













面向B端算法實時業務支撐的工程實踐
一、 背景
在營銷場景下,算法同學會對廣告主提供個性化的營銷工具,幫助廣告主更好的精細化營銷,在可控成本內實現更好的ROI提升。我們在這一段時間支持了多個實時業務場景,比如出價策略的實時化預估、關鍵詞批量服務同步、實時特征等場景,了解到業務側同學來說,針對ODPS場景來說大部分可以靈活使用,但對于Blink使用還有不足,我們這里針對場景積累了一些經驗,希望對大家有一些幫助。
二、 技術選型
為什么要選擇Blink?大部分離線場景如果對于時效性沒有要求,或者數據源是Batch模式的,非Streaming的(比如TT、SLS、SWIFT、順序)等,這個場景的話選擇ODPS就比較不錯;總體來說,數據源是實時的(如TT/SLS/SWIFT)、需要順序讀取ODPS、對時效性要求高的場景,選擇Blink是比較好的。
Blink目前也是支持Batch模式和Steaming模式。Batch模式是指有固定的起始時間和結束時間, 相比ODPS而來,他最大的優勢是提前申請資源,可是獨占的,這樣可以保障時效性;Streaming模式就是傳統意義上的實時消費,可實現毫秒級的處理。
從開發模式上看,主要分為Data Stream模式,類似于ODPS MR;第二種是SQL模式;從易用性角度看,SQL無疑是使用成本最低的;但對于復雜場景,Data Stream的掌控能力也是最好的,可靈活定義各類cache和數據結構,以及同時支持多類場景。
特點 | 優勢 | |
Datastream Batch | 有固定起始時間和結束時間 | 提前申請資源 |
Datastream Streaming | 更細粒度地控制實時計算作業 | 實時性較強,自定義source和sink |
BlinkSQL Streaming | 簡單場景快速上手 | 使用成本低 |
ODPS | 批量作業開發 | 吞吐量較大 |
三 、主要場景
1. 實時replay出價策略評估
業務背景
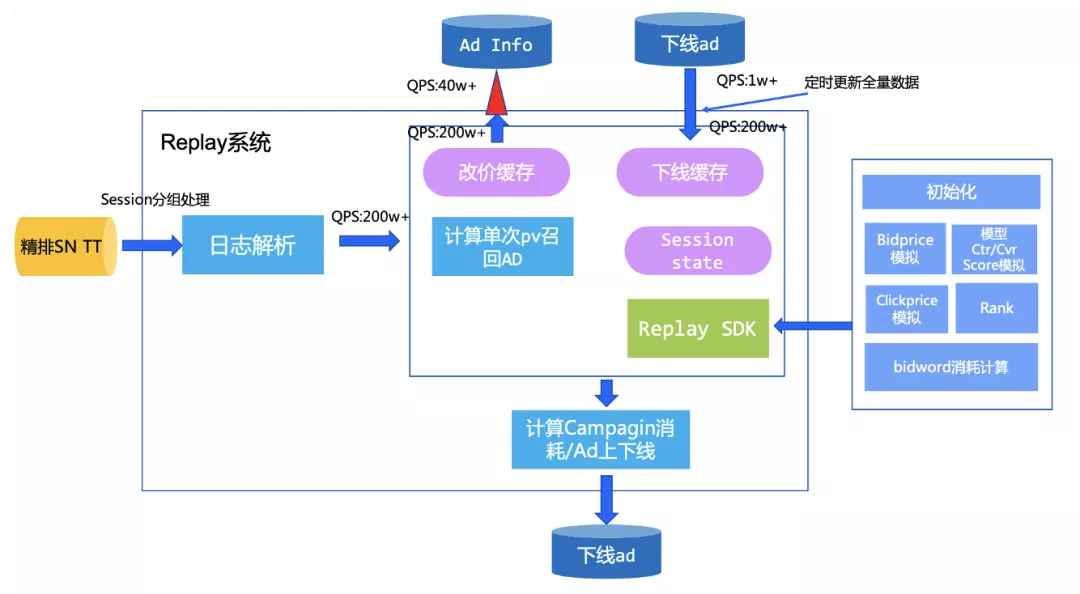
Replay系統是一套集線上競價日志搜集、結構化、后續處理的模擬系統。該系統記錄了直通車線上引擎在召回之后的競價信息,主要涵蓋了線上的召回、出價、打分等隊列信息。結合排序以及扣費公式,可以利用該日志實現對線上競價環境的模擬。簡單來說,就是可以評估bidword上如果當時采用其他的出價,會帶來什么樣的結果。通過replay系統,算法團隊和廣告主可以在線上AB測試之前,利用離線流量預估用戶策略修改之后帶來的效果,這樣可以盡可能地減少策略的修改帶給線上的影響,讓結果變得更加可控。同時在進行負向策略測試的過程中,可以盡可能地減少對大盤的收益影響。
