













CVPR 2025 | VAST和北航開源MIDI,從單張圖像端到端生成三維組合場景
本文的主要作者來自 VAST、北京航空航天大學、清華大學和香港大學。本文的第一作者為北京航空航天大學碩士生黃澤桓,主要研究方向為生成式人工智能和三維視覺。本文的通訊作者為 VAST 首席科學家曹炎培和北京航空航天大學副教授盛律。
在 Sora 引爆世界模型技術革命的當下,3D 場景作為物理世界的數字基座,正成為構建動態可交互 AI 系統的關鍵基礎設施。當前,單張圖像生成三維資產的技術突破,已為三維內容生產提供了 "從想象到三維" 的原子能力。
然而,當技術演進到組合式場景生成維度時,單物體生成范式的局限性開始凸顯:現有方法生成的 3D 資產如同散落的 "數字原子",難以自組織成具有合理空間關系的 "分子結構"。這導致幾個核心挑戰:① 實例分離困境(如何從單視圖準確解耦交疊物體)② 物理約束建模(如何避免穿模的不合理交互)③ 場景級語義理解(如何保持物體功能與空間布局的一致性)。這些瓶頸嚴重制約著從 "數字原子" 到 "可交互世界" 的構建效率。
最近,來自北航、VAST 等機構的研究團隊推出了全新的模型 —— MIDI,它能夠從單張圖像生成高幾何質量、實例可分離的 3D 組合場景,在單視圖 3D 場景生成領域取得了突破性進展,為可交互世界生成奠定基礎。

- 論文鏈接:https://arxiv.org/abs/2412.03558
- 項目主頁:https://huanngzh.github.io/MIDI-Page/
