智能體式推理與工具集成:ARTIST 基于強化學習的新思路

大家好,我是肆〇柒。這兩天,我看到一篇論文《Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning》講述的是ARTIST 框架,為 LLM 賦予智能體式推理與工具集成的全新維度。今天,就一起了解一下這個 ARTIST 框架,看看 LLM 如何借助強化學習突破局限,開啟智能體式推理與工具集成。
背景介紹
在AI 領域,LLM 憑借強大的語言理解和生成能力,為我們的生活和工作帶來了前所未有的便利。然而,隨著應用場景的不斷拓展,LLM 的局限性也逐漸顯現。它們依賴于靜態的內部知識庫,僅能進行基于文本的推理,這使得在處理復雜現實問題時,常常顯得力不從心。
例如,在解決復雜數學問題時,模型可能需要調用外部數學庫進行高精度計算;在規劃旅行路線時,可能需要實時查詢航班信息并預訂酒店;在處理多輪對話任務時,需要精準地維護對話狀態,靈活地調用各種函數。這些需求,對傳統 LLM 來說,無疑是一道難題。
為解決這個問題,研究者提出了 ARTIST 框架。它巧妙地將智能體式推理、強化學習和工具集成深度融合,使模型在多輪推理過程中能夠自主決策工具調用的時機、方式與種類。通過這種方式,ARTIST 為 LLM 賦予了更加靈動、智慧的大腦,使其在復雜現實任務中能夠游刃有余,從而推動人工智能從單純的語言理解與生成向真正的智能決策與執行邁進。
ARTIST 框架概述
核心概念
ARTIST 框架的核心理念,是讓 LLM 走出文本推理的舒適區,學會與外部工具和環境互動。在多輪推理鏈中,模型不再是機械地生成文本,而是像一位機智的指揮官,根據任務需求,實時判斷是否需要調用工具,以及調用何種工具。例如,在解決一道高難度數學物理問題時,模型可能會先進行幾輪文本推理,分解問題;隨后意識到需要進行符號計算,便調用 Python 解釋器,借助 SymPy 庫完成復雜積分運算;得到結果后,再次回到文本推理,整合信息,最終輸出完美的答案。
這種智能體式推理與工具集成的結合,使模型能夠突破內部知識的局限,借助外部工具的力量,解決更為復雜的問題。它不僅提升了模型的推理能力,還拓展了其應用場景。
架構組成
ARTIST 的架構各部分緊密相連,協同運作。
策略模型作為智慧核心,負責生成推理軌跡,決定工具調用策略。它通過不斷的訓練和優化,學會了如何在復雜的任務中,精準地選擇合適的工具,并在合適的時機調用它們。
任務是驅動整個推理過程的引擎,明確模型需要解決的問題。它為模型提供了目標方向,使模型的推理和工具調用都有據可依。
工具和環境則是左膀右臂,為模型提供豐富的外部功能支持和實時信息反饋。工具可以是數學計算庫、網頁瀏覽器、文件操作 API 等各種軟件資源;環境則可以是操作系統界面、網頁 Arena 等交互式平臺。通過與工具和環境的交互,模型能夠獲取最新的信息,執行復雜的操作,從而完成任務。
動作代表著模型在推理過程中的具體操作,包括文本生成和工具調用。模型通過動作,與外部世界進行交流和互動,推動任務的進展。
觀察則是模型從環境中獲取的反饋信息,用于調整后續推理方向。這些反饋信息可以是工具的輸出結果、環境的狀態變化等,它們為模型提供了寶貴的外部信息,幫助模型更好地理解和解決問題。
推理是貫穿整個過程的主線,體現模型對問題的逐步理解和解決思路。在推理過程中,模型不斷地整合內部知識和外部信息,逐步深入,直至找到問題的解決方案。
答案是推理的結晶,是模型對任務的最終回應。它是模型智慧的體現,是整個推理過程的成果。
獎勵機制則是引導模型不斷優化推理策略的燈塔。根據任務完成情況給予正負反饋,激勵模型向正確的方向前進。例如,當模型成功解決了問題,并且工具調用準確無誤,同時推理過程深入透徹,那么它將獲得豐厚的獎勵;反之,如果任務失敗或者工具調用出現錯誤,模型將受到懲罰。通過這種方式,模型在不斷的試錯中,逐漸學會了如何更好地解決問題。