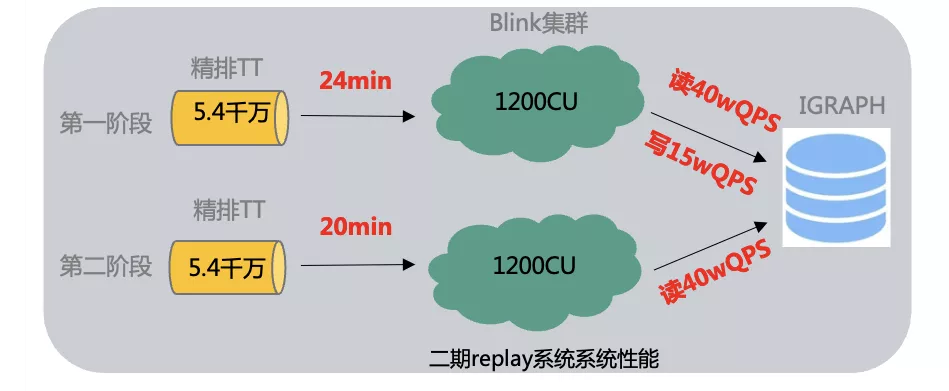
算法團隊希望基于在線精排召回日志實現業務側多種出價策略評估,回放1天內采樣日志(10億數據),在出價策略上評估,并支持ad的實時下線,避免下線ad對出價策略有影響,并且預期希望10億數據量在1-2個小時內跑完。
主要挑戰
- 1千萬物料數據如何加載;
- 高qps(100萬)下線ad的實時同步;
- 業務側解耦,整個實時job鏈路如何實現和業務解耦
解決方案
物料數據加載:直接在blink啟動時加載所有數據,避免高qps情況下,對igraph訪問造成壓力;另外采用廣播模式,僅一次加載,每個節點都可以使用,避免多次加載odps數據;
下線的ad信息采用分桶的方式存入到IGraph中,并周期性cache方式全量讀取全量下線ad,將查詢的200W+qps控制在1w左右,并使用RateLimit限流組件控制訪問并發,把IGraph并發控制限制在40萬左右,實現整體流量平滑;
整體實時工程框架,預留UDF接口,讓業務側僅實現SDK即可,其他工程性能、并發、限流、埋點等邏輯內部實現即可,支持工程框架和算法策略Replay解耦。
總結
基于此業務需求,我們基于blink streaming Batch模式的靈活能力,實現了對tt數據固定開始和結束時間的數據處理。沉淀了讀寫tt組件 ,ODPS組件,iGraph組件和埋點組件 ,這些沉淀的組件很好地支持了后續相似業務的作業開發,同時組件作為之后作業產品化提供了基礎能力。
2. 實時特征
業務背景
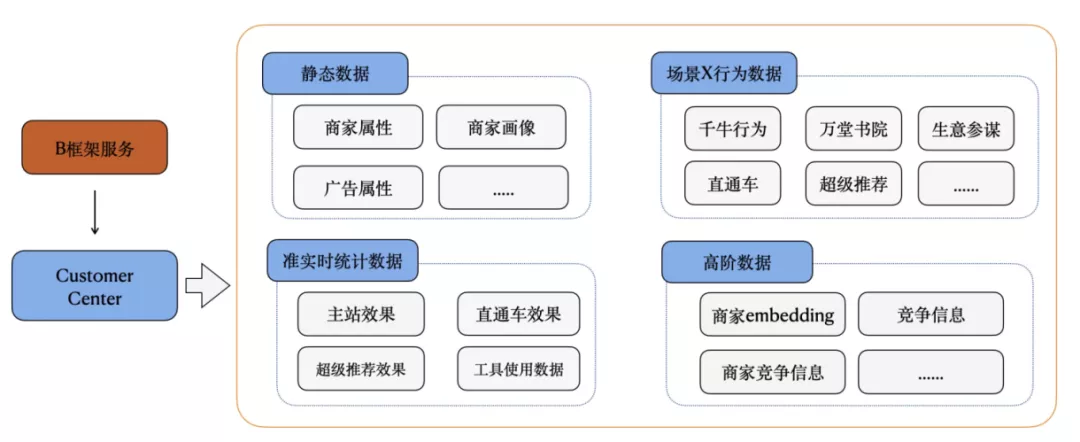
隨著B端算法發展,模型升級帶來的增量紅利越來越少,需要考慮從客戶實時信息方面進一步捕捉用戶意圖,更全面、更實時的挖掘潛在需求,從B端視角進一步提升增長空間,基于線上用戶行為日志產出用戶行為實時特征,算法團隊使用實時數據改進線上模型。
基于此需求我們產出一條用戶實時特征產出鏈路,通過解析上游A+數據源獲取用戶實時特征,實時特征主要包含以下幾種:
- 獲取用戶近50條特征數據值,并產出到igraph中。
- 輸出具有某種特征的用戶id,并按照分鐘時間聚合
