基于獎勵驅動和自組織演化機制,全新框架ReSo重塑復雜推理任務中的智能協作
本文由上海人工智能實驗室,悉尼大學,牛津大學聯合完成。第一作者周恒為上海 ailab 實習生和 Independent Researcher 耿鶴嘉。通訊作者為上海人工智能實驗室青年科學家白磊和牛津大學訪問學者,悉尼大學博士生尹榛菲,團隊其他成員還有 ailab 實習生薛翔元。
ReSo 框架(Reward-driven & Self-organizing)為復雜推理任務中的多智能體系統(MAS)提供了全新解法,在處理復雜任務時,先分解生成任務圖,再為每個子任務匹配最佳 agent。將任務圖生成與獎勵驅動的兩階段智能體選擇過程相結合,該方法不僅提升了多智能體協作的效率,還為增強多智能體的推理能力開辟了新路徑。

- 論文標題:ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
- 論文鏈接:https://arxiv.org/abs/2503.02390
- 代碼地址:https://github.com/hengzzzhou/ReSo
研究背景:LLM 推理能力的掣肘與突破口
近年來,增加推理時間(Inference Time Scaling)被廣泛認為是提升大語言模型(Large Language Models, LLMs)推理能力的重要途徑之一。一方面,通過在訓練后階段引入強化學習與獎勵模型,可優化單一模型的推理路徑,使其在回答前生成中間步驟,表現出更強的邏輯鏈構建能力;另一方面,也有研究嘗試構建多智能體系統(Multi-Agent Systems, MAS),借助多個基座模型或智能體的協同工作來解決單次推理難以完成的復雜任務。
相較于單模型的推理時間擴展,多智能體方法在理論上更具靈活性與可擴展性,但在實際應用中仍面臨諸多挑戰:
(1)多數 MAS 依賴人工設計與配置,缺乏自動擴展與適應性的能力;
(2)通常假設所有智能體能力已知,然而 LLM 作為 “黑箱式” 的通用模型,在實際任務中往往難以預先評估其能力邊界;
(3)現有 MAS 中的獎勵信號設計較為粗糙,僅依賴結果反饋或自我評估,難以有效驅動優化過程;
(4)缺乏基于數據反饋的動態演化機制,限制了 MAS 系統在大規模任務中的表現與泛化能力。
上述限制提出了一個核心問題:能否構建一種具備自組織能力的多智能體系統,使其能夠通過獎勵信號直接從數據中學習協作策略,而無需大量人工干預?
為應對這一挑戰,作者提出了 ReSo—— 一個基于獎勵驅動、自組織演化機制的多智能體系統架構。該方法通過引入協同獎勵模型(Collaborative Reward Model, CRM),在任務圖生成與智能體圖構建之間建立反饋閉環,從而實現基于細粒度獎勵的智能體動態優化與協作演化。與現有多智能體方案相比,ReSo 在可擴展性與優化能力上均具優勢,并在多項復雜推理任務上達到了領先性能。

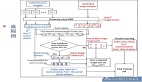
ReSo 框架流程圖
ReSo 框架:Task Graph + Agent Graph,重塑 MAS 推理能力
具體來說,作者提出了兩項核心創新:(1) ReSo,一個獎勵驅動的自組織 MAS,能夠自主適應復雜任務和靈活數量的智能體候選,無需手動設計合作解決方案。(2) 引入協作獎勵模型 (CRM),專門用于優化 MAS 性能。CRM 可以在多智能體協作中提供細粒度的獎勵信號,從而實現數據驅動的 MAS 性能優化。
1. 問題定義
對于一個解決任意問題 Q 的多智能體任務,作者將其定義為如下算法:

其中  負責根據輸入問題構建任務分解圖,確保將問題結構化地分解為子任務及其依賴關系。
負責根據輸入問題構建任務分解圖,確保將問題結構化地分解為子任務及其依賴關系。 則動態地選擇并分配合適的代理來解決已識別的子任務。這種模塊化設計使得每個組件能夠獨立優化,從而實現更高的靈活性和可擴展性。
則動態地選擇并分配合適的代理來解決已識別的子任務。這種模塊化設計使得每個組件能夠獨立優化,從而實現更高的靈活性和可擴展性。
2. 任務圖生成:明確子任務和依賴關系
ReSo 首先使用一個大語言模型將復雜問題分解,轉化為分步驟的有向無環任務圖 (DAG Task Graph),為后續智能體分配提供基礎。

在實踐中,對于任務分解,作者既測試了了已有的閉源模型(如 gpt4o),也在開源 LLM (如 Qwen-7b) 上進行監督微調 (SFT) 來執行更專業的任務分解。為了微調開源 LLM,作者構建了合成數據(見后文數據貢獻章節),明確要求 LLM 將 Q 分解為邏輯子問題,指定它們的執行順序和依賴關系,并以 DAG 格式輸出。

3. 兩階段智能體選擇:從粗到細,精挑細選
一旦獲得任務圖,作者就需要將每個子任務分配給最合適的代理。作者將此代理分配過程表示為  。從概念上講,
。從概念上講, 會根據大型代理池 A 中最合適的代理對任務圖中的每個節點進行分類,從而構建一個代理圖,將每個節點映射到一個或多個選定的代理。
會根據大型代理池 A 中最合適的代理對任務圖中的每個節點進行分類,從而構建一個代理圖,將每個節點映射到一個或多個選定的代理。

