通道,提高整體吞吐。
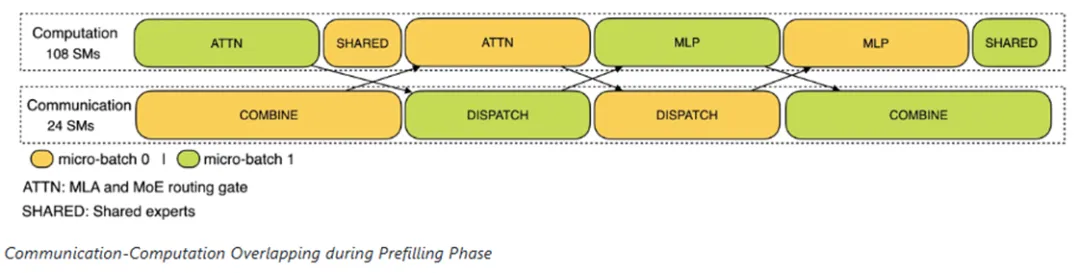
- 預填充階段:計算和通信交錯進行,一個通道計算的時候,另一個通道通信。
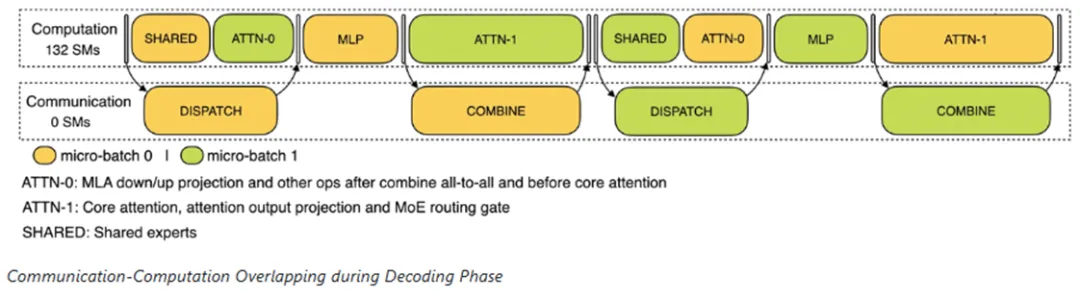
- 解碼階段類似:計算與通訊交錯進行,通過流水線來實現計算和通信的重疊。
如何最大程度的負載均衡?
由于采用了很大規模的數據并行與專家并行,如果某個GPU的計算或通信負載過重,單個長尾將成為整個系統的瓶頸。與此同時其他GPU因為等待而空轉,造成整體資源利用率下降。因此必須盡可能地為每個GPU平均分配計算負載、通信負載。
預填充階段(prefilling stage):
- 專家組分配到節點,保證節點負載均衡;
- 節點內復制專家;
- 專家分配到GPUs,保證GPUs負載均衡;
解碼階段(decoding stage):
- 全局復制專家,不管專家在哪個組;
- 專家分配到GPUs,保證GPUs負載均衡;
總而言之,保證負載均衡,充分發揮GPUs的潛力,提升訓練效率,縮短訓練時間。
其整體架構如下:

V3/R1的所有GPU均使用H800 GPU:
- 矩陣計算,分發:采用FP8格式;
- 核心注意力計算,合并:采用BF16格式;
同時兼顧效率與質量。
另外,由于白天的服務負荷高,晚上的服務負荷低,因此DeepSeek實現了一套機制:
- 在白天負荷高的時候,所有節點部署推理服務;
- 晚上負荷低的時候,減少推理節點,以用來做研究和訓練;
綜上所述,如果所有tokens全部按照R1的定價計算,理論上DeepSeek一天的總收入為$562,027,成本利潤率545%。
到這里,DeepSeek開源周的所有7個項目就寫完了,最后再來個匯總:
1. 《FlashMLA:GPU告訴解碼器》
2. 《DeepEP:MOE與EP通訊庫》
3. 《DeepGEMM:FP8通用矩陣乘法庫》
4. 《DualPipe:雙向管道并行算法》
5. 《EPLB:EP動態負載均衡算法》
6. 《3FS:高性能分布式文件系統》
7. 《V3/R1架構設計思路(本文)》
補充閱讀材料:https://github.com/deepseek-ai/
官方git,可參考。
