- 輸出某種特征近1小時的和、均值或者數目
主要挑戰
- 實時特征數據開發數量非常多,對于每個特征數據都需要開發實時數據鏈路、維護,開發成本、運維成本較高,重復造輪子;
- 特征數據開發要求開發者了解:
- 數據源頭,會基于事實數據源進行ETL處理;
- 計算引擎,flink sql維護了一套自己的計算語義,需要學習了解并根據場景熟練使用;
- 存儲引擎,實時數據開發好需要落地才能服務,故需要關系存儲引擎選型,例如igraph、hbase、hologres等;
- 查詢優化方法,不同存儲引擎都有自己的查詢客戶端、使用及優化方法,故要學習不同引擎使用方法。
解決方案
從產品設計角度,設計一套實時平臺能力,讓開發實時特征跟在odps開發離線表一樣簡單。產品優勢是讓用戶只需要懂SQL就可以開發實時特征:
- 不需要了解實時數據源
- 不需要了解底層存儲引擎
- 只用sql就可以查詢實時特征數據,不需要學習不同引擎查詢方法
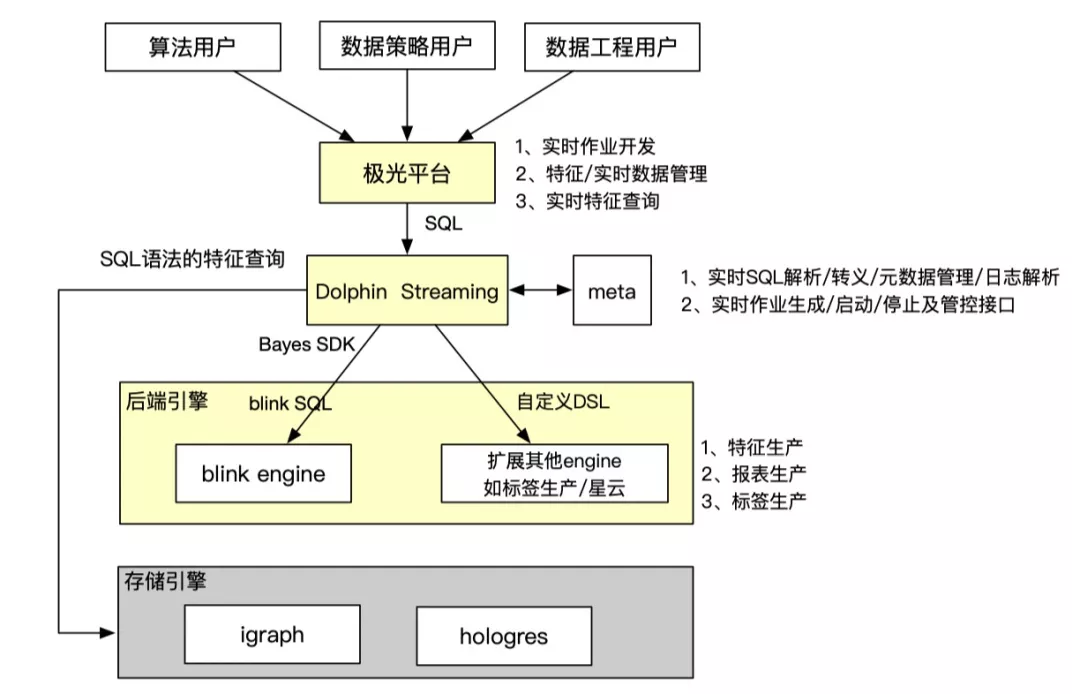
整個實時開發產品聯動極光平臺、dolphin引擎、blink引擎和存儲引擎,把整個流程串聯打通,給用戶提供端到端的開發體驗,無需感知跟自己工作無關的技術細節。
相關平臺介紹:
Dolphin智能加速分析引擎:Dolphin智能加速分析引擎源自阿里媽媽數據營銷平臺達摩盤(DMP)場景,在通用OLAP MPP計算框架的基礎上,針對營銷場景的典型計算(標簽圈人,洞察分析)等,進行了大量存儲、索引和計算算子級別的性能優化,實現了在計算性能,存儲成本,穩定性等各個方面的大幅度的提升。Dolphin本身定位是加速引擎,數據存儲和計算算子依賴于底層的odps, hologres等引擎。通過插件形式,在hologres中,完成了算子集成和底層數據存儲和索引的優化,實現了特定計算場景計算性能和支撐業務規模的數量級的提升。目前Dolphin的核心計算能力主要包括:基數計算內核,近似計算內核,向量計算內核,SQL結果物化及跨DB訪問等。Dolphin同時實現了一套SQL轉譯和優化能力,自動將原始用戶輸入SQL,轉化成底層優化的存儲格式和計算算子。用戶使用,不需要關心底層數據存儲和計算模式,只需要按照原始數據表拼寫SQL,極大的提升了用戶使用的便利性。
