













不要自回歸!擴散模型作者創業,首個商業級擴散LLM來了,編程秒出結果
當前的 AI 領域,可以說 Transformer 與擴散模型是最熱門的模型架構。也因此,有不少研究團隊都在嘗試將這兩種架構融合到一起,以兩者之長探索新一代的模型范式,比如我們之前報道過的 LLaDA。不過,之前這些成果都還只是研究探索,并未真正實現大規模應用。
今天凌晨,首個商業級擴散大型語言模型(dLLM)來了!該模型名為 Mercury,其表現非常卓越,在英偉達 H100 上能以每秒超過 1000 token 的速度運行,同時性能也并不比現有的經過速度優化的 LLM 差。

下面是官方展示的一個對比示例。讓一個自回歸 LLM 與 Mercury 編寫一個 LLM 推理函數。自回歸模型迭代了 75 次,而這個 dLLM 卻僅迭代了 14 次就完成了任務,速度要快得多。

打造 Mercury 系列模型的是一家創業公司,名為 Inception Labs,該公司的創始人之一 Stefano Ermon 實際上也正是擴散模型(diffusion model)的發明者之一,同時他也是 FlashAttention 原始論文的作者之一。Aditya Grover 和 Volodymyr Kuleshov 皆博士畢業于斯坦福大學,后分別在加利福尼亞大學洛杉磯分校和康乃爾大學任計算機科學教授。

Inception Labs 今天發布的 Mercury 具有巨大的性能和效率優勢,據 Kuleshov 推文介紹,基于來自 MidJourney 和 Sora 等圖像和視頻生成系統的靈感,該公司為 Mercury 引入了一種新的語言生成方法。相比于現有的 LLM,這種方法的運行效率顯著更高(速度更快、成本更低),并且還可將推理成本降低 10 倍。
性能表現上,Mercury 系列中的編程模型 Mercury Coder 可比肩 Claude Haiku 和 GPT4o-mini 等針對速度指標優化過的前沿模型。但是,它的硬件效率要高得多,因為它使用了利用 GPU 的并行生成機制。這使得模型能以遠遠更快的速度和更低的成本運行(可以在同樣的硬件上為更多用戶提供服務)。

目前 Mercury Coder 已上線,可公開試用。該公司表示還可為企業用戶提供代碼和通用模型的 API 和內部部署服務。
