SS 2025|ConRFT:真實環境下基于強化學習的VLA模型微調方法
本文第一作者為陳宇輝,中科院自動化所直博三年級;通訊作者為李浩然,中科院自動化所副研;研究方向為強化學習、機器人學習、具身智能。
視覺-語言-動作模型在真實世界的機器人操作任務中顯示出巨大的潛力,但是其性能依賴于大量的高質量人類演示數據。
由于人類演示十分稀缺且展現出行為的不一致性,通過監督學習的方式對 VLA 模型在下游任務上進行微調難以實現較高的性能,尤其是面向要求精細控制的任務。
為此,中科院自動化所深度強化學習團隊提出了一種面向 VLA 模型后訓練的強化微調方法 ConRFT(Consistency-based Reinforced Fine-tuning)。其由離線和在線微調兩階段組成,并具有統一的基于一致性策略的訓練目標。這項工作凸顯了使用強化學習進行后訓練以增強視覺-語言-動作模型在真實世界機器人應用中的潛力。
目前,該論文已被機器人領域頂級會議 Robotics: Science and Systems XXI(RSS 2025)接收。

- 論文標題:ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
- 論文地址:https://arxiv.org/abs/2502.05450
- 項目主頁:https://cccedric.github.io/conrft/
- 開源代碼:https://github.com/cccedric/conrft
研究背景
視覺-語言-動作模型(Vision-Language-Action, VLA)在訓練通用機器人策略方面取得的最新進展表明機器人數據集上進行大規模預訓練后 [1,2],其擁有在理解和執行各種操作任務方面的卓越能力。
雖然預訓練的通用策略能夠捕捉泛化性的表征,但其仍然難以在真實機器人和任務上做到零樣本泛化 [3],因此使用任務專用的數據進行后訓練微調對于優化模型在下游任務中的性能來說非常重要。
目前廣泛使用的方法是使用人類遙操作收集的數據對 VLA 模型進行監督微調(Supervised Fine-tuning, SFT)。然而,模型的性能嚴重依賴于數據集的質量和數量。由于人類收集數據的次優性和策略不一致性等固有問題,這些數據很難提供最優軌跡 [4],導致微調后的模型效果不佳。
與此同時,大語言模型(Large Language Model, LLM)和視覺-語言模型(Vision-Language Model, VLM)的最新進展凸顯了強化學習在對齊模型策略與人類偏好之間差距 [5] 或改進模型推理 [6] 方面的價值,證明了部署使用任務專用的獎勵函數的強化學習(Reinforcement Learning, RL)來從在線交互中機性能策略更新具有巨大的潛力。
然而,與 LLM/VLM 不同,VLA 模型需要機器人與真實世界進行物理交互,因而將 RL 擴展到 VLA 模型面臨著巨大的挑戰。尤其是在要求精細控制的操作任務上,交互安全性和成本限制要求 RL 算法具有探索的安全保障和很高的樣本效率。
ConRFT:基于強化學習的 VLA 模型微調方法
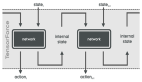
為了充分利用 RL 技術的優勢,利用在線交互數據高效微調 VLA 模型,我們提出了一種強化微調(Reinforced Fine-tuning, RFT)方法,包含離線和在線兩個階段,并采用統一的訓練目標。
基于我們之前的工作 CPQL [7],本文方法將 SFT 與 Q-learning 相結合,并利用一致性策略微調 VLA 模型。離線微調過程中利用人類收集的專家數據,在模型與真實環境交互之前提取有效的策略和穩定的價值函數。
隨后的在線微調階段通過人在回路(Human-in-the-Loop Learning, HIL)進行干預,并使用獎勵驅動的策略學習,從而解決了在真實環境下進行 RL 的安全要求和樣本效率兩個挑戰。該方法示意圖如下:

本文方法采用一致性策略(Consistency Policy)作為動作單元(Action Head),對 VLA 模型進行微調,解決了兩個關鍵問題:
1)它有助于利用預收集的數據中經常出現的策略不一致和次優演示問題;
2)與基于擴散模型(Diffusion Model)的動作單元相比,其在計算上保持輕量,可以實現高效推理。
一致性策略是一種基于概率流常微分方程(Probability Flow Ordinary Differential Equation)的策略,它學習從高斯分布中采樣的隨機動作映射到基于當前狀態的專家動作分布,從而生成目標動作用于決策任務。
階段I:離線微調(Cal-ConRFT)
由于預訓練的 VLA 模型通常缺乏對未見過場景的零樣本泛化能力,因此離線階段專注于使用預先收集的小型離線數據集(大約 20-30 次演示)訓練策略,然后再過渡到在線微調階段,從而減少整體在線訓練時間和探索過程帶來的安全風險。
為了能夠有效利用離線數據,離線階段選擇(Cal-QL)[8] 作為價值函數更新方法,以提高 Q 函數對分布外(Out of Distribution, OOD)動作的魯棒性。使用 Cal-QL 進行價值函數更新的訓練目標如下:

盡管通常情況下,Cal-QL 能夠高效地利用離線數據集,但在只有少量演示(例如 20-30 個)可用時,其依然很難訓練出有效的策略。因為有限的狀態-動作覆蓋會導致 Q 值估計不準,從而使策略難以推廣到未見過的狀態。相比傳統的離線強化學習方法,其數據集通常由多種行為策略收集而成,可以提供廣泛的狀態-動作覆蓋范圍以減少分布偏移。
為了解決這個問題,離線階段加入了 BC(Behavior Cloning)損失。BC 損失直接最小化策略生成的動作與演示中的動作之間的差異,通過鼓勵模型模仿演示中的行為,在離線階段提供額外的監督信號。這有助于 VLA 模型學習更有效的策略,并初始化穩定的 Q 函數。
具體而言,使用一致性策略動作單元的 VLA 模型更新訓練目標如下:

階段II:在線微調(HIL-ConRFT)
雖然離線階段可以從少量演示數據中提供初始策略,但其性能受限于預先收集的演示數據的范圍和質量。因此,本文方法引入在線階段,即 VLA 模型通過與真實環境交互并進行在線微調。
在階段 II 的強化微調過程中,離線階段的演示緩沖區 依然保持用于存儲演示數據,同時還有一個重放緩沖區
依然保持用于存儲演示數據,同時還有一個重放緩沖區 來存儲在線數據,并使用平均采樣來形成單個批次(Batch)用于模型訓練。
來存儲在線數據,并使用平均采樣來形成單個批次(Batch)用于模型訓練。
由于 VLA 模型會根據其當前策略不斷收集新的數據,數據分布會自然地隨著策略而演變,這種持續的交互減少了離線階段面臨的分布偏移問題。因此,在線微調階段直接使用標準 Q 損失進行價值函數更新:

對于 VLA 模型,在線微調階段使用與離線階段結構統一的訓練目標,因此 VLA 模型可以快速適應并實現策略性能提升:

可以注意到,在線階段仍然保留了 BC 損失。主要有兩個原因:
1)它確保策略與演示數據一致,防止出現可能導致性能崩潰的劇烈偏差;
2)由于強化學習本質上涉及探索,因此它在高維狀態-動作空間中可能變得不穩定,而 BC 損失可以防止策略與離線基線方法偏差過大,從而降低低效或不安全行為的風險。這在真實機器人的訓練中和要求精細控制的操作任務中非常重要,尤其是在不安全動作可能導致物體損壞或其他危險的物理環境中。
此外,在線階段通過人在回路學習將人工干預融入學習過程。具體而言,其允許人類操作員及時干預并從 VLA 模型接管機器人的控制權,從而在探索過程中提供糾正措施。
當機器人出現破壞性行為(例如碰撞障礙物、施加過大的力量或破壞環境)時,人工干預至關重要。這些人工糾正措施會被添加到演示緩沖區 中,以提供高層次的指導,引導策略探索朝著更安全、高效的方向演變。
中,以提供高層次的指導,引導策略探索朝著更安全、高效的方向演變。
除了確保安全的探索之外,人工干預還可以加速策略收斂。因為當策略導致機器人陷入不可恢復狀態或不良狀態(如機械臂將被操作物體扔出桌面或與桌面撞擊),或者機器人陷入局部最優解(如果沒有外部幫助,則需要花費大量時間和步驟才能克服)時,人類操作員可以介入糾正機器人的行為,并引導其朝著更安全、有效的方向演變。
實驗結果與分析
為了評估本文方法在真實環境中強化微調 VLA 模型的有效性,我們在八個不同的操作任務上進行了實驗,并選擇 Franka Emika 機械臂作為實驗平臺,如下圖所示。

這些任務旨在反映各種操作任務挑戰,包括物體放置任務(例如將面包放入烤面包機)、要求精確控制的任務(例如將輪子對準并插入椅子底座)以及柔性物體處理的任務(例如懸掛中國結)。
在八個真實環境任務上的實驗測試證明了 ConRFT 性能超越最先進(SOTA)方法的能力。VLA 模型在本文提出的框架下經過 45-90 分鐘的在線微調后,平均任務成功率達到 96.3%,展現了極高的策略性能和樣本效率。
此外,它的性能優于基于人類收集數據或強化學習策略數據訓練的 SFT 方法,平均成功率提高了 144%,且平均軌跡長度縮短了 1.9 倍,這些結果凸顯了使用獎勵驅動的強化微調方法在提升 VLA 模型在下游任務上性能的巨大潛力。
策略測試
通過獎勵驅動的強化微調,VLA 模型表現出對外部人為干擾的極強魯棒性,確保更可靠地完成任務。包含外部人為干擾的策略效果可以參考 Pick Banana 和 Hang Chinese Knot 任務。
Pick Banana(含外部人為干擾)

Put Spoon

Open Drawer

Pick Bread

Open Toaster

Put Bread

Insert Wheel

Hang Chinese Knot(含外部人為干擾)

在精細操作任務上的展示
為了進一步展示本文方法在 VLA 模型微調方面的能力,我們進行了穿針任務實驗。經過 40 分鐘的在線微調,微調后的 VLA 模型取得了 70% 的成功率。

總結與展望
本文提出了一種兩階段方法 ConRFT,用于在真實環境下的機器人應用中強化微調 VLA 模型。
首先,利用少量演示進行離線微調(Cal-ConRFT),并通過一個統一的訓練目標初始化一個可靠的策略和價值函數,該目標將 Q 損失和 BC 損失整合到一個基于一致性策略的框架中。然后,在線微調階段(HIL-ConRFT)利用任務專用的獎勵和人工干預對 VLA 模型進行微調。
在八個不同的真實環境操作任務上實驗結果表明,本文方法在成功率、平均軌跡長度和樣本效率方面均優于 SOTA 方法。總而言之,這項工作展示了一種利用強化學習進行安全且高效的 VLA 模型微調的方法。