比自回歸更靈活、比離散擴散更通用,首個純Discrete Flow Matching多模態(tài)巨獸降臨
王勁,香港大學(xué)計算機系二年級博士生,導(dǎo)師為羅平老師。研究興趣包括多模態(tài)大模型訓(xùn)練與評測、偽造檢測等,有多項工作發(fā)表于 ICML、CVPR、ICCV、ECCV 等國際學(xué)術(shù)會議。
近年來,大型語言模型(LLMs)在多模態(tài)任務(wù)中取得了顯著進展,在人工通用智能(AGI)的兩大核心支柱(即理解與生成)方面展現(xiàn)出強大潛力。然而,目前大多數(shù)多模態(tài)大模型仍采用自回歸(Autoregressive, AR)架構(gòu),通過從左到右逐步處理多模態(tài) token 來完成任務(wù),推理缺乏靈活性。
與此同時,基于掩碼的離散擴散模型憑借雙向建模能力也逐漸興起,該架構(gòu)通過雙向信息建模顯著提升了模型的建模能力。例如,DeepMind 的 Gemini Diffusion 驗證了離散擴散在文本建模領(lǐng)域的潛力;在開源社區(qū),LLaDA、Dream 等擴散式大語言模型(dLLM)也催生了如 MMaDA、LaViDA、Dimple 和 LLaDA-V 等多模態(tài)模型。基于掩碼(mask)離散擴散為多模態(tài)任務(wù)提供了一種重要的建模范式。
然而,生成模型的實現(xiàn)方式并不局限于上述兩類架構(gòu),探索新的生成建模范式對于推動多模態(tài)模型的發(fā)展同樣具有重要意義。
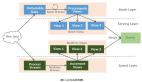
基于這一理念,來自香港大學(xué)和華為諾亞方舟實驗室的研究團隊提出了 FUDOKI,一個基于全新非掩碼(mask-free)離散流匹配(Discrete Flow Matching)架構(gòu)的通用多模態(tài)模型。
與傳統(tǒng)的自回歸方法不同,F(xiàn)UDOKI 通過并行去噪機制實現(xiàn)了高效的雙向信息整合,顯著提升了模型的復(fù)雜推理和生成能力。與離散擴散架構(gòu)相比,F(xiàn)UDOKI 采用更加通用的概率路徑建模框架,從均勻分布出發(fā),允許模型在推理過程中不斷更新和修正生成結(jié)果,為多模態(tài)模型打開了一條嶄新的技術(shù)路徑。

- 論文標(biāo)題:FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
- 論文鏈接:https://arxiv.org/abs/2505.20147
- 項目主頁:https://fudoki-hku.github.io/
FUDOKI 的核心亮點包括如下:
- 統(tǒng)一架構(gòu):一套簡單直觀的框架搞定圖像生成與文本理解
- 徹底去掩碼:無需掩碼(mask)策略,與 mask-based discrete diffusion 相比更通用
- 支持動態(tài)修正:生成過程可實時調(diào)整,更接近人類推理方式
- 性能對標(biāo) / 超越同參數(shù) AR 模型(在 GenEval & 多模態(tài) QA 上有實測)
我們先來看以下兩個效果展示:

圖片生成

圖片理解
在社媒上,F(xiàn)UDOKI 獲得了Meta Research Scientist/ Discrete Flow Matching 系列作者推薦:

統(tǒng)一的多模態(tài)能力
FUDOKI 對文本模態(tài)和圖像模態(tài)均采用通過統(tǒng)一的離散流匹配框架,實現(xiàn)了理解與生成任務(wù)的統(tǒng)一建模。
- 圖像生成:文本到圖像生成任務(wù)上在 GenEval 基準(zhǔn)上達到 0.76,超過現(xiàn)有同尺寸 AR 模型的性能,展現(xiàn)出色的生成質(zhì)量和語義準(zhǔn)確性