試用地址:https://chat.inceptionlabs.ai
如此高效且達到商業級的新型語言模型自然吸引了不少關注,著名 AI 研究科學家 Andrej Karpathy 發帖闡述了這項成果的意義。他表示,不同傳統的自回歸 LLM(即從左到右預測 token),擴散模型是一次性向所有方向進行預測 —— 從噪聲開始,逐漸去噪成 token 流。雖然之前的研究似乎表明文本好像更適合自回歸范式,而擴散模型更適合圖像與視頻,但業界對此其實并沒有定論。而這項研究更進一步表明,擴散模型在文本模態上也具有極大的潛力。
 下面我們就來看看 Mercury 究竟是怎么打造的及其實際表現。
下面我們就來看看 Mercury 究竟是怎么打造的及其實際表現。
讓擴散模型驅動下一代 LLM
當前的 LLM 都是自回歸模型,也就是說它們是從左到右生成文本,一次生成一個 token。
這種生成過程本質上是順序式的 —— 在生成某個 token 之前,必須先生成它之前的所有文本。而每個 token 的生成都需要評估一個包含數十億參數的神經網絡。前沿的 LLM 公司正在研究通過測試時計算來提高模型的推理和糾錯能力,但生成長推理軌跡的代價是推理成本的急劇上升和更長的延遲。為了使高質量的 AI 解決方案真正普及,需要進行范式轉變。
而擴散模型提供了這樣的范式轉變。
擴散模型的生成過程是「從粗到細」,即輸出是從純噪聲開始的,然后通過一系列「去噪」步驟逐步細化。
由于擴散模型不受到僅考慮之前輸出的限制,因此它們在推理和結構化響應方面表現更好。而且,由于擴散模型可以不斷細化其輸出,它們能夠糾正錯誤和幻覺。因此,擴散模型是當前所有主要的視頻、圖像和音頻領域的生成式 AI 的基礎,包括 Sora、Midjourney 和 Riffusion。然而,擴散模型在文本和代碼等離散數據上的應用從未成功過。而現在,情況變了。
Mercury Coder:每秒 1000+ Tokens
Mercury Coder 是 Inception Labs 向公眾開放的第一個 dLLM。
它將 AI 能力推向了另一個高度:比當前一代的語言模型快 5 到 10 倍,并能夠以低成本提供高質量的響應。
dLLM 作為典型自回歸 LLM 的直接替代品,其支持很多用例,包括 RAG、工具使用和智能體工作流。