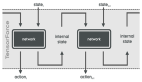
ARTIST 框架
如上圖所示,ARTIST 架構通過交織基于文本的思考、工具查詢和工具輸出,實現了推理、工具使用和環境交互的動態協調。這種架構使得模型能夠在統一的框架內,靈活地調用工具和環境,從而增強其解決復雜問題的能力。
方法論
強化學習算法
在強化學習算法中,Group Relative Policy Optimization(GRPO)算法以其獨特的優勢脫穎而出,成為 ARTIST 框架的算法基石。GRPO 算法巧妙的地方在于它摒棄了傳統強化學習算法對價值函數近似的依賴。在 PPO 等傳統算法中,價值函數近似常常引入額外的復雜性和誤差,而 GRPO 通過從一組樣本響應中估計基線,巧妙地簡化了優化過程。它直接利用群體相對獎勵信號來優化策略模型,讓模型在群體智慧的指引下,更快、更精準地找到最優策略。
GRPO 算法通過以下步驟實現:

GRPO 算法相較于傳統強化學習算法的優勢在于,它通過群體相對獎勵信號進行優化,避免了價值函數近似的復雜性和誤差。同時,它能夠更加有效地利用樣本信息,提高優化的穩定性和收斂速度。在 ARTIST 框架中,GRPO 算法為模型的訓練提供了強大的支持,使得模型能夠在復雜的任務中快速學習和優化,不斷提升推理能力和工具調用策略。
策略模型訓練
策略模型訓練是 ARTIST 框架中的關鍵環節,每一個步驟都精心設計,環環相扣。
首先,采樣策略從舊策略中采樣推理軌跡。在訓練過程中,對于每個問題,從舊策略模型中采樣多個推理軌跡,形成一個小組。這些軌跡包括模型在不同狀態下的動作選擇、工具調用情況以及最終的任務完成結果。采樣過程中,引入一定的隨機性,確保探索的多樣性和穩定性。例如,通過設置不同的采樣溫度參數,可以控制采樣結果的隨機程度。較高的溫度參數會使采樣結果更加隨機,有助于模型探索更多的可能性;較低的溫度參數則使采樣結果更加集中于高概率的動作,有助于模型穩定地優化現有策略。
然后,在生成推理軌跡時,模型在文本推理和工具調用之間靈活切換。模型首先根據當前問題的描述和已有的信息,進行文本推理,生成一段自然語言的推理文本。然后,模型根據推理文本的內容,判斷是否需要調用外部工具。如果需要調用工具,模型會生成一個工具調用指令,包括工具的名稱、輸入參數等信息。工具執行后,返回結果,模型將工具結果整合到推理文本中,繼續進行后續的推理。這個過程不斷重復,直到模型認為任務完成或者達到預設的最大推理步數。例如,在解決一個數學問題時,模型可能先通過文本推理,將問題分解為幾個關鍵步驟,然后調用 Python 解釋器,利用 SymPy 庫執行符號計算,得到結果后,再次回到文本推理,整合信息,最終輸出完整的答案。
獎勵計算則綜合考慮任務完成情況、工具調用成功率、推理深度等多個維度,構建出一個多維度的評價體系。任務完成情況的獎勵根據模型最終是否正確解決了問題來判斷。如果模型成功解決了問題,給予較高的正獎勵;如果未解決,給予負獎勵。工具調用成功率的獎勵根據模型調用工具的次數和成功次數來計算。例如,模型調用了 N 次工具,成功 M 次,那么工具調用成功率的獎勵可以表示為:

最后,模型通過損失掩蔽策略進行更新,聚焦于自身推理和決策部分,避免被工具響應中的噪聲干擾。在更新模型參數時,采用損失掩蔽策略,只對模型生成的文本推理部分和工具調用指令部分計算損失,而對工具返回的結果部分進行掩蔽,不計算損失。這樣做的目的是讓模型專注于自身的推理和決策過程,避免受到工具響應中的噪聲干擾。例如,假設模型生成的推理軌跡為:
<reasoning>推理文本</reasoning>
<tool>工具調用指令</tool>
<output>工具返回結果</output>在計算損失時,只對 <reasoning> 和 <tool> 部分計算損失,對 <output> 部分進行掩蔽。通過這種方式,模型能夠更加專注于自身的推理和決策過程,不斷提升自身的性能。