- 代碼倉庫:https://github.com/VAST-AI-Research/MIDI-3D
- 在線 Demo:https://huggingface.co/spaces/VAST-AI/MIDI-3D
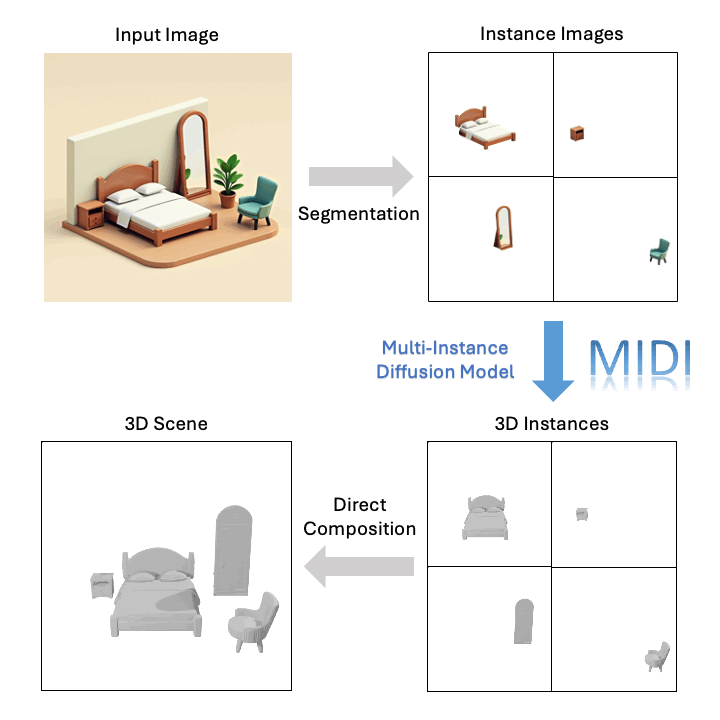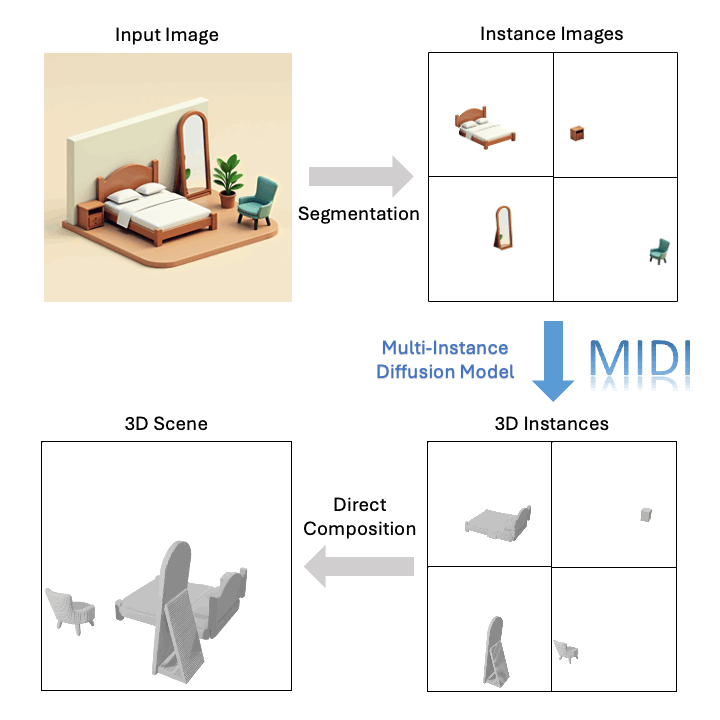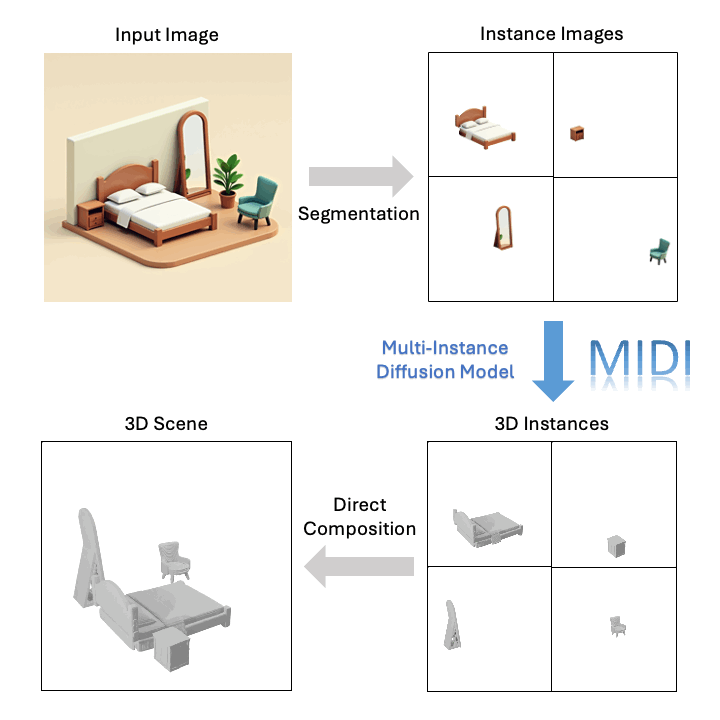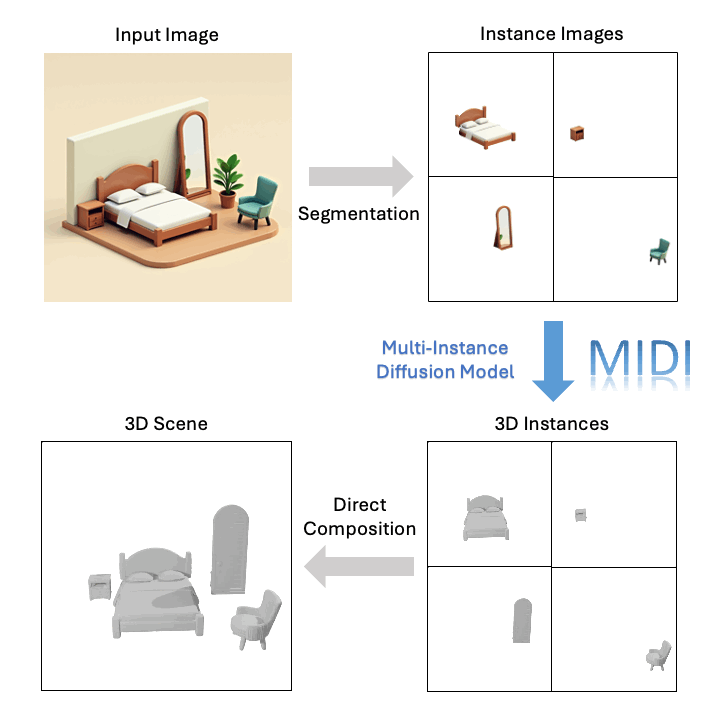
技術突破:從單張圖像到三維組合場景的關鍵創新
傳統的組合式 3D 場景重建技術往往依賴于多階段的逐個物體生成和場景優化,流程冗長且生成的場景往往幾何質量低、空間布局不準確。為解決這些問題,MIDI (Multi-Instance Diffusion Model)創新性地利用了三維物體生成模型,將其擴展為多實例擴散模型,能夠同時生成具有精確空間關系的多個 3D 實例,實現了高效高質量的 3D 場景生成:
- 單物體到多實例生成的跨越:通過同時去噪多個 3D 實例的潛在表示,并在去噪過程中引入多實例標記之間的交互,MIDI 將 3D 物體生成模型擴展至同時生成有交互建模的多實例,而后直接組合為 3D 場景。
- 多實例自注意力機制:通過將物體生成模型的自注意力擴展至多實例自注意力,MIDI 在生成過程中有效捕獲實例間的空間關聯和整體場景的連貫性,而無需逐場景的布局優化。