文生圖樣例

GenEval 基準(zhǔn)評測結(jié)果

離散流生成過程
- 視覺理解:在多模理解任務(wù)上接近同參數(shù)量 AR 模型的性能水平,并允許模型在推理過程不斷修復(fù)回答。

視覺理解樣例

視覺理解基準(zhǔn)評測

視覺理解案例的過程對比,F(xiàn)UDOKI 允許對已生成的回答進行修正
架構(gòu)特色
FUDOKI 的核心創(chuàng)新在于將多模態(tài)建模統(tǒng)一到離散流匹配框架中。具體而言,F(xiàn)UDOKI 采用度量誘導(dǎo)的概率路徑(metric-induced probability paths)和動力學(xué)最優(yōu)速度(kinetic optimal velocities),完成從源分布到目標(biāo)分布的離散流匹配。
基于度量誘導(dǎo)的概率路徑
FUDOKI 的離散流采用基于度量誘導(dǎo)的概率路徑,定義了一種語義上更有意義的轉(zhuǎn)換過程。在前向過程中(t 從 1 減少到 0),F(xiàn)UDOKI 會對每個 token  的概率分布(即 0/1 分布)進行逐步擾動,直到趨近于均勻分布。值得注意的是,在擾動過程中,F(xiàn)UDOKI 的離散流會綜合考慮字典里每個 token 與真實數(shù)據(jù) token
的概率分布(即 0/1 分布)進行逐步擾動,直到趨近于均勻分布。值得注意的是,在擾動過程中,F(xiàn)UDOKI 的離散流會綜合考慮字典里每個 token 與真實數(shù)據(jù) token  的語義距離
的語義距離 ,并使用如下公式計算概率路徑,使得所有與
,并使用如下公式計算概率路徑,使得所有與 語義相似的 token 仍然具有較高的概率。
語義相似的 token 仍然具有較高的概率。

動力學(xué)最優(yōu)速度
FUDOKI 的反向過程(t 從 0 增加到 1)通過并行去噪機制,將 t=0 的均勻分布逐步映射回 t=1 的目標(biāo)分布(即 0/1 分布)。具體而言,在時刻 t,F(xiàn)UDOKI 會根據(jù)動力學(xué)最優(yōu)速度 u 對第 t+h 時刻的 token 進行重采樣,計算方式如下:

這一機制具有兩個關(guān)鍵特性:首先,隨著 t 從 0 增加到 1,動力學(xué)最優(yōu)速度 u 會提升與真實數(shù)據(jù) token  語義相似的候選 token 的概率,使模型能夠在每個時間步采樣到語義相近的替代 token,從而有效擴展了采樣空間的多樣性。此外,該采樣策略還支持在反向過程中對已生成的 token 進行動態(tài)調(diào)整與修正,為生成過程提供了更大的靈活性。
語義相似的候選 token 的概率,使模型能夠在每個時間步采樣到語義相近的替代 token,從而有效擴展了采樣空間的多樣性。此外,該采樣策略還支持在反向過程中對已生成的 token 進行動態(tài)調(diào)整與修正,為生成過程提供了更大的靈活性。
模型結(jié)構(gòu)與訓(xùn)練損失
為降低大規(guī)模離散流匹配模型的訓(xùn)練成本,F(xiàn)UDOKI 通過利用預(yù)訓(xùn)練的自回歸(AR)模型進行初始化,最大化復(fù)用現(xiàn)有模型的知識,從而實現(xiàn)從 AR 范式到流匹配范式的平滑過渡。其訓(xùn)練損失函數(shù)與離散擴散模型類似,目標(biāo)是讓模型 預(yù)測出加噪樣本所對應(yīng)的真實數(shù)據(jù)。具體而言,訓(xùn)練過程中采用交叉熵?fù)p失函數(shù),以優(yōu)化模型在生成任務(wù)中的性能。
預(yù)測出加噪樣本所對應(yīng)的真實數(shù)據(jù)。具體而言,訓(xùn)練過程中采用交叉熵?fù)p失函數(shù),以優(yōu)化模型在生成任務(wù)中的性能。

結(jié)語
FUDOKI 的提出不僅挑戰(zhàn)了現(xiàn)有自回歸和掩碼擴散范式,也為多模態(tài)生成與理解的統(tǒng)一架構(gòu)帶來了新的思路。通過離散流匹配的方法,它為通用人工智能的發(fā)展提供了更加靈活和高效的技術(shù)基礎(chǔ)。我們期待未來會有更多的探索和進展。