vivo 官網 APP 首頁端智能業務實踐

一、前言
vivo官網APP首頁是流量最大的頁面,承載著新品、活動、商品、其他入口等流量分發的重任。在流量分發上,云端針對首頁的主要場景建設了算法支撐。通過梳理首頁的場景發現,智能硬件樓層場景的商品配置還是運營純手工動態配置,而非算法推薦。為此,我們探索了端智能技術,將其運用在智能硬件樓層場景,用于提升商品分發效率,進而提升智能硬件樓層場景的點擊率。
端智能廣義上來說,是指將人工智能算法部署到端側設備中,使端側設備具備感知、理解和推理能力;狹義上來說,端智能就是將機器/深度學習算法集成到端側設備中,通過算法模型處理端側感知的數據從而實時得到推理結果。而所謂的“端”實際上是相對于“云”的概念,是一些帶有計算能力的個體設備,如手機、家庭路由器、網絡的邊緣節點等。因此,可以看到端智能的應用離不開這幾個關鍵點:數據、算法模型及計算能力。
二、抽象問題
端智能是如何提高vivo官網APP首頁智能硬件樓層場景的商品分發效率的呢?在回答這個問題之前,我們先了解下智能硬件樓層場景,如下圖所示:

圖1:vivo官網APP首頁-智能硬件樓層
智能硬件樓層場景,有4個商品展示資源位,由運營在眾多的智能硬件商品中挑選出4個商品進行配置。所以,不同的用戶群體進入到vivo官網APP首頁看到該場景下的商品都是相同的。而引入端智能技術要解決的問題是:不同的用戶群體看到的商品推薦是不一致的,是更加符合該用戶群體的商品,做到推薦的精準匹配,如下圖所示:

圖2:智能硬件樓層商品分發
端智能推薦分發,就是在智能硬件資源池中推薦最適合的4個商品展示在智能硬件樓層場景中。我們抽象下問題,也就是在N個商品中選取前K個商品(K<=N)進行展示,進一步思考下,如何選取前K個商品呢?其實本質是將N個商品按照推薦的概率值進行排序,選取概率值較大的前K個商品。因此,問題就可以進一步被抽象為設計一個算法模型,通過對用戶群體的特征分析,輸出該用戶群體對N個商品感興趣的概率值。
三、端智能方案
為什么是使用端智能技術,而不是使用人為約束規則或者云端模型來解決“針對某個用戶群體,N個商品被推薦的概率值”的問題呢,是因為端智能技術的優勢是:
- 推理計算是在端側進行的,可以有效地節約云端計算資源及帶寬;
- 因為在端側進行,響應速度相較于網絡請求會更快;
- 端側的數據處理是本地的,數據隱私更安全;
- 算法模型是使用深度學習算法通過訓練樣本學習出來的,而非人工規則約束,因此可以應對復雜的場景,做精細化的推薦。
3.1 整體架構
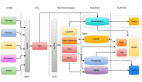
vivo官網APP端智能整體架構設計如下:

圖3:vivo官網APP端智能整體架構
端智能整體架構主要由模型離線訓練、云端配置、APP端執行三大模塊構成,離線訓練主要負責算法模型的訓練生成、模型轉換以及模型發布;云端主要負責模型版本管理和模型運行及埋點監控;APP端在業務調用的時候主要負責計算推理,通過設備感知數據,將其通過特征工程處理后輸入到算法模型中,模型在TensorFlow-Lite的基礎上充分調用設備計算資源進行推理得到結果后反饋給業務使用。
離線訓練:將原始數據進行數據清洗后,送入到設計的特征工程中處理為算法模型能夠處理的特征。然后使用TensorFlow深度學習語言搭建網絡模型,并使用處理后的數據進行訓練得到后綴為.h5的模型文件,需要將該模型文件通過模型轉換為后綴為.tflite的文件,因為.tflite的文件是可以在Android上通過TensorFlow-Lite工具庫加載并執行推理。
云端:每次模型的訓練都有相應的版本控制及監控能力,這樣方便做模型的ABTest實驗,也可以動態的升級和回退線上模型版本。
APP端:Google提供了TensorFlow-Lite機器學習工具庫,在此庫上可以加載后綴為.tflite的模型文件,并提供了執行前向計算推理能力。因此,在此基礎上,APP端側通過實時地感知數據,并通過特征工程處理后得到特征數據后,可以在端側利用TensorFlow-Lite提供的能力進行加載模型并運行模型,進而實時得到計算推理結果。
3.2 原始數據
無論是離線的訓練模型,還是APP端側的計算推理都離不開“數據”,因為數據是整個架構的靈魂所在。所以,在明確了要解決問題的前提下,就需要全面梳理埋點上報信息,查看下當前擁有的數據信息,如下圖所示:

圖4:原始數據特征
從上圖可以看到能夠獲取到很多緯度的數據信息,但是在能夠被利用之前,要先進行數據清洗工作。并不是每個信息都會包含這些緯度的信息、也并不是每個緯度的信息都同樣重要,所以要結合場景來做數據的清洗。例如,在智能硬件樓層場景下,基礎信息設備型號很重要,因為這個信息代表著當前用戶使用的是哪款手機型號,所以在數據清洗時,若此信息采集時是為空,則需要設計默認值的方式進行處理。
在完成了數據清洗工作后,就可以進行下一步動作了,將設備型號、性別、所在城市等語義信息,通過特征工程處理為能夠輸入到算法模型處理的特征信息。在本文案例中,我們以基礎信息為例子來展開介紹,基礎信息如手機設備型號、當前用戶所在城市、用戶性別等。舉例,若一個男性用戶在使用x200手機訪問vivo官網APP,并且授予vivo官網APP定位權限,獲取的定位在南京,則當前獲取一條原始數據為“vivo x200,南京,男”。
3.3 特征工程
獲取的原始數據是自然語言的特征,需要將其處理為算法模型能夠處理的數字化表示形式的離散特征。現在AI大模型層出不窮,可以很好地處理自然語言,輸入的自然語言可以通過Embedding模型或者Word2Vec進行特征處理,將自然語言處理為模型能處理的“0.1 0.6 ... 0.4”形式,如下圖所示:

圖5:語義特征
通過Embedding模型處理的特征是具有語義相似性的,但回歸本文,我們并不需要這種具有語義相似性的特征。輸入的特征緯度越大,則模型的復雜度就越高,而需要的計算資源也就越高。在端側做計算推理,在滿足業務需求的前提下,算法模型要足夠小,因此我們化繁為簡,采用簡單的方式來處理原始數據。這個時候,我們回顧下原始數據“vivo X200,南京,男”,這幾個特征實際上是并列關系,我們可以逐個地處理為One-Hot編碼特征表示,然后再組裝。
3.3.1 位置特征
我們以地理位置信息為例,用戶可以分布在全國的各個地方,如在北京、上海、南京、重慶等,因此,我們需要找到一定的規律來處理地理位置信息。這個時候需要通過大數據的方式,大致了解到城市消費的平均價位信息的分布情況,像北京、上海等城市消費趨勢相當;像武漢、合肥等城市消費相當。因此,我們可以根據此反映出來的現象,將消費趨勢一致的城市歸為一個聚類。例如,可以簡單劃分為三個聚類,分別是聚類A、聚類B、聚類C,通過這樣的方式,就可以將不同的城市劃分到這三個聚類中去。如“南京”屬于聚類A,“揚州”屬于聚類B等。再進行抽象下,可以使用三位數字(000)這種形式表示聚類。第一位數字0表示不是聚類A,數字是1則表示是聚類A,這樣就可以通過三位數字來表示地理位置信息了。如,可以通過“100”來代表“南京”。
默認值處理:如果此時獲取不到地理位置信息,可以按一定策略處理獲取不到的信息進行填充,如,新增一位聚類D表示是沒有獲取到地理位置信息,亦或者將其都籠統歸納為聚類C。
3.3.2 設備型號
我們再看下,如何處理手機設備名稱特征的。隨著手機的更新迭代,市場上的手機名稱也枚不勝舉。但是,每款手機都是有其定位的,而這個定位實際上是可以通過手機發布的系列能夠得知的。如,vivo X200手機是旗艦機型,屬于vivo的X系列。參考地理位置信息通過聚類的分類方法,我們也可以簡單地將設備機型名稱通過系列來做區分。在vivo官網APP的選購頁面,可以看到vivo品牌下有三個系列機型,分別是X系列、S系列和Y系列。因此,我們如法炮制,也可以使用三位數字(000)這種形式來表示設備機型名稱。例如:第一位數字0表示不是X系列手機,1表示是X系列手機;同理第二位數字0表示不是S系列手機,1表示是S系列手機等。因為,vivo X200屬于X系列,所以可以將其vivo X200原始數據處理為“100”來表示,同理如果此時獲取手機設備是vivo S20 Pro,則被轉換為抽象的特征“010”來表示。
默認值處理:參考位置特征的處理方式,可以新增一位One-Hot特征表示UnKnow,即未獲取手機設備名稱特征時,UnKnow這一列數字為1,反之為0。
3.3.3 性別特征
性別可以使用3位數字(000)表示,第一位表示女性,第二位表示男性,使用第三位表示未獲取性別時的默認值。如,“男”可以通過“010”表示。
3.3.4 特征組合
因此,通過上述的處理規則,就可以將一條原始數據“vivo x200,南京,男”處理為“1001000010”來表示了,如下圖所示:

圖6:特征組合
特別需要注意的是,自然語言特征組合的順序和處理后的數字化特征順序一定是保持一致的。
3.4 算法模型
3.4.1 算法模型整體架構
算法模型整體架構如下圖所示:

圖7:算法模型整體架構
由三部分構成:分別是輸入層、隱藏層及輸出層。
- 輸入層:是經過特征工程處理后的特征,主要是用戶基礎信息和實時上下文信息。
- 隱藏層:由多層全連接神經網絡組成,使其擁有非線性變化能力,可以在更高緯度空間中逼近尋找擬合特征的最優解。
- 輸出層:第一個輸出層是將每個分類商品打上標簽,輸出該標簽概率集合;第二個輸出層是在第一個輸出層的基礎上直接通過模型中存入的標簽和商品SkuId映射關系,直接輸出商品SkuId集合。
在設計算法模型的時候,要選擇適合貼近要處理的場景,而非盲目地選擇大模型做基座或者搭建很深的模型。不僅需要考慮模型的預測準確率,還需要考慮端側的計算資源。
3.4.2 模型代碼示例
算法模型的核心代碼,如下示例:
# 輸入層
input_data = keras.layers.Input(shape=(input_size,), name="input")
output = tf.keras.layers.Dense(64, activatinotallow="relu")(input_data)
output = tf.keras.layers.Dense(128, activatinotallow="relu")(output)
output = tf.keras.layers.Dense(output_size, activatinotallow="softmax")(output)
# 輸出層:top k index
output = NewSkuAndFilterPredictEnvSkuIdLayer(index_groups=acc.index_groups, )(output)
# 輸出層:index 映射 skuid 直接出
output = SkuTopKCategoricalLayer(acc.skuid_list, spu_count=len(acc.spuid_list))(output)3.4.3 模型訓練
原始數據:訓練模型的原始數據是來源于大數據提供的埋點信息數據,例如獲取當前日期前3個月的埋點信息數據。
數據清洗:并不是所有的原始數據都可以拿來直接使用,有部分數據是不符合約束條件的,稱之為臟數據,即將不滿足約束規則的臟數據清理后,則可以獲得真正的用于訓練模型的數據。
2:8分割原則:為了驗證模型訓練的Top5的準確率,將清洗后的數據,80%分為訓練數據、20%分為測試數據;需要注意的是,訓練數據在真正訓練的時候,需要使用shuffle來打散,可以增強模型的魯棒性。
代碼示例:
train_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
test_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
# 使用shuffle方法對數據集進行隨機化處理
# 參數 buffer_size 指定了用于進行隨機化處理的元素數量,通常設置為大于數據集大小的值以確保充分隨機化、batch() 則指定了每個批次的數據量。
train_dataset = train_dataset.shuffle(buffer_size=datasets.train_len).batch(config.BATCH_SIZE)
test_dataset = test_dataset.shuffle(buffer_size=datasets.test_len).batch(config.BATCH_SIZE)
# 獲取模型輸入、輸出緯度大小
acc_input_size = datasets.acc_columns - 1
acc_out_size = datasets.acc_output
# 構建模型
model = build_parts_model(acc_input_size, acc_out_size)
optimizer = tf.keras.optimizers.legacy.RMSprop(learning_rate=config.LEARN_RATIO)
model.compile(optimizer=optimizer, loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseTopKCategoricalAccuracy(k=5, name="top5_acc_accuracy")])
model.fit(train_dataset, epochs=config.TRAIN_EPOCH)3.4.4 保存模型
通過13輪epoch的訓練后,獲得TensorFlow模型:
# 保存模型
model.save(f'output/{config.MODEL_NAME}.h5')3.4.5 模型轉換
通過上面的步驟,可以得到在一個后綴名為.h5文件的模型文件,但我們需要將模型部署在APP端側運行,端側運行環境是依賴TensorFlow-Lite工具庫,因此需要將.h5文件的模型轉換為.tflite文件模型。
1.TensorFlow-Lite工具庫
TensorFlow Lite學習指南中的官方介紹表明:“TensorFlow Lite 是一組工具,可幫助開發者在移動設備、嵌入式設備和 loT 設備上運行模型,以便實現設備端機器學習”。簡而言之,端側設備引入TensorFlow Lite工具庫后,就可以加載機器學習模型,并且執行前向計算推理能力。若不使用該工具庫,需要團隊自行研發可以運行在端側的機器學習模型的執行環境,如:裁剪python,保留其核心能力,像字節的pitaya框架。因此,引入該工具庫,對我們團隊來說就可以減少在端側構建執行環境的巨大開發工作量。
2.算子兼容
使用TensorFlow-Lite工具庫的時候,需要考慮算子兼容性問題。TensorFlow Lite內置算子 TensorFlow 核心庫的算子的一部分,可以見下面圖的包含關系:

圖8:TensorFlow算子兼容
(圖片來源:TensorFlow官網)
因此,在使用TensorFlow深度學習語言設計算法模型時,要考慮到算子的兼容性,避免出現在本地可以工作的模型,在端側因為算子不兼容而導致部署失敗。
3.模型轉換
(1)非TensorFlow深度學習語言模型轉換
使用其他深度學習框架訓練的話,可以參考使用如下兩個方式轉換為.tflite文件模型,以Pytorch深度學習框架語言為例
根據Pytorch的代碼,使用TensorFlow重寫,得到TFLite文件
使用工具ONNX轉換
若使用ONNX工具,則轉換的鏈路是這樣的:PyTorch -> ONNX -> TensorFlow -> TFLite
(2)TensorFlow深度學習語言模型轉換
使用TensorFlow深度學習語言訓練的話,可以直接使用下述代碼,轉換為Android端側可以加載的模型文件.tflite