ARTIST 方法概述
如上圖所示,ARTIST 方法論概述了推理過程如何在內部思考、工具使用和環境交互之間交替進行,通過基于結果的獎勵引導學習。這種機制使模型能夠通過強化學習不斷迭代地優化其推理和工具使用策略。
實驗評估
實驗設置
為了全面評估 ARTIST 框架的性能,實驗涵蓋了復雜數學問題求解和多輪函數調用兩大領域。在復雜數學問題求解方面,精選了 MATH-500、AIME、AMC 和 Olympiad Bench 等多個權威數學基準測試作為評估數據集。這些問題從基礎數學運算到高級數學競賽題目,難度跨度大,全面覆蓋數學推理的各個層面。例如,MATH-500 數據集包含 500 道具有一定難度的數學問題,涵蓋了代數、幾何、概率等多個數學分支;AIME 和 AMC 數據集則是針對美國高中數學競賽的題目,難度較高,需要較強的數學推理和解題能力;Olympiad Bench 數據集更是包含了國際數學奧林匹克競賽級別的高難度題目,對模型的推理能力和工具調用策略提出了極高的要求。
多輪函數調用實驗則選擇了 BFCL v3 和 τ-bench 兩個基準測試。BFCL v3 包含車輛控制、旅行預訂、文件操作等多個場景,充分考驗模型在長對話中的工具調用和狀態維護能力。例如,在車輛控制場景中,模型需要根據用戶的指令,調用車輛控制 API,實現車輛的啟動、加速、剎車等操作;在旅行預訂場景中,模型需要調用旅行預訂 API,查詢航班信息、預訂酒店和租車服務,并根據用戶的反饋進行調整。τ-bench 模擬航空和零售領域的真實對話,要求模型在與用戶的多輪交互中,準確理解用戶意圖,調用相應的函數,完成任務目標。例如,在航空領域,模型需要根據用戶的行程信息,查詢航班狀態、辦理登機手續、查詢行李托運信息等;在零售領域,模型需要根據用戶的購物需求,查詢商品信息、下單購買、查詢訂單狀態等。
評估指標以 Pass@1 準確率為主,直觀反映模型一次性解決問題的能力。Pass@1 準確率是指模型在第一次嘗試中給出正確答案的概率,它能夠很好地衡量模型在實際應用中的性能。例如,在數學問題求解中,Pass@1 準確率反映了模型一次性給出正確答案的能力;在多輪函數調用中,Pass@1 準確率反映了模型在第一次嘗試中完成任務的能力。
實驗中,Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 模型分別上陣,訓練超參數經過精心調試。例如,學習率設置為 (10^{-6}),使用 Adam 優化器,β1 = 0.9,β2 = 0.99,權重衰減為 0.01。每批次采樣 6 個推理軌跡進行訓練,訓練步數根據模型規模和任務難度進行調整。硬件配置也滿足大規模訓練需求,確保實驗結果的可靠性。例如,在復雜數學問題求解實驗中,使用 4 塊 A100 80 GB GPU 進行訓練,總訓練時間為 20 小時;在多輪函數調用實驗中,使用 3 塊 A100 80 GB GPU 進行訓練,總訓練時間為 34 小時。
實驗結果與分析
復雜數學推理
在復雜數學推理領域,ARTIST 模型的表現也令人興奮。以 Qwen2.5-7B-Instruct 模型為例,在 AMC 數據集上,ARTIST 的準確率達到了 0.47,相較于基線模型的 0.35 提升了整整 12.0%。這一顯著的提升充分彰顯了 ARTIST 在處理復雜組合概率問題和多步數學推導時的強大優勢。例如,在解決一個復雜的概率問題時,模型需要先通過文本推理,將問題分解為多個條件概率的計算,然后調用 Python 解釋器,利用 SymPy 庫進行精確的符號計算。在得到初步結果后,模型再次回到文本推理,結合工具輸出結果,對問題進行進一步分析和驗證。如果發現結果有誤,模型會自我修正,重新調用工具,調整計算參數,直至得到正確的答案。這種自我修正能力使得模型在面對復雜問題時能夠不斷優化自己的推理策略,最終找到正確的解決方案。
在更具挑戰性的 Olympiad Bench 數據集上,Qwen2.5-14B-ARTIST 的準確率達到了 0.42,不僅大幅超越了 Qwen2.5-14B-Instruct 基線模型的 0.24,更是以 18.0% 的絕對優勢領先于 GPT-4o 的 0.29。這表明,通過強化學習驅動的工具調用,ARTIST 能夠在復雜數學問題求解中實現更精準、更高效的推理。例如,在解決一個高難度的數學競賽題目時,模型需要進行多步復雜的推理和計算。它通過調用外部工具,如 Python 解釋器和數學計算庫,進行精確的符號計算和數值計算,從而得到準確的結果。同時,模型還能夠根據任務的復雜程度,動態調整推理深度和工具調用策略,確保在有限的計算資源下,實現最優的推理效果。
在 MATH-500 數據集上,雖然問題難度相對較低,但 ARTIST 依然展現出了穩健的性能。Qwen2.5-7B-ARTIST 的準確率為 0.676,較基線模型提升了 5.6%,而 Qwen2.5-14B-ARTIST 的準確率更是達到了 0.726,相較于基線模型的 0.7 提升了 2.6%。這說明,即使在對模型內部知識要求較高的情況下,ARTIST 依然能夠通過工具調用和強化學習優化推理過程,實現性能提升。例如,在解決一個基礎數學運算問題時,模型雖然主要依賴內部知識進行推理,但也會在必要時調用外部工具進行驗證和優化,從而確保推理結果的準確性。

