ICLR 2025 | 西湖大學提出閉環擴散控制策略,高效與閉環兼得
本文來自西湖大學人工智能系的吳泰霖團隊。本文有兩位共同第一作者:魏龍是西湖大學人工智能系博士后,馮浩東是西湖大學博士生。通訊作者吳泰霖是西湖大學人工智能系特聘研究員,其領導的人工智能與科學仿真發現實驗室主要研究方向為開發生成模型方法并用于科學和工程領域的仿真、設計和控制。
高效閉環控制是復雜系統控制的核心要求。傳統控制方法受限于效率與適用性挑戰;而新興的擴散模型雖然表現出色,卻難以滿足高效閉環控制的要求。西湖大學研究團隊最新提出的 CL-DiffPhyCon 框架,通過異步并行去噪技術,在閉環控制要求下,顯著提升了控制效率和效果。論文最近被人工智能領域頂級會議 ICLR 2025 接收。

- 論文標題:CL-DiffPhyCon: Closed-loop Diffusion Control of Complex Physical Systems
- 論文鏈接:https://openreview.net/pdf?id=PiHGrTTnvb
- 代碼地址:https://github.com/AI4Science-WestlakeU/CL_DiffPhyCon
一、研究背景
在科學研究、工程實踐以及具身智能等諸多領域,系統控制問題都有著廣泛的應用。在這些場景中,高效閉環控制是核心性能要求。例如,當機器人在復雜環境中執行任務,必須對周圍環境變化做出即時反應。這就需要控制系統能夠根據環境實時反饋,迅速調整控制信號,保證每一個動作指令都基于最新的環境狀態生成。另外,工業制造、航空航天、能源生產等科學和工程領域的系統控制任務,同樣面臨著如何實現高效閉環控制的難題。
在過往的研究當中,涌現出了傳統控制方法,以及近年來的深度學習、強化學習、模仿學習等眾多控制方法。近期的 DiffPhyCon [1] 等研究表明,基于擴散模型 [2] 的方法在復雜物理系統控制中表現出色,尤其是對高維、長時間跨度的控制問題具有顯著的優勢,這主要源自于擴散模型擅長學習高維分布的特性。這類方法從離線收集的軌跡數據中學習一個去噪模型,從噪聲開始,利用去噪模型逐步去噪,產生控制信號。此外,基于擴散模型的策略在機器人操作任務中也具有優異的表現 [3]。
然而,現有的擴散控制方法在應用到閉環控制時,會遇到控制效果和效率難以平衡的缺陷。它們的模型窗口內所有物理時間步,都要經歷從純噪聲開始的完整去噪采樣過程。若每個物理時間窗口都照此采樣并將其中的最早控制信號用于控制,雖然能實現閉環控制,卻會帶來非常高昂的采樣成本。而且,這種方式還可能會破壞控制信號的時序一致性,影響整體控制性能。反之,如果為了提高采樣效率,每隔若干個物理時間步才進行一次完整采樣,又脫離了閉環控制的要求。
雖然近期有研究工作提出在線重新規劃策略(RDM)[4],自適應地確定何時重新規劃控制序列,但這種策略也不是真正意義上的閉環框架。它們往往需要額外的似然估計計算開銷,還依賴額外的超參數。面對不同任務場景,需要多次實驗來調試這些超參數,增加了應用難度和不確定性。
二、本文主要貢獻
針對現有擴散控制方法在閉環控制中遇到的上述問題,本論文提出了一種基于擴散模型的閉環控制方法 CL-DiffPhyCon,它能夠根據環境的實時反饋生成控制信號,實現了高效的閉環控制。該方法的核心思想是將擴散模型中的物理時間步和去噪過程解耦,允許不同的物理時間步呈現不同的噪聲水平,從而實現了控制序列的高效閉環生成。論文在 1D Burgers’方程控制和 2D 不可壓縮流體控制兩個任務上,驗證了 CL-DiffPhyCon 的顯著結果。
如下圖 1 中所示,該方法具有如下優勢:
- 高效采樣:CL-DiffPhyCon 通過異步去噪框架,能夠顯著減少采樣過程中的計算成本,提高采樣效率。與已有的擴散控制方法相比,CL-DiffPhyCon 能夠在更短的時間內生成高質量的控制信號。
- 閉環控制:CL-DiffPhyCon 實現了閉環控制,能夠根據環境的實時反饋不斷調整控制策略。相比已有的開環擴散控制方法,提高了控制效果。
- 加速采樣:此外,CL-DiffPhyCon 還能與 DDIM [5] 等擴散模型的加速采樣技術結合,在維持控制效果基本不變的前提下,進一步提升控制效率。