極光消費者運營平臺:極光是面向營銷加速場景的一站式研發平臺,通過平臺產品化的方式,可以讓特色引擎能力更好賦能用戶。極光支持的特色場景包含超大規模標簽交并差(百億級標簽圈選毫秒級產出)、人群洞察(上千億規模秒級查詢)、秒級效果歸因(事件分析、歸因分析)、實時和百萬級人群定向等能力。極光在營銷數據引擎的基礎上提供了一站式的運維管控、數據治理以及自助接入等能力,讓用戶使用更加便捷;極光沉淀了搜推廣常用的數據引擎模板,包含基數計算模板、報表模板、歸因模板、人群洞察模板、向量計算模板、近似計算模板、實時投放模板等,基于成熟的業務模板,讓用戶可以零成本、無代碼的使用。
根據目前的業務需求,封裝了實時數據源和存儲數據源使用舉例:
--- 注冊輸入表
create table if not exists source_table_name(
user_id String comment '',
click String comment '',
item_id String comment '',
behavior_time String comment ''
) with (
bizType='tt',
topic='topic',
pk='user_id',
timeColumn='behavior_time'
);
---- 創建輸出表
create table if not exists output_table_name (
user_id STRING
click STRING
) with (
bizType='feature',
pk='user_id'
);
實現實時特征算子:
concat_id:
- 含義:從輸入表輸入的記錄中,選取1個字段,按照timestamps倒序排成序列,可以配置參數按照id和timestamp去重,支持用戶取top k個數據
使用舉例:
-- 用戶最近點擊的50個商品id
insert into table ${output_table_name}
select nickname,
concat_id(true, item_id, behavior_time, 50) as rt_click_item_seq
from ${source_table}
group by user_id;
-- 1分鐘內最近有特征行為用戶id列表
insert into table ${output_table_name}
select window_start(behavior_time) as time_id,
concat_id(true, user_id) as user_id_list
