單張圖像就可以訓練GAN!Adobe改良圖像生成方法 | 已開源
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
數據集太小了,無法訓練GAN?試試從單個圖像入手吧。
去年谷歌就提出了SinGAN,是第一個拿GAN在單幅自然圖像學習的非條件生成模型(ICCV 2019最佳論文)。
而最近,來自Adobe和漢堡大學的研究人員,對這個方法做了改進,探討了幾種讓GAN在單幅圖像提高訓練和生成能力的機制。
研究人員將改進的模型稱作ConSinGAN。

那么,先來看下ConSinGAN的效果吧。

上圖左側是用來訓練的單個圖像,右側是利用ConSinGAN訓練后生成的復雜全局結構。
可以看出效果還是比較逼真。
當然,ConSinGAN還可以用來處理許多其他任務,例如圖像超分辨率( image super-resolution)、圖像動畫(image animation),以及圖像去霧(image dehazing)。
下面兩張就是它在圖像協調(image harmonization)和圖像編輯(image editing)上的效果。


ConSinGAN是怎么做到的呢?
訓練架構優化:并行的SinGAN
首先,我們先來看下SinGAN的訓練過程。
SinGAN在圖像中訓練幾個單獨的生成網絡,下圖便是第一個生成器,也是唯一從隨機噪聲生成圖像的無條件生成器。
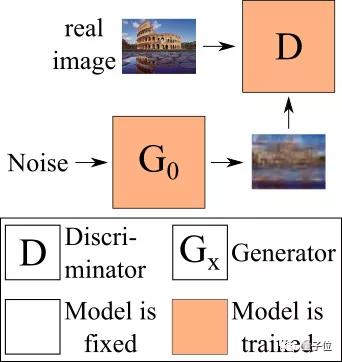
△在SinGAN中訓練的第一個生成器
這里的判別器從來不將圖像看做一個整體,通過這種方法,它就可以知道“真實的”圖像補丁(patch)是什么樣子。
這樣,生成器就可以通過生成,在全局來看不同,但僅從補丁來看卻相似的圖像,來達到“欺詐”的目的。
在更高分辨率上工作的生成器,將前一個生成器生成的圖像作為輸入,在此基礎上生成比當前還要高分辨率的圖像。
所有的生成器都是單獨訓練的,這意味著在訓練當前生成器時,所有以前的生成器的權重都保持不變。
這一過程如下圖所示。
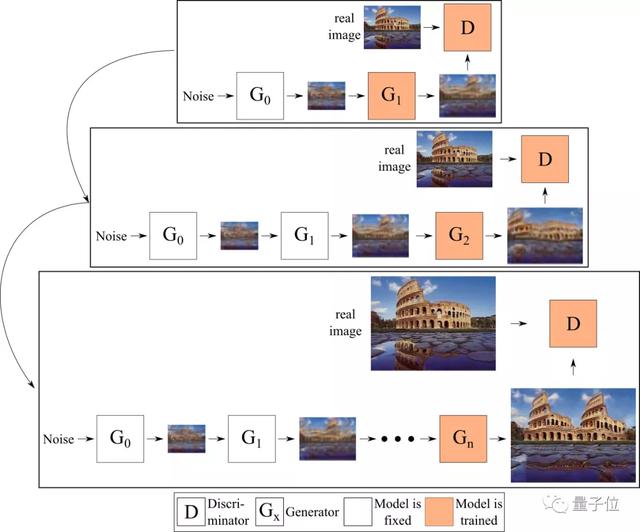
而在Adobe與漢堡大學的研究人員發現,在給定的時間內僅能訓練一個生成器,并將圖像(而不是特征圖)從一個生成器傳輸到下一個生成器,這就限制了生成器之間的交互。
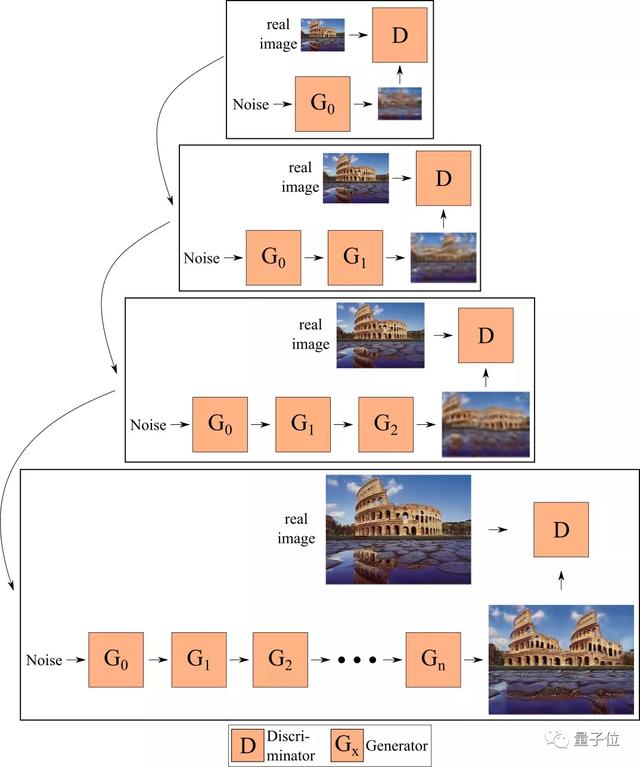
