編輯 | 言征
出品 | 51CTO技術棧(微信號:blog51cto)
由于傳統的AI 基準測試技術已被證明不夠充分,AI 開發者開始采用更具創造性的方式來評估生成式 AI 模型的能力。對于一組開發者來說,這就是微軟旗下的沙盒建造游戲 Minecraft。
Minecraft Benchmark (或 MC-Bench)網站是合作開發的,目的是讓人工智能模型在面對面的挑戰中相互競爭,用 Minecraft 創作來回答提示。用戶可以投票選出哪個模型做得更好,只有在投票后,他們才能看到每個 Minecraft 構建都是由哪個人工智能完成的。
 Minecraft 基準測試
Minecraft 基準測試
對于創辦 MC-Bench 的 12 年級學生 Adi Singh 來說,Minecraft 的價值不在于游戲本身,而在于人們對它的熟悉程度——畢竟,它是有史以來最暢銷的電子游戲。即使對于沒有玩過這款游戲的人來說,仍然可以評估哪種塊狀菠蘿表現更好。
“Minecraft 讓人們更容易看到(人工智能開發的)進展,”辛格告訴 TechCrunch。“人們已經習慣了 Minecraft,習慣了它的外觀和氛圍。”
MC-Bench 目前列出了 8 名志愿者。根據 MC-Bench 網站,Anthropic、Google、OpenAI 和阿里巴巴已為該項目使用其產品運行基準測試提供補貼,但這些公司與其他公司并無關聯。
辛格說:“目前,我們只是在進行簡單的構建,以反思我們與 GPT-3 時代相比取得了多大的進步,但我們可以預見到自己會擴展到這些長期計劃和以目標為導向的任務。”“游戲可能只是一種測試代理推理的媒介,它比現實生活中更安全,而且在測試方面更易于控制,在我看來,這更理想。”
其他游戲,如《精靈寶可夢紅》、 《街頭霸王》和《你畫我猜》也被用作人工智能的實驗基準,部分原因是人工智能的基準測試藝術非常棘手。
研究人員經常在標準化評估中測試人工智能模型,但其中許多測試都讓人工智能擁有主場優勢。由于訓練方式的原因,模型天生擅長解決某些特定類型的問題,尤其是需要死記硬背或基本推斷的問題。
簡而言之,很難理解 OpenAI 的 GPT-4 可以在 LSAT 中取得 88% 的成績,但卻無法辨別“strawberry”這個詞中有多少個“R”。Anthropic的Claude 3.7 Sonnet在標準化軟件工程基準測試中的準確率為 62.3%,但它在玩 Pokémon 方面的表現卻比大多數五歲兒童還要差。
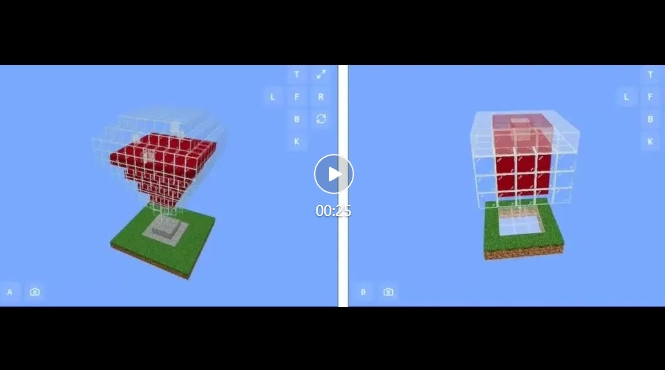 圖片來源:Minecraft Benchmark
圖片來源:Minecraft Benchmark
MC-Bench 從技術上來說是一個編程基準,因為模型被要求編寫代碼來創建提示的構建,例如“雪人弗羅斯蒂”或“原始沙灘上迷人的熱帶海灘小屋”。
但對于大多數 MC-Bench 用戶來說,評估雪人是否看起來更好比深入研究代碼更容易,這使得該項目具有更廣泛的吸引力 - 并因此有可能收集更多關于哪些模型持續得分更高的數據。
當然,這些分數是否對 AI 的實用性有重大影響還有待商榷。不過,Singh 堅稱,這是一個強烈的信號。
“目前的排行榜與我自己使用這些模型的經驗非常接近,這與許多純文本基準測試不同,”Singh 說。“也許 [MC-Bench] 可以幫助公司了解他們是否朝著正確的方向前進。”
基準鏈接:https://mcbench.ai/