YOLOe問(wèn)世,實(shí)時(shí)觀察一切,統(tǒng)一開(kāi)放物體檢測(cè)和分割
它能像人眼一樣,在文本、視覺(jué)輸入和無(wú)提示范式等不同機(jī)制下進(jìn)行檢測(cè)和分割。
自 2015 年由華盛頓大學(xué)的 Joseph Redmon 研究團(tuán)隊(duì)提出 YOLO(You Only Look Once)以來(lái),這項(xiàng)突破性的目標(biāo)檢測(cè)技術(shù)就像為機(jī)器裝上了「閃電之眼」,憑借單次推理的實(shí)時(shí)性能刷新了計(jì)算機(jī)視覺(jué)的認(rèn)知邊界。
傳統(tǒng)的 YOLO 系列如同我們?nèi)斯ば?zhǔn)的精密儀器,其識(shí)別能力被嚴(yán)格框定在預(yù)定義的類(lèi)別目錄之中,每個(gè)檢測(cè)框的背后,都需要工程師手動(dòng)輸入認(rèn)知詞典。這種預(yù)設(shè)規(guī)則在開(kāi)放場(chǎng)景中限制了視覺(jué)模型的靈活性。
但是在萬(wàn)物互聯(lián)的時(shí)代,行業(yè)迫切需要更接近人類(lèi)視覺(jué)的認(rèn)知范式 —— 不需要預(yù)先設(shè)定先驗(yàn)知識(shí),卻能通過(guò)多模態(tài)提示理解大千世界。那么如何通過(guò)視覺(jué)模型來(lái)實(shí)現(xiàn)這一目標(biāo)呢?
近來(lái),研究者們積極探索讓模型泛化至開(kāi)放提示的方法,力圖讓模型擁有如同人眼般的強(qiáng)大能力。不管是面對(duì)文本提示、視覺(jué)提示,甚至在無(wú)提示的情況下,模型都能借助區(qū)域級(jí)視覺(jué)語(yǔ)言預(yù)訓(xùn)練,實(shí)現(xiàn)對(duì)任意類(lèi)別的精準(zhǔn)識(shí)別。

- 論文標(biāo)題:YOLOE:Real-Time Seeing Anything
- 論文地址:https://arxiv.org/abs/2503.07465
- 技術(shù)展示頁(yè):https://github.com/THU-MIG/yoloe?tab=readme-ov-file#demo
YOLOE 的設(shè)計(jì)思路
在 YOLO 的基礎(chǔ)之上,YOLOE 通過(guò) RepRTA 支持文本提示、通過(guò) SAVPE 支持視覺(jué)提示以及使用 LRPC 支持無(wú)提示場(chǎng)景。