- 訓練階段的數據增強:通過使用有限的場景數據監督 3D 實例間的交互,同時結合物體數據進行增強訓練,MIDI 有效建模場景布局的同時保持了預訓練的泛化能力。
效果展示
基于單張圖像,MIDI 可以生成高質量的組合式 3D 場景:




在線演示
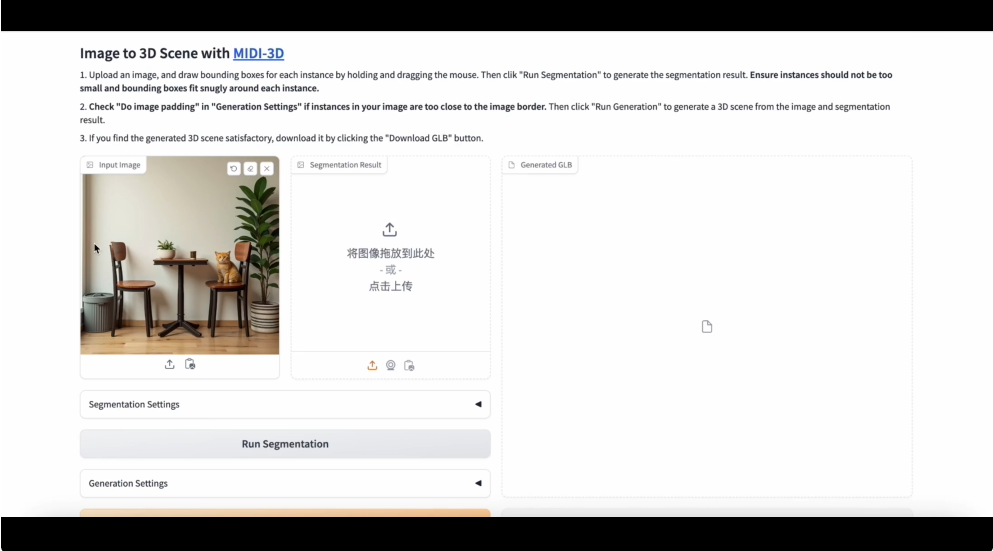
卓越性能:在幾何質量和空間布局等多個維度上表現突出
MIDI 的主要特點在于其精確的空間布局建模、卓越的幾何生成質量、生成的高效性和廣泛的適用性。實驗結果顯示,該模型在多個數據集上的表現超越現有方法,包括 3D 實例間的空間關系、3D 實例生成的幾何質量、以及端到端的生成速度均取得了優異的表現。


應用場景:3D 場景內容創作的新工具
MIDI 的出現為 3D 場景的創作提供了一種嶄新的解決方案。在建筑設計、虛擬現實、影視特效以及游戲開發等領域,該技術展現了廣闊的應用潛力。通過具備高準確度、高幾何質量的 3D 場景生成能力,MIDI 能夠滿足復雜場景中對高質量內容的需求,為創作者帶來更多可能性。
未來展望
盡管模型表現優異,MIDI 研發團隊深知仍有許多值得提升和探索的方向。例如,進一步優化對復雜交互場景的適配能力、提升物體生成的精細度等,都是未來努力的重點。希望通過不斷改進和完善,讓這一研發思路不僅推動單視圖生成組合 3D 場景技術的進步,也能為 3D 技術在實際應用中的廣泛普及貢獻力量。
