from ${source_table}
group by window_time(behavior_time, '1 MINUTE');
sum、avg、count:
- 含義:從輸入表輸入的記錄中,選取1個字段,對指定的時間范圍進行求和、求平均值或計數
使用舉例
-- 每小時的點擊數和曝光數
insert into table ${output_table_name}
select
user_id,
window_start(behavior_time) as time_id,
sum(pv) as pv,
sum(click) as click
from ${source_table}
group by user_id,window_time(behavior_time, '1 HOUR');
總結
基于B端算法的實時特征需求,沉淀了一套基于blink sql + udf實現的實時特征產出系統,對用戶輸入的sql進行轉義,在Bayes平臺生成bink SQL Streaming任務,產出實時特征數據存入iGraph當中,沉淀了blink 寫入igraph組件,concat_id算子、聚合算子等基礎能力,為后續Dolphin streaming 實時特征產出系統打下了基礎,支持后續多種特征算子擴展方式,快速支持此類用戶需求。
3. 關鍵詞批量同步
業務背景
每天有很多商家通過不同渠道加入直通車;而在對新客承接方面存在比較大的空間。另一方面,對于系統的存量客戶的低活部分也有較大的優化空間。系統買詞作為新客承接、低活促活的一個重要抓手,希望通過對直通車新客和低活客戶進行更高頻率的關鍵詞更新(天級->小時級),幫助目標客戶的廣告嘗試更多關鍵詞,存優汰劣,達到促活的目標。
基于此需求,我們在現有天級別離線鏈路的基礎上補充小時級的消息更新鏈路,用來支持標準計劃下各詞包、以及智能計劃的系統詞更新,每小時消息更新量在千萬量級,使用Blink將全量ODPS請求參數調用faas的函數服務,將每條請求的結果寫入到ODPS的輸出表中。更新頻率在兩個小時,更新時間:早8點到晚22點,單次增刪規模:增500W/刪500W。
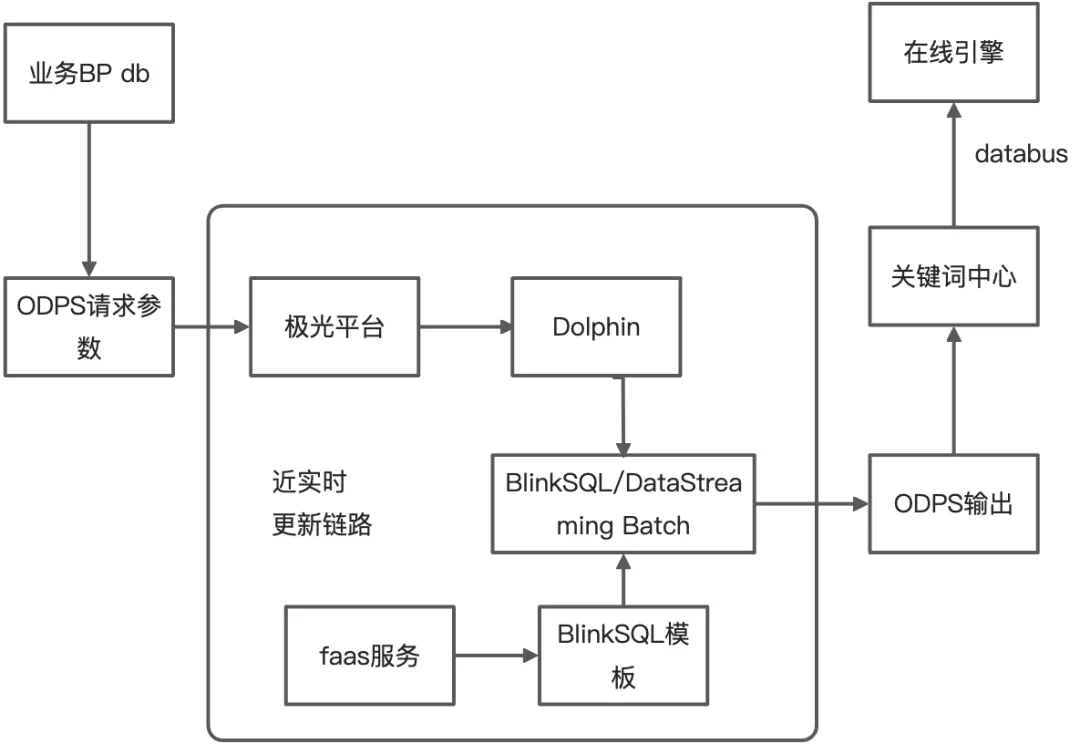
主要挑戰
- blink批處理作業需要進行小時級調度
- faas函數調用需要限流
解決方案
- 使用Blink UDF實現對request請求調用HSF的函數服務功能
