深度探索:Spring 借助 Easy - Es 開啟 ElasticSearch 操作實戰篇章
這篇文章原本是采用spring-boot-starter-data-elasticsearch演示如何在spring boot項目中使用es,經一個讀者的建議打算將文章加以重構,改用一個更強大號稱傻瓜級ElasticSearch搜索引擎ORM框架Easy-Es,像操作MP一樣操作ES。
需要補充的是,在編寫這篇文章之前,筆者對Easy-Es文檔進行相對詳細的閱讀,個人認為Easy-Es1.0版本在實際項目中的集成和使用相對穩定一些,所以本文將以Easy-Es1.0版本展開演示,所以為保證后續集成步驟的順利建議讀者采用2.5.x +版本的Spring Boot(筆者直接使用2.6.0)。

詳解Easy-Es集成與操作
1. 集成Easy-Es與創建索引
集成Easy-Es的時首先自然是引入相關依賴,以筆者為例,項目中引用的版本就是1.1.1版本:
<dependency>
<groupId>cn.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>1.1.1</version>
</dependency>Easy-Es默認情況下會掃描我們的文檔實體完成索引創建,所以我們就可以直接聲明文檔的實體類型即直接使用,以本文為例,筆者創建的測試文檔包含id、標題、內容幾個字段,因為本案例多用內容的檢索且文本內容多是中文,所以在進行字段設計的時候針對內容字段嘗試將其設置為text類型,并將索引文檔時用的分詞器設置為ik_max_word以保證切出盡可能多的詞項提升檢索相關性數據的概率,同時指明搜索分詞器為ik_smart以保證檢索詞匯盡可能少切割得到最相關的結果:

對應的我們給出這段代碼示例,默認情況下Easy-Es會將所有的字符串類型設置為keyword,由于內容字段的特殊性,筆者通過IndexField指明索引和搜索的分詞器以達到上述效果:
@Data
public class Document {
/**
* es中的唯一id
*/
private String id;
/**
* 文檔標題
*/
private String title;
/**
* 文檔內容
*/
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_MAX_WORD, searchAnalyzer = Analyzer.IK_SMART)
private String content;
}基于文檔的實體類,編寫Es持久層mapper,和MP類似通過繼承BaseEsMapper獲得文檔操作的所有能力并通過泛型指明操作的文檔類型為Document:
public interface DocumentMapper extends BaseEsMapper<Document> {
}完成上述操作后,在啟動器上注明mapper的全路徑開啟自動掃描注入:
@EsMapperScan("com.sharkChili.mapper")完成上述配置之后將項目啟動,如果輸出Congratulations auto process index by Easy-Es is done !則說明文檔自動創建完成,此時我們就可以開始基本操作了:

當然Easy-Es也支持顯示的創建和刪除索引,需要注意1.x版本使用的模式是平滑模式回基于原有索引進行遷移,如果我們希望手動創建索引可以將模式改為手動模式:
easy-es.global-config.process_index_mode: manual這里我們也直接給出使用示例:
Boolean createRes = documentMapper.createIndex();
Boolean delRes = documentMapper.deleteIndex("document");2. 插入數據
對應我們也給出一份插入的基礎使用示例,如下所示可以看到操作步驟也只是聲明一下待插入文檔的實體然后調用insert即可完成插入:
Document document = new Document();
document.setTitle("測試標題");
document.setContent("測試的文本內容");
Integer count = documentMapper.insert(document);
log.info("count:{}", count);在用戶使用的角度,看起來像是操作MP一樣,實際上在執行insert方法時,Easy-Es底層也是和Mybatis類似,用到動態代理的機制,通過掃描實體類信息獲得索引名稱,然后構建restful風格的API請求執行文檔插入,完成后直接將生成的id結果設置到組裝實體中,并返回操作成功數:

我們可以直接從BaseEsMapperImpl的insert方法的源碼中看到實現,它首先會基于實體類調用getIndexName獲得索引名稱,然后調用insert執行當前文檔的插入工作:
@Override
public Integer insert(T entity) {
//......
//基于實體獲得索引名稱后調用insert進行插入
return insert(entity, EntityInfoHelper.getEntityInfo(entityClass).getIndexName());
}不入其內部即可看到基于我們的實體信息構建restful api的入參,通過Easy-Es聚合的原生RestHighLevelClient發送POST請求提交文檔,如果成功則將文檔的id賦值到實體上返回給用戶:
private Integer doInsert(T entity, String indexName) {
// 基于實體構建請求入參
IndexRequest indexRequest = buildIndexRequest(entity, indexName);
indexRequest.setRefreshPolicy(getRefreshPolicy());
try {
//發送POST請求插入文檔
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
//如果插入成功則將返回的id值賦值到傳入的實體上
if (Objects.equals(indexResponse.status(), RestStatus.CREATED)) {
setId(entity, indexResponse.getId());
return BaseEsConstants.ONE;
} else if (Objects.equals(indexResponse.status(), RestStatus.OK)) {
// 該id已存在,數據被更新的情況
return BaseEsConstants.ZERO;
} else {
//......
}
} catch (IOException e) {
//......
}
}3. 查詢數據
上文提到字符串類型默認情況下是keyword類型,所以title字段查出是精準匹配的,對應的查詢組裝如下所示通過LambdaEsQueryWrapper的eq函數指明等值查詢,檢索一條標題為測試標題,最終就可以將上一步插入操作的文檔返回:
String title = "測試標題";
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
//底層走must term查詢
wrapper.eq(Document::getTitle, title);
Document document = documentMapper.selectOne(wrapper);
log.info(JSONUtil.toJsonStr(document));這里我們查看eq函數的底層實現可以看到實現精準匹配本質上就是通過must查詢term為測試標題的文檔:
@Override
public Children eq(boolean condition, String column, Object val, Float boost) {
return doIt(condition, TERM_QUERY, MUST, column, val, boost);
}其底層操作邏輯和插入操作整體步驟是差不多的,即通過代理構建restful api發起請求并將結果映射為java bean返回,這里我們就貼出selectOne操作底層的核心實現,即位于BaseEsMapperImpl的getSearchResponse方法,它就是會基于我們的參數調用search接口,并將響應結果返回給上層組裝成實體對象給用戶:
private SearchResponse getSearchResponse(LambdaEsQueryWrapper<T> wrapper, Object[] searchAfter) {
// 構建es restHighLevelClient 查詢參數
SearchRequest searchRequest = new SearchRequest(getIndexNames(wrapper.indexNames));
// 用戶在wrapper中指定的混合查詢條件優先級最高
SearchSourceBuilder searchSourceBuilder = Optional.ofNullable(wrapper.searchSourceBuilder)
.map(builder -> {
// 兼容混合查詢時用戶在分頁中自定義的分頁參數
Optional.ofNullable(wrapper.from).ifPresent(builder::from);
Optional.ofNullable(wrapper.size).ifPresent(builder::size);
return builder;
}).orElseGet(() ->
//基于我們的wrapper構建出請求入參
WrapperProcessor.buildSearchSourceBuilder(wrapper, entityClass));
//......
// 執行查詢
SearchResponse response;
try {
response = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw ExceptionUtils.eee("search exception", e);
}
//將結果返回
printResponseErrors(response);
return response;
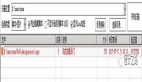
}源碼邏輯實現如上所示,這里我們就看看document文檔底層代理基于我們的入參所構建的請求參數searchSourceBuilder ,很明顯就是一個典型的restful api參數:

對于自然語言處理的文本檢索,也就是match查詢,Easy-Es也做了很好的封裝,對應的使用示例如下所示:
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent, "你好,這是 elasticsearch操作教程");
List<Document> documentList = documentMapper.selectList(wrapper);
if (CollUtil.isNotEmpty(documentList)) {
log.info("size:{}", documentList.size());
log.info("first data:{}", JSONUtil.toJsonStr(documentList.get(0)));
}4. 更新和刪除數據
有了上述的基礎,對于更新操作等操作都比較好理解了,這里我們直接貼出基于id更新操作的使用示例也是類似于主流ORM框架Mybatis,讀者可參考源碼了解使用步驟:
String id = "HVWfjpQBtr9x3QfTu299";
Document updateDocument = new Document();
updateDocument.setId(id);
updateDocument.setContent("修改后的文本內容");
Integer count = documentMapper.updateById(updateDocument);
log.info("update count:{}", count);刪除操作同理,這里就不多做贅述了:
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
String title = "測試標題";
wrapper.eq(Document::getTitle, title);
int successCount = documentMapper.delete(wrapper);
log.info("delete count:{}", successCount);5. 分頁查詢
和Mybatis-Plus類似,Easy-Es也針對分頁查詢做了很好的封裝,使用時我們也僅需指定頁碼和頁數即可完成查詢:
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent, "你好,這是 elasticsearch操作教程");
EsPageInfo<Document> documentPageInfo = documentMapper.pageQuery(wrapper, 1, 10);
log.info("query res:{}", documentPageInfo.toString());從分頁查詢的API即pageQuery可以看到該查詢本質上也是服用了BaseEsMapperImpl的getSearchResponse方法,底層回基于我們傳入的參數封裝from和size并發送HTTP請求獲取分頁結果:
private SearchResponse getSearchResponse(LambdaEsQueryWrapper<T> wrapper, Object[] searchAfter) {
// 構建es restHighLevelClient 查詢參數
SearchRequest searchRequest = new SearchRequest(getIndexNames(wrapper.indexNames));
// 用戶在wrapper中指定的混合查詢條件優先級最高
SearchSourceBuilder searchSourceBuilder = Optional.ofNullable(wrapper.searchSourceBuilder)
.map(builder -> {
// 兼容混合查詢時用戶在分頁中自定義的分頁參數,基于我們傳參的wrapper得到頁數和頁碼構建from和size參數
Optional.ofNullable(wrapper.from).ifPresent(builder::from);
Optional.ofNullable(wrapper.size).ifPresent(builder::size);
return builder;
}).orElseGet(() -> WrapperProcessor.buildSearchSourceBuilder(wrapper, entityClass));
//......
// 執行查詢
SearchResponse response;
try {
response = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw ExceptionUtils.eee("search exception", e);
}
//......
return response;
}按照ES官方的說法,默認情況下超過10000條之后的數據,from-size查詢是不允許的,原因是避免多分片歸并聚合所導致的OOM問題,所以對于深分頁,ES官方是推薦采用search_after:https://www.elastic.co/guide/en/elasticsearch/reference/8.3/paginate-search-results.html#search-after
對此我們也給出searchAfter 的使用示例:
LambdaEsQueryWrapper<Document> lambdaEsQueryWrapper = EsWrappers.lambdaQuery(Document.class);
lambdaEsQueryWrapper.size(10);
// 必須指定一種排序規則,且排序字段值必須唯一 此處我選擇用id進行排序 實際可根據業務場景自由指定,不推薦用創建時間,因為可能會相同
lambdaEsQueryWrapper.orderByDesc(Document::getId);
SAPageInfo<Document> saPageInfo = documentMapper.searchAfterPage(lambdaEsQueryWrapper, null, 10);
// 第一頁
log.info("first page:{}", saPageInfo);
// 獲取下一頁
List<Object> nextSearchAfter = saPageInfo.getNextSearchAfter();
SAPageInfo<Document> next = documentMapper.searchAfterPage(lambdaEsQueryWrapper, nextSearchAfter, 10);
log.info("second page:{}", next);