巧用 CAS,一分鐘實現分布式 ID 生成器!
作者:架構師之路
有同學留言,CAS還有其他應有場景嗎?場景很多,今天分享一個巧用CAS實現分布式全局唯一ID生成的場景。
有童鞋留言,CAS還有其他應有場景嗎?
場景很多,今天分享一個巧用CAS實現分布式全局唯一ID生成的場景。
如何快速生成全局唯一ID?
可以借助DB自增鍵(auto inc id),插入一條記錄,生成一個ID:

這個方案復用了數據庫的特性,其優點為:
- 無需寫額外代碼;
- 全局唯一;
- 絕對遞增;
- 遞增ID的步長確定;
業務早期“并發量小”,追求“快速實現”,這么玩沒問題。
這種方案有什么缺點?
- 數據庫中記錄數較多;
- 生成ID的性能,取決于數據庫插入性能;
- 并發量大了,數據庫扛不住;
可以怎么優化?
- DB只保留max-id一條記錄;
- 增加一層服務,采用批量生成的方式降低數據庫的寫壓力,提升整體性能;
更具體的操作如下:
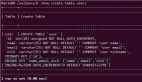
步驟一,id-s服務首先拉取當前的max-id。

select max_id from T;步驟二,批量獲取一批ID,放到id-s內存里,并將max-id寫回數據庫。

update T set max_id=200;如上圖所示,id-s拿到了[100, 200]這一批ID,上游在獲取ID時,不用每次都插入數據庫,而是分配完100個ID后,再修改max-id的值,這樣分配ID的整體性能就增加了100倍。
這種方案還有什么缺點?
服務沒有做HA,無法保證高可用。需要冗余服務,做集群保證高可用。
冗余服務可能帶來什么新的問題?
和高并發庫存扣減出現的問題類似,冗余了服務后,多個服務在啟動過程中,進行ID批量申請時,可能由于并發導致數據不一致。

select max_id from T;步驟一:兩個id-s同時拿到了max-id為100;

update T set max_id=200;步驟二:兩個id-s同時對數據庫的max-id進行寫回;
寫回max-id成功后,這兩個id-s都以為自己拿到了[100,200]這一批ID,導致集群會生成重復的ID。
導致bug的原因在哪里?
是并發寫回時,沒有對max-id的初始值進行比對:
- id-s1寫回max-id=200成功的條件是,max-id必須等于100;
- id-s2寫回max-id=200成功的條件是,max-id也必須等于100;
而實際情況是:
- id-s1寫回時,max-id是100,理應寫回成功;
- id-s2寫回時,max-id已經被改成了200,不應該寫回成功;
如何巧用CAS修復?
在寫回時對max-id的初始條件進行比對,就能避免數據的不一致,寫回SQL由:
update T set max_id=200;升級為:
update T set max_id=200
where max_id=100;升級之后,s1和s2只會有一個成功。另一個失敗之后,重新查詢數據庫得到新的max-id為200,再次申請[200,300]的ID,就能夠成功。
CAS優化方案的優點是:
- 能夠通過水平擴展的方式,達到分布式ID生成服務的無限性能;
- 方案簡潔性;
- 保證不會生成重復的ID;
知其然,知其所以然。
思路比結論更重要。
責任編輯:趙寧寧
來源:
架構師之路