- blink UDF使用RateLimiter進行限流,訪問函數服務的QPS可以嚴格被節點并行度進行控制
- 在Dataworks平臺配置shell腳本,進行Bayes平臺批計算任務調度
總結
基于此需求,使用blink sql batch模式實現了近實時的此類更新鏈路,打通了此類批處理作業的調度模式,為后續批作業產品化打下了基礎。
四、 未來展望
基于B端算法的業務,Dolphin引擎目前已經設計開發了Dolphin streaming鏈路,用戶在極光平臺開發實時特征變得跟在odps開發離線表一樣簡單,用戶無需了解實時數據源、底層存儲引擎,只需要用sql就可以查詢實時特征數據。但是B端算法業務中還有類似于本文中提到的批處理業務,這些業務需要開發blink batch sql、blink streaming batch模式、ODPS UDF和java code任務,并且提供調度腳本,最后將項目進行封裝提交給算法團隊進行使用。未來我們希望用戶能夠在極光平臺自助開發批量計算業務,降低算法同學開發成本,提供一個可擴展、低成本的批計算引擎能力,支持業務快速迭代,賦能業務落地快速拿到結果。
學習參考
- 對flink比較感興趣或者是初步接觸flink的同學可以參考以下內容進行一個初步學習:
- Flink官方博客:https://flink.apache.org/blog/
- Flink Architecture:https://flink.apache.org/flink-architecture.html
- Flink技術專欄:https://blog.csdn.net/yanghua_kobe/category_6170573.html
- Flink源碼分析:https://medium.com/@wangwei09310931/flink-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-streamexecutionenvironment-4c1cd9695680
- Flink基本組件和邏輯計劃:http://chenyuzhao.me/2016/12/03/Flink%E5%9F%BA%E6%9C%AC%E7%BB%84%E4%BB%B6%E5%92%8C%E9%80%BB%E8%BE%91%E8%AE%A1%E5%88%92/
