其工作流程是這樣的,當接收到查詢提示時,它并不是逐 token 生成答案,而是以「從粗到細」的方式生成。對答案的改進是由一個神經網絡提供 —— 在文章示例中是一個 Transformer 模型 —— 在大量數據上進行了訓練,并通過并行修改多個 token 來提高答案的質量。
Mercury Coder 性能非常出色,在標準編碼基準測試中,Mercury Coder 超越了像 GPT-4o Mini 和 Claude 3.5 Haiku 這樣的自回歸模型,而這些模型專為速度進行過優化,同時速度還提高了多達 10 倍。

dLLM 的突出特點在于其速度。
即使是經過速度優化的自回歸模型最多也只能達到每秒 200 個 token,但是該研究可以在商用的 NVIDIA H100 上以每秒超過 1000 個 token 的速度提供服務。與一些前沿模型相比,這些模型的運行速度可能還不到每秒 50 個 token,dLLM 提供的加速超過了 20 倍。
dLLM 這樣的高吞吐量以前只能使用專門的硬件來實現,比如 Groq、Cerebras 和 SambaNova。現在算法改進也跟上了硬件進步,并且在更快的芯片上,加速效果會更加顯著。
下圖為 Mercury Coder 在 NVIDIA H100 上實現了每秒超過 1000 個 token 的處理速度。這意味著即使在沒有使用專用芯片的情況下,dLLM 也能達到極快的生成速度!

速度比較;每秒輸出 token

Mercury Coder 能以極高的速度達到相當高的編程指數,注意這里僅有 Small 和 Mini 版的數據
除了速度,Mercury 的代碼補全功能也非常出色。在 Copilot Arena 上進行基準測試時,Mercury Coder Mini 并列第二,超過了 GPT-4o Mini 和 Gemini-1.5-Flash 等模型性能,甚至超過了 GPT-4o 等更大的模型。同時,它也是速度最快的模型,比 GPT-4o Mini 快約 4 倍。

機器之心也做了一些簡單的嘗試,速度果真是超級快!
提示詞:Write a solar system simulator that rotates(寫一個旋轉的太陽系模擬器)