圖 1:本文的 CL-DiffPhyCon(右圖)相較于以往擴散控制方法(左圖和中圖)的優勢。通過采用異步去噪框架,該方法能夠實現閉環控制,并顯著加快采樣過程。其中,H表示擴散模型包含的物理時間窗口長度,DiffPhyCon - h表示每隔h個物理時間步進行一次包含T個去噪步驟的完整采樣過程,然后將采樣的控制信號序列中的前h個依次用于開環控制。這里沒有展示與 DDIM [5] 的結合。
三、問題設置和預備知識
1. 問題設置:
給定初始狀態 、系統動力學G以及特定的控制目標
、系統動力學G以及特定的控制目標 ,本文考慮如下復雜系統的控制問題:
,本文考慮如下復雜系統的控制問題:

這里, 和
和 分別是物理時間步
分別是物理時間步 時的系統狀態和外部控制信號,軌跡的長度為N。系統動力學G代表系統在外部控制信號下隨時間的狀態轉移規則。G可以是隨機性的,存在非零隨機噪聲
時的系統狀態和外部控制信號,軌跡的長度為N。系統動力學G代表系統在外部控制信號下隨時間的狀態轉移規則。G可以是隨機性的,存在非零隨機噪聲 ;也可以是確定性的,即
;也可以是確定性的,即 。為了讓問題設置更具一般性,狀態的演變只能通過實際測量來觀測,即假設G的表達形式不一定可以獲得。本文中關注閉環控制,意味著每個時間步的控制信號
。為了讓問題設置更具一般性,狀態的演變只能通過實際測量來觀測,即假設G的表達形式不一定可以獲得。本文中關注閉環控制,意味著每個時間步的控制信號 是從以當前狀態
是從以當前狀態 為條件的一個概率分布中采樣得到的。這區別于開環控制或者規劃(planning)方法,即每次規劃未來多個時間步的控制信號后,將其依次應用到環境中,并且在此期間不利用環境反饋進行重新規劃。
為條件的一個概率分布中采樣得到的。這區別于開環控制或者規劃(planning)方法,即每次規劃未來多個時間步的控制信號后,將其依次應用到環境中,并且在此期間不利用環境反饋進行重新規劃。
2. 預備知識:DiffPhyCon 簡介
DiffPhyCon [1] 是近期發表的一種基于擴散模型的規劃(planning)方法。它提前規劃一個物理時間窗口(horizon) 內所有的控制信號,并依次將其用于系統的控制過程。為了記號方便,引入變量
內所有的控制信號,并依次將其用于系統的控制過程。為了記號方便,引入變量 表示第
表示第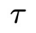 物理時間步系統狀態和控制信號的拼接。該方法包含以下過程:
物理時間步系統狀態和控制信號的拼接。該方法包含以下過程:
- 首先離線收集大量的軌跡數據,每條軌跡包括初始狀態、控制序列和相應的狀態序列。
- 然后,用這些離線軌跡訓練一個去噪步數為T,物理時間窗口為N的擴散模型,并將所有物理時刻的系統狀態和控制信號的聯合隱變量
 作為擴散變量。這里在記號
作為擴散變量。這里在記號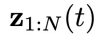 中,用下角標表示物理時間
中,用下角標表示物理時間 或其所處的區間,用括號里的t表示擴散步驟。在擴散過程中,隨著t增大,
或其所處的區間,用括號里的t表示擴散步驟。在擴散過程中,隨著t增大, 中的噪聲程度逐漸增加:
中的噪聲程度逐漸增加: 不含噪聲,
不含噪聲, 為高斯噪聲。
為高斯噪聲。 - 在去噪過程(實際控制過程)中,以系統的初始狀態
 為條件,利用訓練的擴散模型,在控制目標
為條件,利用訓練的擴散模型,在控制目標 的梯度引導下,讓t從T 降到 0,將高斯噪聲
的梯度引導下,讓t從T 降到 0,將高斯噪聲 逐步去噪為不含噪聲的
逐步去噪為不含噪聲的 ,其中包含控制序列
,其中包含控制序列 和對應產生的狀態序列
和對應產生的狀態序列 。
。 - 最后,將控制序列
 逐步輸入到環境中,實現對系統的控制。
逐步輸入到環境中,實現對系統的控制。
上述過程中隱藏了一個假設:軌跡長度N 較小,這時H 取值為N。而實際問題中更為常見的情形是N 很大,這導致物理時間窗口為N的擴散模型難以在 GPU 中運行或者物理時間跨度太大導致偏離閉環要求過遠。這就需要訓練一個時間窗口相對較小(H<N)的擴散模型,然后每隔h個物理時間步進行一次完全的去噪過程,或者以自適應的方式確定何時重新規劃控制序列 [4],如圖 1 左邊和中間子圖所示。
四、CL-DiffPhyCon 方法介紹
該方法考慮的也是H<N的情形。關鍵想法是:將擴散模型的模型時間窗口內的物理時間和擴散(去噪)過程解耦,越早的物理時間賦予越快的去噪進度,也就是越低的噪聲程度。如此一來,既實現了不同物理時間步的并行采樣,提高了采樣效率;又能讓更早采樣到的控制信號所產生的環境反饋用于后續物理時間的控制信號采樣,實現了閉環控制。
為了方便,本文首先引入了如下兩個記號:
- 同步聯合隱變量:
 表示在物理時間區間
表示在物理時間區間 內,對每個分量加入相同程度噪聲。這里t的取值范圍是 0 到T。
內,對每個分量加入相同程度噪聲。這里t的取值范圍是 0 到T。 - 異步聯合隱變量:
 表示在物理時間區間
表示在物理時間區間 內,為越晚的物理時間賦予越高的噪聲程度,即實現了物理時間和去噪進度的解耦。這里t的取值范圍是 0 到
內,為越晚的物理時間賦予越高的噪聲程度,即實現了物理時間和去噪進度的解耦。這里t的取值范圍是 0 到 。
。
針對這兩種變量,本文訓練了兩個擴散模型:同步擴散模型 和異步擴散模型
和異步擴散模型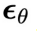 。
。
1. 同步擴散模型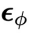 :
:
這個模型預測同步聯合隱變量 當中每個分量包含的噪聲。它只用于
當中每個分量包含的噪聲。它只用于 的物理時刻。訓練損失如下:
的物理時刻。訓練損失如下:

訓練這個模型的目的,是為了采樣異步聯合隱變量 ,這是物理時間上最早的異步聯合隱變量。采樣方法如下:對于給定的初始條件
,這是物理時間上最早的異步聯合隱變量。采樣方法如下:對于給定的初始條件 ,類似于 DiffPhyCon 的去噪過程,從高斯噪聲
,類似于 DiffPhyCon 的去噪過程,從高斯噪聲 開始,讓t從T逐步減少到
開始,讓t從T逐步減少到 ,在每步迭代中,從
,在每步迭代中,從 當中減去
當中減去 預測的噪聲,同時減去控制目標
預測的噪聲,同時減去控制目標 的梯度。這樣就采樣得到了一系列同步聯合隱變量
的梯度。這樣就采樣得到了一系列同步聯合隱變量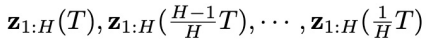 。再從其中取 “對角線”,就能得到初始的異步聯合隱變量
。再從其中取 “對角線”,就能得到初始的異步聯合隱變量 (圖 2 的 (2) 子圖中的虛線紅框)。
(圖 2 的 (2) 子圖中的虛線紅框)。
2. 異步擴散模型 :
:
這個模型預測隱變量 中每個分量包含的噪聲。它用于
中每個分量包含的噪聲。它用于 的所有物理時刻。它的訓練損失如下:
的所有物理時刻。它的訓練損失如下:

訓練這個模型的目的,是為了在給定第 個物理時刻的系統狀態
個物理時刻的系統狀態 和異步聯合隱變量
和異步聯合隱變量 的條件下,采樣
的條件下,采樣 ,即實現解耦的異步去噪。采樣方法如下:從
,即實現解耦的異步去噪。采樣方法如下:從 開始,讓t從
開始,讓t從 逐步減少到 0,在每一步中,從
逐步減少到 0,在每一步中,從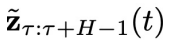 當中逐分量減去
當中逐分量減去 預測的噪聲,同時減去控制目標
預測的噪聲,同時減去控制目標 的梯度,最終得到
的梯度,最終得到 。
。
3. 閉環控制過程
基于以上兩個訓練好的擴散模型,閉環控制的循環過程如下(分別對應圖 2 中從左向右 4 個子圖):
- 第(1)步:在第
 個物理時間步,獲得物理時間窗口
個物理時間步,獲得物理時間窗口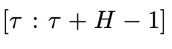 內的初始狀態
內的初始狀態 和系統狀態
和系統狀態 。特別地,當
。特別地,當 時,通過上文的同步擴散模型
時,通過上文的同步擴散模型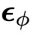 采樣得到
采樣得到 。
。 - 第(2)步:以
 為采樣條件,利用異步擴散模型
為采樣條件,利用異步擴散模型 ,從
,從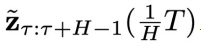 開始連續采樣
開始連續采樣 步,得到
步,得到 。
。 - 第(3)步:將
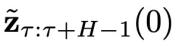 的第 1 個分量
的第 1 個分量 中包含的控制信號
中包含的控制信號 輸入到環境中,得到下一個狀態
輸入到環境中,得到下一個狀態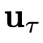 。
。 - 第(4)步:采樣一個高斯噪聲
 ,拼接到第(2)步采樣得到的
,拼接到第(2)步采樣得到的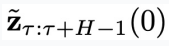 的最后
的最后 個分量的結尾,得到物理時間窗口
個分量的結尾,得到物理時間窗口 內的初始狀態
內的初始狀態 ,同時將
,同時將 作為條件,進入下一個物理時間步
作為條件,進入下一個物理時間步 。
。