在四個數學推理基準測試中的Pass@1準確率。ARTIST始終優于所有基線模型,尤其是在復雜任務
如上表所示,ARTIST 在四個數學推理基準測試中的 Pass@1 準確率表現優異,尤其是在復雜的 AMC、AIME 和 Olympiad 數據集上,顯著優于所有基線模型。

Qwen2.5-7B-Instruct:在數學數據集上的表現
如上圖所示,Qwen2.5-7B-Instruct 模型在數學數據集上的性能表現,清晰地展示了 ARTIST 在不同難度任務上的優勢。

Qwen2.5-14B-Instruct: 在數學數據集上的表現
如上圖所示,Qwen2.5-14B-Instruct 模型在數學數據集上的性能表現,進一步證明了 ARTIST 在處理復雜數學問題時的強大能力。

在所有數學數據集上的平均獎勵分數、工具調用以及響應長度指標(ARTIST與Base-Prompt+Tools對比)
如上圖所示,ARTIST 在所有數學數據集上的平均獎勵分數、工具調用次數和響應長度指標表現,與基線模型 Base-Prompt+Tools 相比,ARTIST 在獎勵分數和工具調用次數上顯著優于基線模型,同時在響應長度上也表現出更深入的推理過程。
多輪函數調用
在多輪函數調用領域,ARTIST 的表現同樣優秀。在 BFCL v3 的 Long Context 子任務中,Qwen2.5-7B-ARTIST 的準確率達到了 0.13,相較于基線模型的 0.04 提升了 9.0%。這一顯著的提升充分展示了 ARTIST 在處理長對話和復雜場景時的卓越能力。例如,在一個長對話的車輛控制場景中,模型需要根據用戶的多輪指令,調用車輛控制 API,實現車輛的啟動、加速、剎車等操作。在這個過程中,模型需要精準地維護對話狀態,理解用戶的意圖,并根據實時反饋調整操作策略。ARTIST 通過強化學習訓練,學會了在多輪交互中靈活調用工具,高效地完成任務。
在 τ-bench 的 Airline 和 Retail 子任務中,ARTIST 的準確率分別達到了 0.26 和 0.24,相較于基線模型的 0.12 和 0.18,分別提升了 140% 和 33.3%。這表明,ARTIST 能夠在多輪交互中精準地維護狀態,靈活地調用工具,并有效地恢復錯誤,從而實現高效的對話管理和任務完成。例如,在航空領域的對話中,模型需要根據用戶的行程信息,查詢航班狀態、辦理登機手續、查詢行李托運信息等。在這個過程中,模型可能會遇到各種意外情況,如航班延誤、行李超重等。ARTIST 能夠根據實時反饋,靈活調整策略,調用相應的函數,解決這些問題,確保任務的順利完成。
與 Meta-Llama-3-70B 等前沿模型相比,ARTIST 在 BFCL v3 的 Long Context 子任務上也展現出了強大的競爭力,準確率超過了 Meta-Llama-3-70B 的 0.095。在 τ-bench 的 Airline 子任務上,ARTIST 的準確率更是達到了 0.26,是 Meta-Llama-3-70B 的兩倍。這充分證明了 ARTIST 在多輪函數調用任務中的高效性和準確性。例如,在一個復雜的旅行預訂場景中,模型需要根據用戶的需求,調用多個旅行預訂 API,查詢航班信息、預訂酒店和租車服務,并根據用戶的反饋進行調整。在這個過程中,模型需要精準地維護對話狀態,靈活地調用工具,并有效地恢復錯誤。ARTIST 通過強化學習訓練,學會了在多輪交互中靈活調用工具,高效地完成任務,展現了強大的競爭力。

