













Airbnb如何打造大數據引擎
與大多數互聯網公司一樣,旅行房屋短期租賃網站Airbnb也希望通過分析海量數據提升用戶體驗和業務營收。Gigaom最近撰文介紹了Airbnb如何在亞馬遜云的基礎上打造大數據基礎架構,并將數據分析作為產品和業務決策的基礎,編譯整理如下:
“我們希望所有的決策都基于數據,我們希望成為數據驅動的公司”。這是今天硅谷企業家的夢想,Airbnb副總裁Mike Curtis也不例外。Curtis加盟Airbnb不到半年,此前兩年他的履歷是Facebook的工程總監。
“在推動數據科學在旅游業的應用方面,沒有人比我們做得更多。長期看,這需要很多金剛鉆。”Curtis說道。
個性化搜索的挑戰
Airbnb的一大數據難題是找到即將推出的個性化搜索的最佳方式,我們希望客戶能找到符合他們個性化要求的最佳選擇。
但是為不同的用戶個體提供個性化的搜索排名會帶來非常棘手的算法難題。搜索結果依據社區或地理位置排名還相對簡單,但是要加入用戶決策的其他因素,例如社會關系、租賃歷史、評價等數據點后,整個事情就變得復雜起來。(如果加入Airbnb的城市、客戶和租戶的人口統計以及其他租賃元數據的話,問題就更加復雜)
Twitter的個性化搜索引擎就整合了大量判斷相關度的因素,其背后涉及的數據科學問題就非常復雜。
此外,Airbnb還需要通過數據分析幫助房主制訂最佳的房屋租賃價格。
Airbnb也希望能夠走Facebook的路子,讓Hadoop成為所有公司員工都能輕松使用的強大工具。
Mesos是關鍵
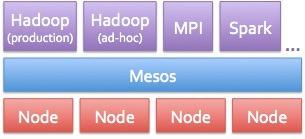
Mesos的架構圖
Airbnb實現大數據夢想的戰略性工具是一個名為Mesos的開源集群管理項目。該技術來自加州伯克利的AMPLab實驗室(該實驗室開發的技術例如Spark內存并行處理框架可以讓Hadoop運行得更快,比MapReduce快100倍)。可以讓用戶在單一資源上運行多種計算框架,當然,也可以是多個獨立的Hadoop集群。Twitter的使用讓Mesos在互聯網圈聲名鵲起,上周Mesos已經成為Apache的頂級項目。
對于Airbnb來說,Hadoop之外,Mesos也是Airbnb工程師們最大化利用亞馬遜AWS云資源的的關鍵工具。Airbnb是Hadoop的重度用戶,但Curtis希望能測試流處理的Storm,還希望能用Spark加速Hive查詢。
事實上,Spark對搜索排名、定價、錯誤排查等算法模型來說特別有用,這些模型大多涉及機器學習,而Spark能大大提升Hadoop的性能,能更快更多地運行這些模型。
Airbnb開發的一個分布式任務計劃器——Chronos,也運行在Mesos上。
除了資源管理和效率提升外,Curtis表示Mesos還能有助于推動Airbnb搭建高機動性小團隊的工程戰略。Airbnb資源分配的自動化水平越高,工程師們就能騰出更多時間做其他事情。
云計算的可以,MapReduce的不要
雖然Airbnb運行在AWS云上,但通過Mesos,Airbnb可以不使用亞馬遜的Elastic MapReduce Hadoop服務。據Curtis透露,Airbnb這么做的原因有很多,其中最重要的一點是可以通過Mesos統一管理所有其他Airbnb需要運行的框架,而且能對Hadoop環境控制的粒度更好。Elastic MapReduce也可以看作是亞馬遜自己的Hadoop發行版本,這意味著用戶需要依賴AWS提供補丁升級,而且僅僅是為了Hadoop任務而準備的。
Airbnb的另外一位工程師Brenden Matthews上周在Twitter總部的一次演講(演示文稿)介紹了Airbnb如何從Elastic MapReduce遷移到Mesos上,以及在云端運行Hadoop經常會遇到的一些技術難題。
Curtis認為,AWS總體來說還是穩定的,搭配Mesos使用后,Airbnb可以隨時做需要做的任何事情。Airbnb的ad hoc分析查詢也不會與長時間運行的批量工作流沖突。
“在集群上跑任務的速度實際上是一個資源分配問題,取決于你需要投入的資源”Curtis說道。
總之,云計算讓Airbnb這樣的創業公司在前期只有少量投入的情況下就能購買和管理服務器,“想想如今大部分服務器都被抽象化了,這確實是一件美妙而驚人的事情。”Curtis感嘆道。
原文鏈接:http://www.ctocio.com/ccnews/13073.html

