圖 2:CL-DiffPhyCon 用于閉環控制的流程:(1) 獲取當前物理時刻系統狀態和 “對角線形” 異步聯合隱變量;(2) 利用異步擴散模型去噪;(3) 將采樣到的控制信號應用到系統;(4) 獲取系統反饋的最新狀態和更新后的 “對角線形” 異步聯合隱變量,進入到下一個物理時刻。
4. 與擴散模型加速采樣技術的結合
值得一提的是,CL-DiffPhyCon 還可與擴散模型領域的快速采樣技術相結合,進一步提升采樣效率。例如,DDIM [5] 通過特定的采樣策略減少了采樣步數,在不損失太多采樣質量的前提下加快了采樣速度。在 CL-DiffPhyCon 的同步和異步模型的采樣過程中引入 DDIM,能夠使得 CL-DiffPhyCon 在保持控制性能基本不變的前提下,以更快的速度完成采樣和控制信號生成,從而在實際應用中更具優勢。論文通過實驗結果驗證了這一點,這說明 CL–DiffPhyCon 具有和已有的擴散模型領域加速采樣方法相獨立的加速效果。
四、CL-DiffPhyCon 理論分析
論文還從理論上分析了為何需要學習以上兩個擴散模型。論文的目標是對聯合分布 進行建模,并在控制目標的引導下采樣。本文將如下的增廣 (augmented) 聯合分布作為分析的出發點:
進行建模,并在控制目標的引導下采樣。本文將如下的增廣 (augmented) 聯合分布作為分析的出發點:

如果我們能夠采樣這個增廣聯合分布中的所有隨機變量,那么自然也就得到了 (包含于
(包含于 )。而之所以要研究這個增廣聯合分布,是因為它指引著我們讓
)。而之所以要研究這個增廣聯合分布,是因為它指引著我們讓 變得 “可被采樣”。論文研究發現,這個看似復雜的增廣聯合分布其實具有一個有趣的規律:假設聯合分布
變得 “可被采樣”。論文研究發現,這個看似復雜的增廣聯合分布其實具有一個有趣的規律:假設聯合分布 滿足 Markov 性質(這是強化學習等決策類問題中常見的假設),那么從增廣聯合分布中采樣的問題,就可以轉化為只從兩類分布中采樣的問題:即先從一個初始分布
滿足 Markov 性質(這是強化學習等決策類問題中常見的假設),那么從增廣聯合分布中采樣的問題,就可以轉化為只從兩類分布中采樣的問題:即先從一個初始分布 中采樣得到
中采樣得到 ,再從一個轉移分布
,再從一個轉移分布 中依次采樣,得到一系列
中依次采樣,得到一系列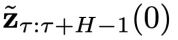 (
( )。具體地,該采樣過程可以用如下定理描述:
)。具體地,該采樣過程可以用如下定理描述:

所以,這里采用了 “先繁再簡” 的分析策略,為復雜的分布加入了采樣的可行性。這個定理還傳遞出另一個重要的性質:在每個物理時刻采樣控制變量 時,所依賴的系統狀態
時,所依賴的系統狀態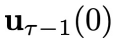 可以從環境反饋中得到。這是因為我們已經采樣得到了上一個時刻的控制變量
可以從環境反饋中得到。這是因為我們已經采樣得到了上一個時刻的控制變量 ,因此可以立即將其輸入到環境中,得到環境反饋的
,因此可以立即將其輸入到環境中,得到環境反饋的 。也就是說,這個采樣過程能夠滿足閉環控制的要求。
。也就是說,這個采樣過程能夠滿足閉環控制的要求。
仔細觀察就會發現,上一節中學習的兩個擴散模型恰好對應兩個分布:即同步擴散模型 的作用是從
的作用是從 中采樣,而異步擴散模型
中采樣,而異步擴散模型 的作用是從
的作用是從 中采樣。所以,我們只需要這兩個擴散模型就能夠實現從軌跡數據分布中采樣,再通過在采樣過程中加入控制目標的梯度引導,就可以優化控制目標。
中采樣。所以,我們只需要這兩個擴散模型就能夠實現從軌跡數據分布中采樣,再通過在采樣過程中加入控制目標的梯度引導,就可以優化控制目標。
五、實驗結果
1. 實驗設置
借鑒 DiffPhyCon [1] 論文中的實驗設置,這篇論文在兩個具有挑戰性的控制任務上進行了實驗:
(1)一維 Burgers 方程控制:通過控制外力項,使系統的最終狀態與目標狀態一致。
(2)二維煙霧間接控制:通過間接控制外部力場,最小化從非目標出口逸出的污染物比例。
在一維 Burgers 方程控制實驗中,考慮了 6 種實際場景,如無噪聲控制、物理約束下的控制、存在系統和測量噪聲時的控制,以及部分區域可控制(包括全部區域可觀測和部分區域可觀測兩種細分場景)等。在二維煙霧間接控制任務中,設置了大范圍區域控制和邊界控制 2 種場景,每種又細分為固定障礙物地圖和隨機障礙物地圖兩種環境模式,以檢驗方法的泛化能力。
對比方法包括一系列經典控制方法、模仿學習、強化學習和擴散控制方法,如 PID、行為克隆(BC)、BPPO、自適應重規劃擴散控制(RDM)以及 DiffPhyCon 等,并對這些基線方法進行了適當調整,以保證公平比較。由于兩個實驗中的軌跡較長,研究人員將 DiffPhyCon 擴展為三個版本:DiffPhyCon-h(h∈{1,5,H - 1})。這里的 DiffPhyCon - h表示每隔h個物理時間步進行一次 DiffPhyCon 的完整采樣過程,然后將采樣的控制信號序列中的前h個用于開環控制(見上文圖 1)。
2. 實驗結果
在一維 Burgers’方程控制任務中,CL–DiffPhyCon 在 6 種場景下控制效果均優于所有對比方法。與控制效果最佳的對比方法 DiffPhyCon-1 相比,CL-DiffPhyCon 在無噪聲和帶有物理約束的設置中,使控制目標分別降低了 54.3% 和 48.6%;在兩種噪聲的情況下,控制目標分別降低了 48.6% 和 57.2%;在部分區域可控制場景中,控制目標分別降低了 11.8% 和 11.1%。在采樣效率上,CL-DiffPhyCon 相比每個 DiffPhyCon-h 快了約 H/h 倍(h∈{1,5,15}),也比自適應重規劃擴散控制(RDM [4])快兩倍。結合 DDIM 采樣后,加速效果更明顯,進一步實現了 5 倍的加速,且控制效果保持相當。
表 1. 一維 Burgers’方程控制任務上的實驗結果對比。

在二維煙霧間接控制中,CL-DiffPhyCon 同樣表現優異,在 4 種場景設置中,效果均優于對比方法。在采樣效率方面,CL-DiffPhyCon 比 DiffPhyCon-h 實現了約 H/h h∈{1,5,14} 倍的加速,并且比 RDM 更高效。結合 DDIM 后,推理速度進一步加快,比 RDM 快 5 倍以上。
表 2. 二維煙霧間接控制任務上的實驗結果對比。


圖 3. 在固定地圖(上圖)和隨機地圖(下圖)兩種環境下,CL-DiffPhyCon 與表現最好的對比方法在二維煙霧間接控制上的可視化對比。橫向表示不同物理時刻。控制目標 J 越低,表示控制效果越好。
六、總結與展望
CL-DiffPhyCon 為高效閉環控制提供了一種創新解決方案。通過實驗驗證,證明了其具有兼得優良的控制效果和高效的采樣效率的顯著優勢。不過,研究人員也指出,該方法仍有提升空間。目前 CL-DiffPhyCon 是基于離線數據訓練的,未來可以考慮在訓練過程中融入環境實時反饋,探索多樣的控制策略。此外,雖然兩個擴散模型是基于對目標分布的理論分析推出,但在引導采樣下得到的樣本與最優解的誤差界仍是一個開放問題,值得進一步深入研究。
從應用前景來看,CL-DiffPhyCon 不僅適用于這篇論文的復雜物理系統控制任務,在機器人控制、無人機控制等領域也具有廣闊的應用潛力。隨著研究的不斷深入和技術的持續進步,CL-DiffPhyCon 將不斷完善,為更廣泛領域的控制問題提供有益的解決方案。