在五個多輪多步函數調用基準測試中,Pass@1 準確率的表現情況。ARTIST 一致優于基線模型,尤其是在復雜任務上
如上表所示,ARTIST 在五個多輪多步函數調用基準測試中的 Pass@1 準確率表現優異,尤其是在復雜的 Long Context、Airline 和 Retail 數據集上,顯著優于所有基線模型。

Qwen2.5-7B-Instruct:在τ-bench和BFCL v3數據集上的多輪函數調用性能
如上圖所示,Qwen2.5-7B-Instruct 模型在 τ-bench 和 BFCL v3 數據集上的性能表現,清晰地展示了 ARTIST 在多輪函數調用任務中的優勢。

不同訓練階段BFCL v3的平均獎勵得分
如上圖所示,ARTIST 在 BFCL v3 數據集上不同訓練步驟的平均獎勵分數表現,展示了模型在訓練過程中的學習曲線和性能提升。

在τ -bench上對多輪函數調用的指標分析
如上圖所示,ARTIST 在 τ-bench 數據集上的多輪函數調用指標分析,包括推理長度、工具調用次數和任務完成步數等,進一步證明了 ARTIST 在多輪交互任務中的高效性和準確性。
案例研究
復雜數學推理案例
下面通過一個具體的復雜數學推理案例來深入剖析 ARTIST 的推理過程。假設任務是求解一個復雜的積分問題,模型首先通過文本推理,將問題分解為幾個關鍵步驟。例如,問題是一個定積分的計算,模型通過文本推理,確定需要計算積分的上下限和被積函數。接著,它調用 Python 解釋器,利用 SymPy 庫執行符號計算。在調用工具時,模型生成如下工具調用指令:
from sympy import symbols, integrate
x = symbols('x')
result = integrate(x**2 + 1, (x, 0, 1))
print(result)工具執行后返回結果 ,模型將這個結果整合到推理文本中,繼續進行后續的推理。如果發現結果與預期不符,模型會自我修正,重新調用工具,調整計算參數。例如,如果模型發現被積函數可能有誤,它會重新生成工具調用指令,修正被積函數,再次調用工具。這種自我修正能力使得模型在面對復雜問題時能夠不斷優化自己的推理策略,最終找到正確的解決方案。
在這個過程中,ARTIST 展現出了自我精煉、自我修正和自我反思的智能體行為。例如,當模型發現初始調用工具得到的結果與預期不符時,它會仔細檢查推理過程,找出問題所在,然后調整策略,重新調用工具。這種自我修正能力使得模型在面對復雜問題時能夠不斷優化自己的推理策略,最終找到正確的解決方案。
多輪函數調用案例
在多輪函數調用案例中,假設任務是為用戶規劃一次旅行,包括預訂機票、酒店和租車服務。ARTIST 首先通過文本推理,理解用戶的需求和偏好。例如,用戶希望從北京出發,前往上海,行程為 3 天,預算為 5000 元。模型根據這些信息,調用航班查詢工具,獲取符合用戶要求的航班信息。工具調用指令如下:
{
"function":"search_flights",
"args":{
"departure":"北京",
"destination":"上海",
"departure_date":"2024-06-01",
"return_date":"2024-06-03",
"budget":5000
}
}工具返回多個航班選項,模型根據用戶的偏好,選擇一個合適的航班,并繼續推理。接著,模型調用酒店預訂工具,根據用戶的預算和偏好,為用戶推薦合適的酒店。工具調用指令如下:
{
"function":"book_hotel",
"args":{
"city":"上海",