因此,他們對生成器進行了端到端的訓練,也就是說,在給定時間內訓練多個生成器,每個生成器將前一個生成器生成的特征(而不是圖像)作為輸入。
這也就是ConSinGAN名字的由來——并行的SinGAN,過程如下圖所示。
然而,采取這樣的措施又會面臨一個問題,也就是過擬合。這意味著最終的模型不會生成任何“新”圖像,而是只生成訓練圖像。
為了防止這種現象發生,研究人員采取了2個措施:
- 在任意給定時間內,只訓練一部分生成器;
- 對不同的生成器采用不同的學習率(learning rate)。
下圖就展示了使用這兩種方法實現的模型。默認情況下,最多同時訓練3個生成器,并對較低的生成器,分別將學習率調至1/10和1/100。
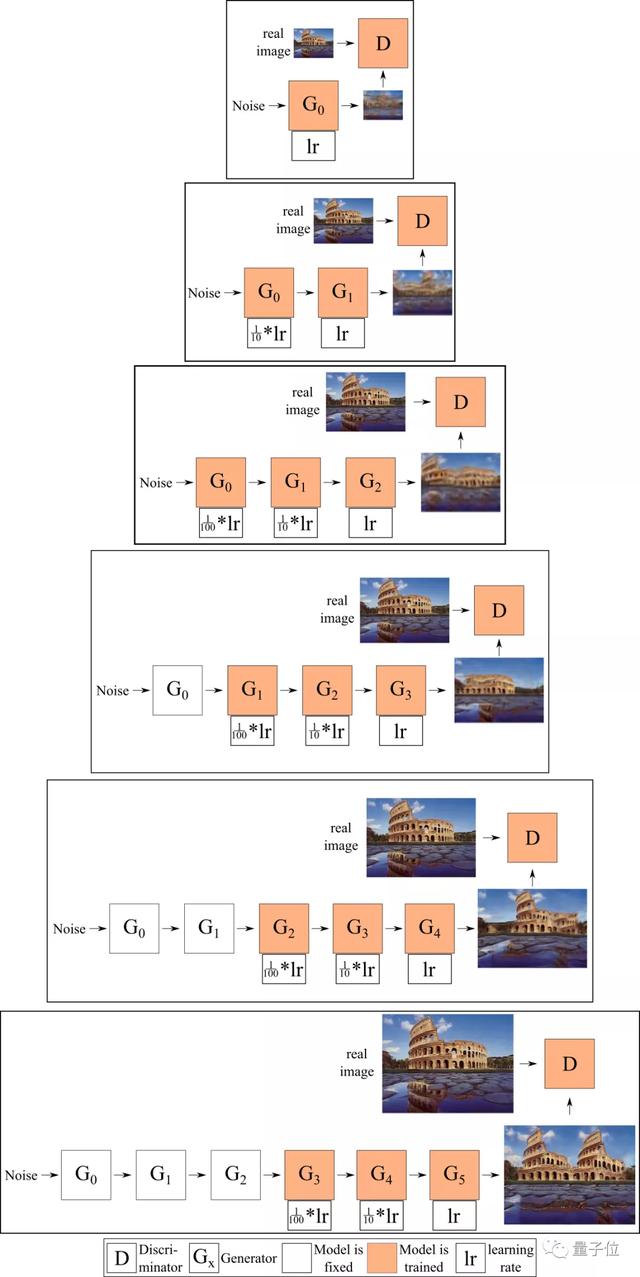
在這個過程中,有一個有趣的現象。
如果對較低的生成器采用較高的學習率,那么生成的圖像質量會高些,但是差異性較弱。
相反,如果對較低的生成器采用較小的學習率,那么生成圖像的差異性會豐富一些。如下圖所示。

代碼已開源
ConSinGAN的代碼已經在GitHub上開源。
老規矩,先介紹一下運行所需要的環境:Python 3.5;Pytorch 1.1.0。
安裝也非常簡單:
- pip install -r requirements.txt
若要使用論文中的默認參數訓練模型:
- python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/angkorwat.jpg
在英偉達GeForce GTX 1080Ti上訓練一個模型大約需要20-25分鐘。
不同的學習率和訓練階段數量,會影響實驗的結果,研究人員推薦二者的默認值分別是0.1和6。
當然也可以修改學習率:
- python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/colusseum.jpg --lr_scale 0.5
修改訓練階段的數量:
- python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/colusseum.jpg --train_stages 7
當然,模型也可以用來處理“圖像協調”和“圖像編輯”等任務,詳情可參閱GitHub。
傳送門
論文地址:
https://arxiv.org/pdf/2003.11512.pdf
GitHub項目地址:
https://github.com/tohinz/ConSinGAN