圖9:TensorFlow模型轉換
(圖片來源:TensorFlow官網)
模型轉換代碼示例如下:
1、Keras Model
訓練過程中,直接將model轉成tflite
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# 轉換模型
tflite_float_model = converter.convert()
# 保存模型
with open('mnist_lenet5.tflite', 'wb') as f:
f.write( tflite_float_model)
2、SavedModel
model.save('mnist_lenet5_save_model', save_format='tf')
# 轉換模型
converter = tf.lite.TFLiteConverter.from_saved_model('mnist_lenet5_save_model') tflite_model = converter.convert()
# 保存模型
with open('mnist_lenet5_saved_model_dir.tflite', 'wb') as f:
f.write(tflite_model)3.5 計算推理
Google提供了TensorFlow Lite庫,可以加載TFLite文件,并在端側利用本地計算資源完成推理,注意這里只是有推理能力,而不提供訓練。如下所示:
dependencies {
implementation 'org.tensorflow:tensorflow-lite:2.14.0'
}通過添加模塊依賴項將TensorFlow Lite庫引入到APP應用中。
3.5.1 加載模型
假設現在模型文件是放在assets文件目錄下,那么首先先加載模型,構建Interpreter對象,如下代碼:
private Interpreter mTfLite = new Interpreter(loadModelFileFromAssets("文件名"))3.5.2 模型運行推理
加載好模型文件后,就可以直接調用推理API了,推理API提供了兩個,分別是:
// 通過API的名稱其實就能夠看出區別了,run()是單個輸入調用,runForMultipleInputsOutputs是多個輸入調用,
// run方法實際執行時也是調用runForMultipleInputsOutputs
// 實際上mTfLite .run()底層
mTfLite .run()
mTfLite .runForMultipleInputsOutputs()因此,只需要準備好輸入和輸出數組即可直接調用,如下代碼所示:
// 輸入數組
float[][] inputDataArray = new float[][]{inputDataArrayLen};
// 輸出數組
float[][] outputDataArray = new float[1][outputDataLen];
// 運行推理
mTfLite .run( inputDataArray , outputDataArray);四、方案落地
4.1 模型配置
在設計算法模型之初,需要考慮輸入和輸出緯度大小,盡量將輸入和輸出的緯度固定下來,這樣的話當不斷迭代算法模型時,就不會因為輸入和輸出緯度不一致導致不能兼顧到之前的APP版本,進而做到模型可動態升級。在模型配置中心管理模型版本、下發策略,在端側下載模型時可通過模型版本號及文件MD5值校驗模型文件的完整性。
4.2 運行監控
模型上線后,需要監控線上執行的效果。主要關注三個指標:
- 模型運行成功率:加載模型、執行模型上報是否成功
- 模型版本分布:模型版本升級情況,便于分析數據
- 模型各版本的平均運行時長:關注運行時長,進而指導模型設計時考慮模型的復雜程度

圖10:模型運行監控
如上圖所示,通過建立完善的線上監控,一方面清楚了解模型運行情況,另一方面可以提供設計算法模型的方向,進而更好地迭代出一個模型,可以在端側設備計算資源及收益效果達到一個各方都還不錯的平衡點。
五、總結
要使用端智能能力,首先要知道解決什么問題。如,本文是解決的“重排序”問題,其實本質就是“多分類”問題。知道了具體解決的問題后,要進一步抽象出輸入是什么、輸出是什么。此時,還需要盤點當前能夠獲取哪些原始數據,并設計特征工程去處理好原始數據,將其轉換為算法模型能夠接受的特征。再緊接著,就是要結合應用場景設計好算法模型即可。
本文通過利用端智能重排序云端返回的商品信息,進而不同人群展示不同商品信息,實現千人千面效果。從獲取原始數據開始,到特征工程的設計,設計符合該業務場景的算法模型,然后進行訓練獲取模型,再進行模型轉換為TFLite文件格式,通過端側加載該模型后,進行計算推理獲取重排序后的結果。
在端智能的道路上,一方面我們繼續探索更多的落地場景,另一方面繼續挖掘豐富的端側數據,更新迭代特征工程及算法模型,更好地為業務創造價值。