"check_in_date":"2024-06-01",
"check_out_date":"2024-06-03",
"budget":3000,
"preferences":["靠近市中心","有免費早餐"]
}
}工具返回酒店預訂成功的信息后,模型調用租車服務工具,為用戶安排租車事宜。工具調用指令如下:
{
"function":"rent_car",
"args":{
"city":"上海",
"pick_up_date":"2024-06-01",
"return_date":"2024-06-03",
"budget":1000
}
}在整個過程中,模型不斷地與用戶進行交互,根據用戶的反饋調整計劃。如果在某個環節出現問題,例如航班信息不準確或酒店預訂失敗,模型能夠迅速恢復錯誤,重新調用工具,尋找替代方案。通過強化學習,ARTIST 學會了在多輪交互中靈活調用工具,高效地完成復雜任務。
總結
ARTIST 框架通過將智能體式推理、強化學習和工具集成緊密結合,成功地解決了 LLM 在處理現實問題時的局限性。ARTIST 不僅提出了一個統一的智能體式 RL 框架,還實現了通用的工具使用和環境交互,并在多個領域和任務中進行了有效的評估。這一創新思路為 LLM 其能夠更好地適應復雜多變的現實世界需求。
在實驗中,ARTIST 在復雜數學問題求解和多輪函數調用任務中均展現出了卓越的性能。在數學推理方面,它能夠精準地調用外部工具,進行高精度計算,從而在高難度任務中取得顯著優勢。例如,在 Olympiad Bench 數據集上,Qwen2.5-14B-ARTIST 的準確率達到了 0.42,大幅領先于基線模型和前沿模型 GPT-4o。在多輪函數調用任務中,ARTIST 憑借其強大的狀態維護和錯誤恢復能力,高效地完成了復雜任務。例如,在 τ-bench 的 Airline 子任務中,ARTIST 的準確率達到了 0.26,是 Meta-Llama-3-70B 的兩倍。這些實驗結果充分證明了 ARTIST 在處理復雜任務時的高效性和準確性,為實際應用提供了有力的支持。
盡管 ARTIST 取得了顯著的成果,但仍然存在一些局限性。例如,在某些復雜場景下,模型的性能仍有提升空間。特別是在面對高度動態和不確定性的任務時,模型的決策過程可能會受到干擾,導致性能下降。還有,對特定工具的依賴可能導致兼容性問題。如果外部工具的接口或功能發生變化,模型可能需要重新調整和優化。將來可以優化算法,提高模型的泛化能力,拓展工具集成的范圍和靈活性,從而進一步提升 ARTIST 的性能。例如,可以通過引入更多的訓練數據和更復雜的任務場景,增強模型的適應能力;同時,開發更加通用的工具接口,減少對特定工具的依賴,提高模型的魯棒性。
現在我們構想一下現實中可能的應用場景。我們可以將它擴展到醫療、金融等更多樣化的領域,整合更豐富的反饋形式,如人類偏好,以提升模型的決策質量。例如,在醫療領域,模型可以通過調用醫學知識庫和診斷工具,為患者提供個性化的治療方案;在金融領域,模型可以通過調用金融數據分析工具,為投資者提供精準的投資建議。同時,解決開放環境中所面臨的安全性和可靠性問題也是未來工作的重點。ARTIST 框架不僅為大型語言模型的發展提供了新的思路和方法,還可以通過智能體式推理與工具集成,模型能夠更加靈活地應對各種挑戰。嗯,最后我還想說,一路從 2023 年走過來的 AIer,尤其是玩開源模型的各位同學,看過這篇文章會不會回憶起那時候 finetune 方式的 Agent 模型?此刻,我回憶起那時候的訓練過程時,讓我感受到,現在這篇論文的做法其實是一個進化版,區別在于,過去的方法主要是 finetune,而現在是 RL。