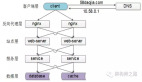
圖 1.YOLOE 的架構(gòu)
如圖 1 所示,YOLOE 采用了典型的 YOLO 架構(gòu),包括骨干、PAN、回歸頭、分割頭和對(duì)象嵌入頭。骨干和 PAN 為圖像提取多尺度特征。對(duì)于每個(gè)錨點(diǎn),回歸頭預(yù)測(cè)用于檢測(cè)的邊界框,分割頭生成用于分割的原型和掩碼系數(shù)。對(duì)象嵌入頭遵循 YOLO 中分類(lèi)頭的結(jié)構(gòu),只是最后一個(gè) 1× 卷積層的輸出通道數(shù)從閉集場(chǎng)景中的類(lèi)數(shù)更改為嵌入維度。同時(shí),給定文本和視覺(jué)提示,YOLOE 分別使用 RepRTA 和 SAVPE 將它們編碼為規(guī)范化的提示嵌入 P。
在開(kāi)放集場(chǎng)景中,文本和對(duì)象嵌入之間的對(duì)齊決定了識(shí)別類(lèi)別的準(zhǔn)確性。先前的研究通常引入復(fù)雜的跨模態(tài)融合來(lái)改進(jìn)視覺(jué)文本表示以實(shí)現(xiàn)更好的對(duì)齊。然而,這些方法會(huì)產(chǎn)生大量的計(jì)算開(kāi)銷(xiāo)。鑒于此,作者提出了可重新參數(shù)化的區(qū)域文本對(duì)齊 (RepRTA) 策略,通過(guò)可重新參數(shù)化的輕量級(jí)輔助網(wǎng)絡(luò)在訓(xùn)練過(guò)程中改進(jìn)預(yù)訓(xùn)練的文本嵌入。文本和錨點(diǎn)對(duì)象嵌入之間的對(duì)齊可以在零推理和傳輸成本的情況下得到增強(qiáng)。
接下來(lái)是語(yǔ)義激活的視覺(jué)提示編碼器。為了生成視覺(jué)提示嵌入,先前的工作通常采用 Transformer 設(shè)計(jì),例如可變形注意或附加 CLIP 視覺(jué)編碼器。然而,由于運(yùn)算符復(fù)雜或計(jì)算要求高,這些方法在部署和效率方面帶來(lái)了挑戰(zhàn)。
考慮到這一點(diǎn),研究人員引入了語(yǔ)義激活的視覺(jué)提示編碼器(SAVPE)來(lái)高效處理視覺(jué)提示。它具有兩個(gè)解耦的輕量級(jí)分支:(1) 語(yǔ)義分支在 D 通道中輸出與提示無(wú)關(guān)的語(yǔ)義特征,而無(wú)需融合視覺(jué)提示的開(kāi)銷(xiāo);(2) 激活分支通過(guò)在低成本下在更少的通道中將視覺(jué)提示與圖像特征交互來(lái)產(chǎn)生分組的提示感知權(quán)重。然后,它們的聚合會(huì)在最小復(fù)雜度下產(chǎn)生信息豐富的提示嵌入。
在沒(méi)有明確指導(dǎo)的無(wú)提示場(chǎng)景中,模型需要識(shí)別圖像中所有有名稱(chēng)的物體。先前的研究通常將這種設(shè)置表述為生成問(wèn)題,使用語(yǔ)言模型為密集的發(fā)現(xiàn)物體生成類(lèi)別。然而,其中語(yǔ)言模型遠(yuǎn)不能滿足高效率要求。YOLOE 將這種設(shè)置表述為檢索問(wèn)題并提出惰性區(qū)域提示對(duì)比(Lazy Region-Prompt Contrast,LRPC)策略。它以高效的方式從內(nèi)置的大型詞匯表中惰性檢索帶有物體的錨點(diǎn)的類(lèi)別名稱(chēng)。這種范例對(duì)語(yǔ)言模型的依賴為零,同時(shí)具有良好的效率和性能。
實(shí)驗(yàn)結(jié)果
那么在實(shí)驗(yàn)測(cè)試中,YOLOE 的效果如何呢?
作者將 YOLOE 基于 YOLOv8 和 YOLOv11 架構(gòu)開(kāi)展了實(shí)驗(yàn),并提供了不同的模型尺度。如下表所示,對(duì)于 LVIS 上的檢測(cè),YOLOE 在不同模型尺度上表現(xiàn)出效率和零樣本性能之間的良好平衡。

表 1. LVIS 上的零樣本檢測(cè)評(píng)估
實(shí)驗(yàn)結(jié)果表明 YOLOE 的訓(xùn)練時(shí)間少于其他對(duì)比模型,比 YOLO-Worldv2 快了近 3 倍。同時(shí) YOLOE-v8-S/M/L 的性能比 YOLOv8-Worldv2-S /M/L 分別高出 3.5/0.2/0.4AP,在 T4 和 iPhone 12 上的推理速度分別提高 1.4 倍 / 1.3 倍 / 1.3 倍和 1.3 倍 / 1.2 倍 / 1.2 倍。
不過(guò)在 Ap 指標(biāo)上,與 YOLO - Worldv2 相比,YOLOE-v8-M/L 稍顯遜色。進(jìn)一步分析發(fā)現(xiàn),這種性能差距主要是由于 YOLOE 創(chuàng)新性地在一個(gè)模型中集成了檢測(cè)和分割功能。
作者還通過(guò)以下角度驗(yàn)證了模型和方法的有效性:
- 分割評(píng)估

表 2. LVIS 上的分割評(píng)估
- 無(wú)提示詞評(píng)估

表 3. LVIS 上的無(wú)提示詞評(píng)估
- 可遷移性評(píng)估

表 4. 在 COCO 上的可遷移性測(cè)試,測(cè)試了兩種微調(diào)策略,線性探測(cè)和完全調(diào)整
這些結(jié)果充分證明,YOLOE 擁有強(qiáng)大的功能和高效率,適用于各種提示方式,可以實(shí)時(shí)看到任何東西。

此外,研究人員對(duì) YOLOE 開(kāi)展了四種場(chǎng)景的可視化分析:
- 圖 (a):在 LVIS 上進(jìn)行零樣本推理,以類(lèi)別名稱(chēng)作為文本提示
- 圖 (b):可輸入任意文本作為提示
- 圖 (c):能繪制視覺(jué)線索作為提示
- 圖 (d):無(wú)明確提示,模型自動(dòng)識(shí)別所有對(duì)象
結(jié)果顯示,YOLOE 在這些不同場(chǎng)景下均表現(xiàn)出色,能準(zhǔn)確檢測(cè)和分割各類(lèi)物體,進(jìn)一步體現(xiàn)了其在多種應(yīng)用中的有效性與實(shí)用性。