具體來說,作者提出了動態智能體數據庫(DADB)作為 Agent 選擇的代理池:通過構建一個動態數據庫,存儲智能體的基本信息、歷史性能及計算成本,以供未來生成初步質量評分。
在 DADB 的基礎上,對于使智能體選擇算法具有可擴展性、可優化性,作者提出了兩階段的搜索算法:
- 粗粒度搜索(UCB 算法):利用上置信界(UCB)算法篩選候選智能體。

給定 DADB A 和一個子任務 vj,作者希望首先從所有智能體中篩選出一批有潛力的候選智能體(數量為 k)。
為此,作者采用了經典的上置信界(UCB)策略,該策略兼顧 “探索” 和 “利用” 的平衡:

其中:Q ( ):DADB 給出的預評分,N:系統到目前為止分配過的智能體總數,n (
):DADB 給出的預評分,N:系統到目前為止分配過的智能體總數,n ( ):智能體
):智能體 被選中的次數,ε?1:防止除以 0 的微小常數,c:超參數,控制探索(少被用過的智能體)與利用(高評分智能體)之間的平衡。
被選中的次數,ε?1:防止除以 0 的微小常數,c:超參數,控制探索(少被用過的智能體)與利用(高評分智能體)之間的平衡。
最后,作者按 UCB 分數對所有智能體排序,選擇前 k 個作為當前子任務的候選集:
- 細粒度篩選(協作獎勵模型 CRM):通過協作獎勵模型對候選智能體進行細粒度評估,最終選擇最優智能體。
在完成粗粒度篩選、選出了候選智能體集合之后,作者需要進一步評估這些智能體在當前子任務 上的實際表現。這一步是通過一個協同獎勵模型(Collaborative Reward Model, CRM) 來完成的。
上的實際表現。這一步是通過一個協同獎勵模型(Collaborative Reward Model, CRM) 來完成的。
這個評估過程很直接:
每個候選智能體 ai 對子任務 生成一個答案,記作
生成一個答案,記作  (
( );
);
然后作者通過獎勵模型來評估這個答案的質量,得到獎勵值 r ( ,
,  ):
):

其中 RewardModel 會綜合考慮以下因素來打分:
A. 當前智能體 的角色與設定(即其 static profile);
的角色與設定(即其 static profile);
B. 子任務 的目標;
的目標;
C. 以及該智能體在先前的推理過程中的上下文。
在所有候選智能體被評估后,作者將獎勵值最高的智能體 a 分配給子任務 ,并將其生成的答案作為該子任務的最終解。這個評估與分配過程會對任務圖中的每一個子任務節點重復進行,直到整張圖完成分配。
,并將其生成的答案作為該子任務的最終解。這個評估與分配過程會對任務圖中的每一個子任務節點重復進行,直到整張圖完成分配。
1. 從訓練到推理:動態優化與高效推理
- 訓練階段:利用 CRM 獎勵信號動態更新 DADB,實現自適應優化。

其中:R ( ) 表示當前該智能體的平均獎勵;n (
) 表示當前該智能體的平均獎勵;n ( ) 是它至今參與的任務次數;r (
) 是它至今參與的任務次數;r ( ,
, ) 是它在當前子任務中的獎勵。
) 是它在當前子任務中的獎勵。
類似地,作者也可以用同樣的方式更新該智能體的執行開銷(例如運行時間、資源消耗等),記作 c ( ,
,  )。
)。
通過不斷迭代地學習和更新,DADB 能夠動態地根據歷史數據評估各個智能體,從而實現自適應的智能體選擇機制,提升系統的整體性能和效率。
- 推理階段:在測試階段,作者不再需要獎勵模型。此時,作者直接使用已經訓練好的 DADB,從中選擇最優的智能體候選者,并為每個子任務挑選最優解。
2. 從 MCTS 視角看 ReSo:降低復雜度,提升擴展性
任務圖經過拓撲排序后,形成一棵決策樹,其中每個節點代表一個子任務,邊表示依賴關系。在每一層,作者使用 UCB 修剪樹并選擇一組有潛力的智能體,然后模擬每個智能體并使用 CRM 評估其性能。由此產生的獎勵會更新智能體的動態配置文件,從而優化選擇策略。MAS 的構建本質上是尋找從根到葉的最佳路徑,最大化 UCB 獎勵以獲得最佳性能。
數據集生成:Mas-Dataset
由于缺乏高質量的 MAS 數據集,作者提出了一種自動化方法來生成多智能體任務數據。這個過程包括隨機生成任務圖、填充子任務以及構建自然語言依賴關系。提出了一個單個 sample 就具有多學科任務的數據集。開源了數據合成腳本論文合成了 MATH-MAS 和 Scibench-MAS 數據集,復雜度有3,5,7。復雜度為 7 的意思為,單個題目中由7個子問題組成,他們來自不同的領域(數學,物理,化學)。子問題之間有依賴關系,評測模型處理復雜問題的能力。下圖是個 Scibench-MAS 復雜度為 3 的例子:

實驗結果
主要結果
表 1 的實驗結果實驗表明,ReSo 在效果上匹敵或超越現有方法。ReSo 在 Math-MAS-Hard 和 SciBench-MAS-Hard 上的準確率分別達到 33.7% 和 32.3% ,而其他方法則完全失效。圖 3 顯示,在復雜推理任務中,ReSo 的表現全面優于現有 MAS 方法,展現了其卓越的性能和強大的適應性。