可以看到,Mercury Coder 幾乎眨眼之間就完成了所有代碼的編寫,并還附贈了相關說明。
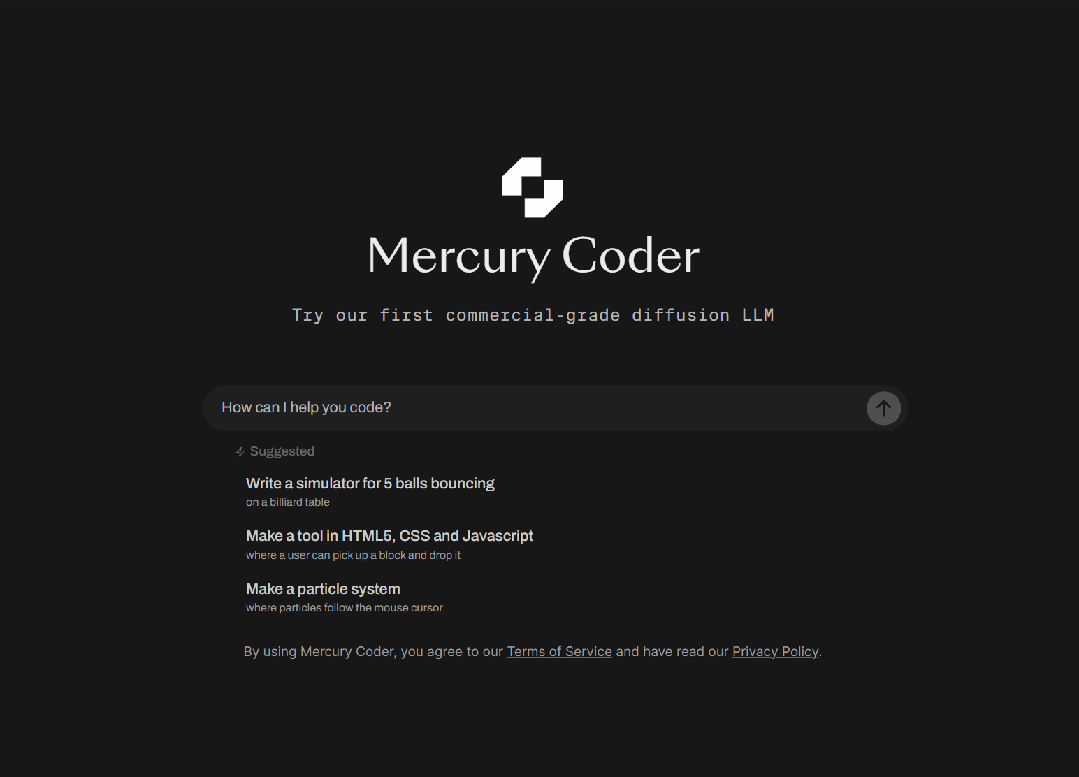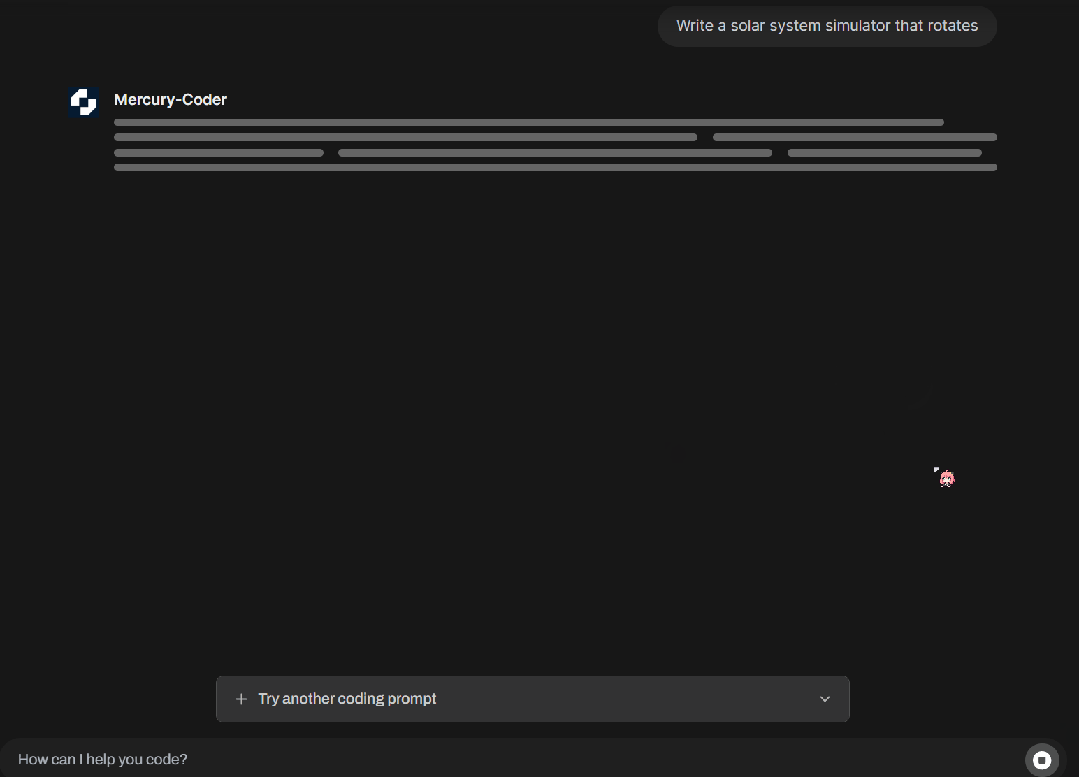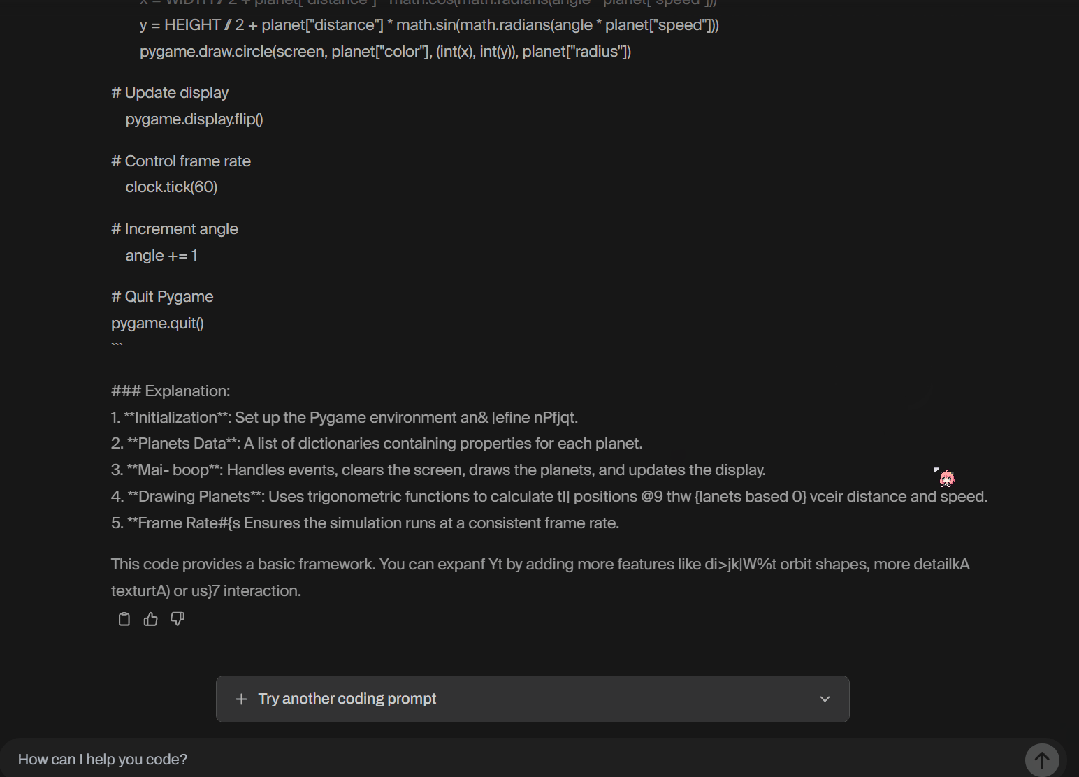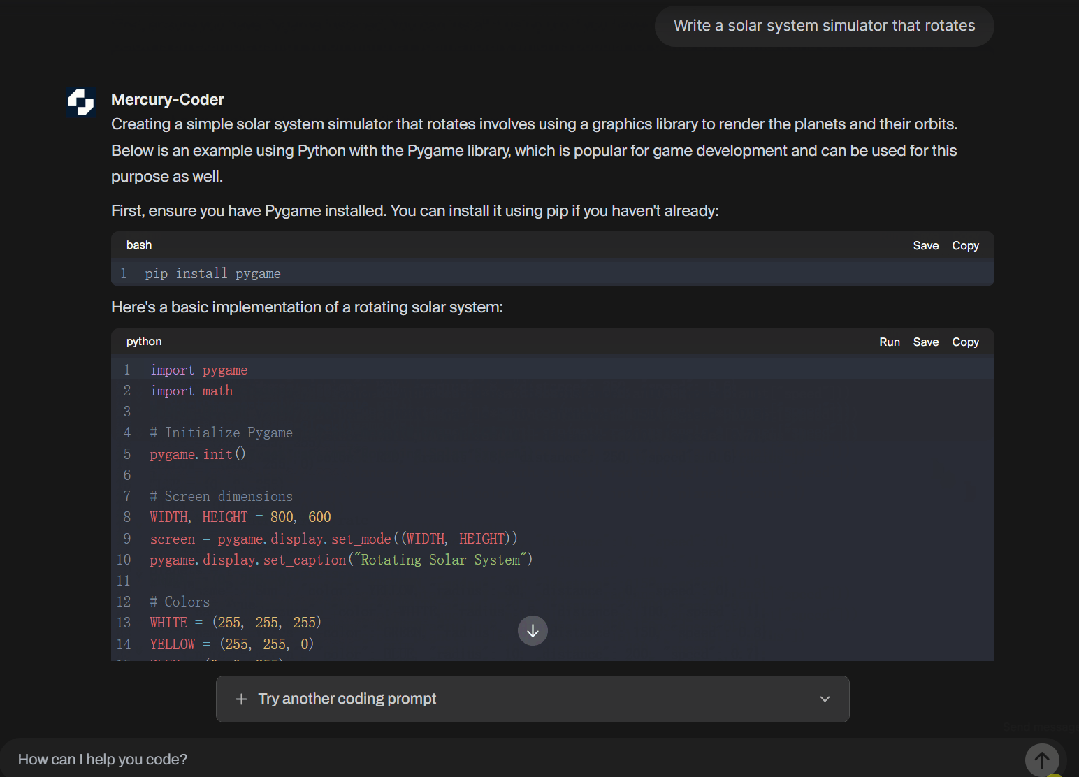
未編輯的實測速度
運行看看效果,有一個 RED 參數未定義的報錯,簡單修正后即可運行。可以說是超出預料了。
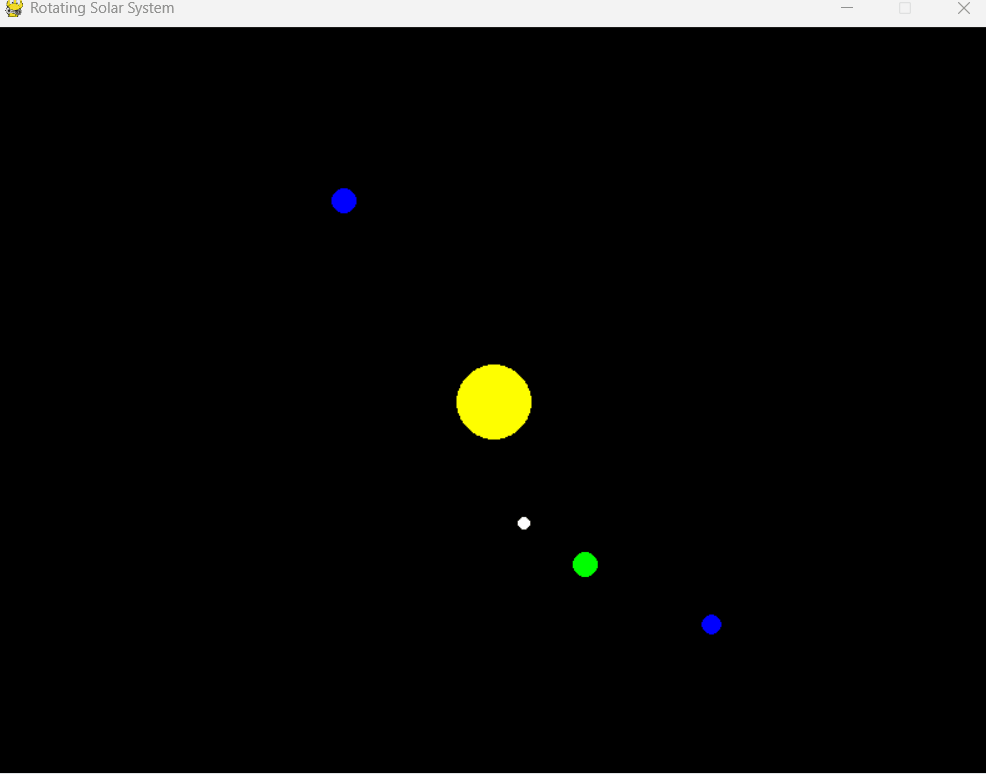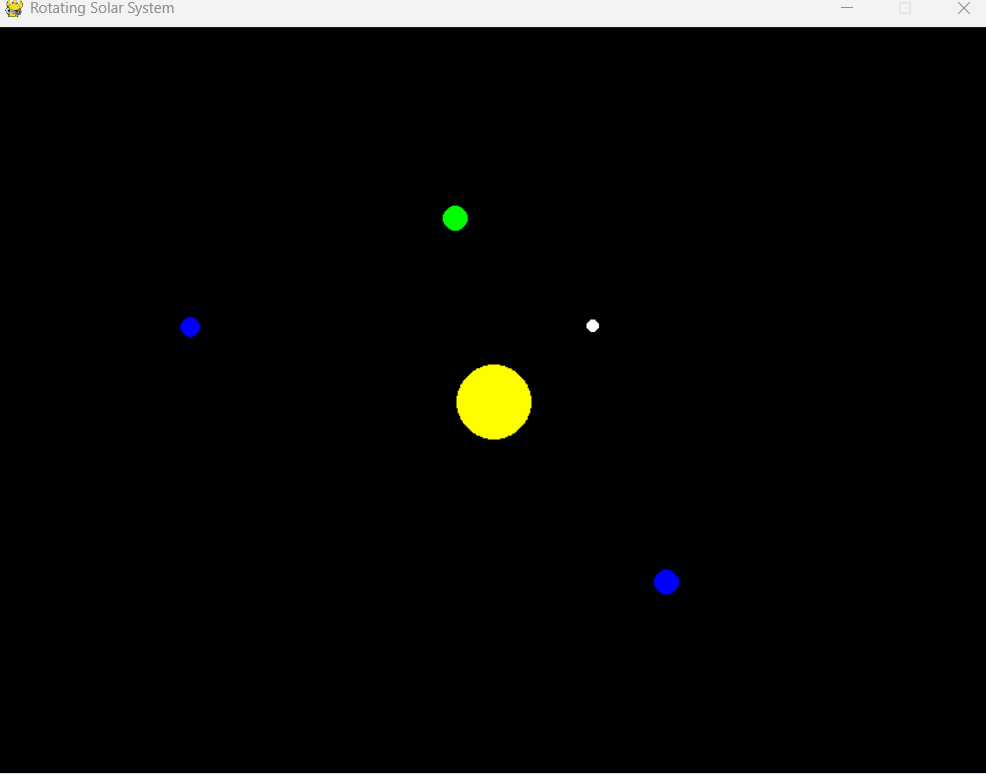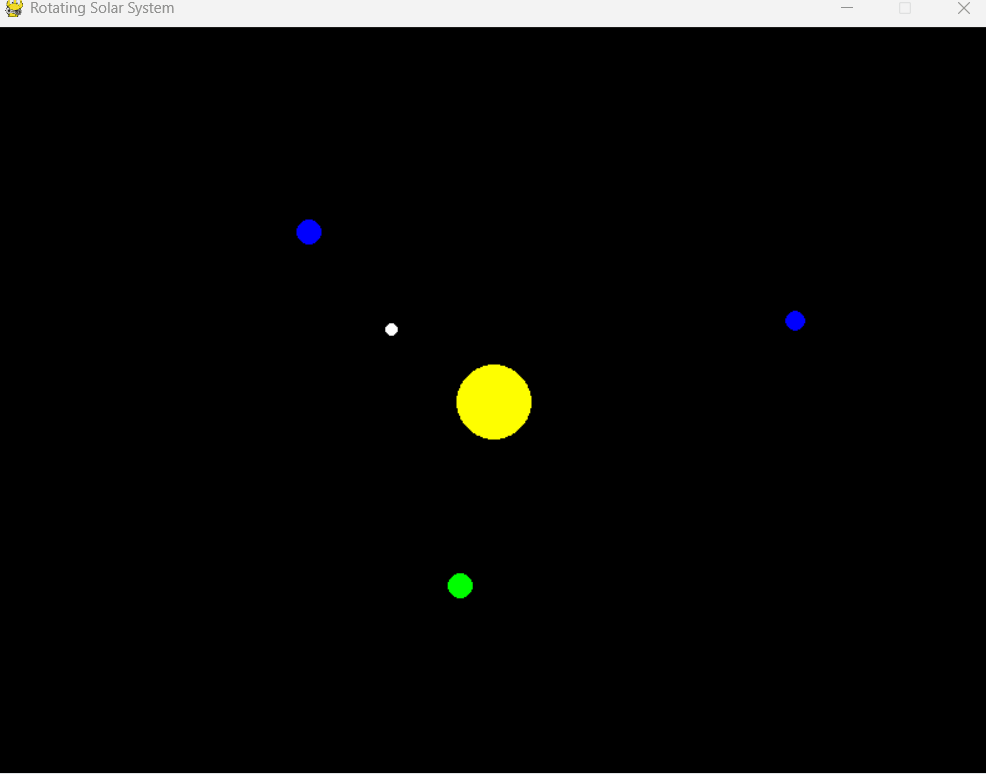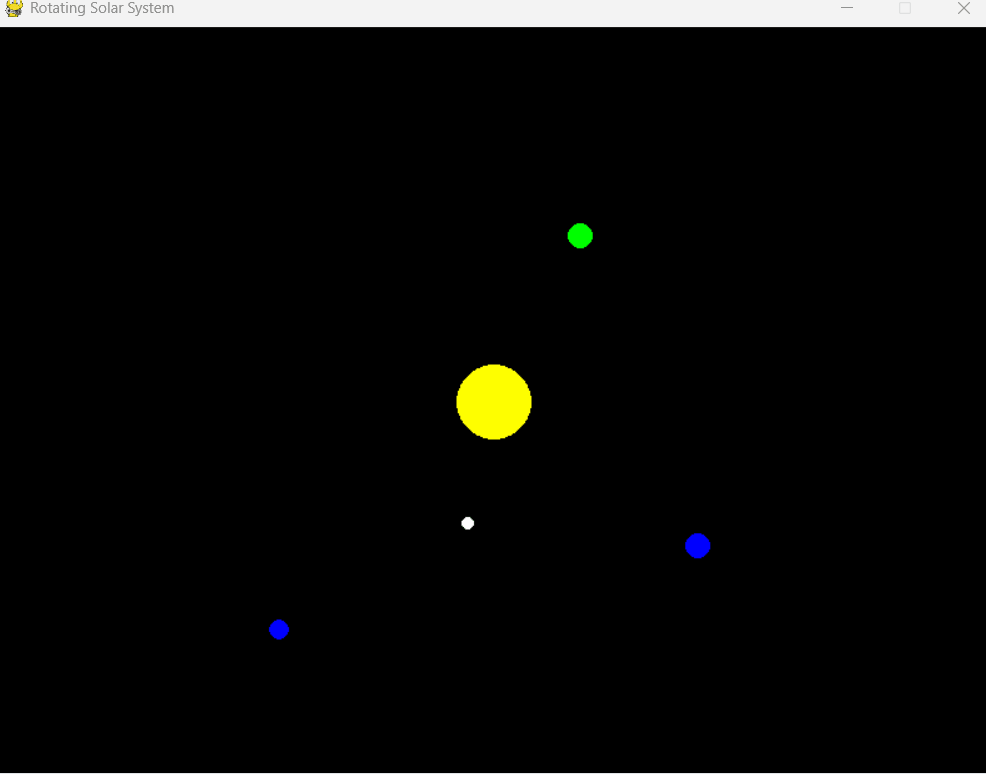
雖然目前 Inception Labs 只發布了 Mercury Coder 模型,但著實讓人開始期待起來了呢。






























