深度揭秘Airbnb的跨洋大數據挑戰及架構實戰
原創【51CTO.com原創稿件】大數據時代,每個公司都會遇到一些共性的挑戰,比如大數據的采集、整合、存儲、計算。Airbnb 在大數據平臺架構構建的過程中,也收獲了很多寶貴的經驗。
2017 年 12 月 1 日-2 日,由 51CTO 主辦的 WOTD 全球軟件開發技術峰會在深圳中州萬豪酒店隆重舉行。Airbnb Sr Software Engineer 王宇在大數據系統架構設計專場與來賓分享了“Airbnb 的跨洋大數據架構”主題演講。
他為大家揭秘了 Airbnb 是如何解決大數據的存儲應用以及跨洋的數據平臺的搭建和支持,詳析 Airbnb 大數據挑戰和解決方案,分享如何解決大數據高效存儲和計算的過程,并了解如何進行大數據平臺的跨洋支持。
本次分享分為三大部分:
- Airbnb 的大數據需求,它是整個數據架構的基礎。
- Airbnb 的大數據架構,包括 Superset 等部件。
- Airbnb 大數據架構對中國的支持,雖然公司位于美國加州,但是對于中國市場業務也提供著數據方面的支持。
Airbnb 的大數據需求
先介紹一下 Airbnb 對大數據的需求和數據的驅動。

Airbnb 于 2008 年 8 月成立,人們可以通過網站、手機或平板電腦,發布、發掘和預訂各地的獨特房源。上圖所列數據雖不是最新,但是可見數據的體量是非常龐大的。
Airbnb 服務對象的多樣性決定了:我們必須通過定制化的數據產品,為用戶提供最佳的旅行體驗。同時我們的平臺也會基于各種數據做出正確的決策。
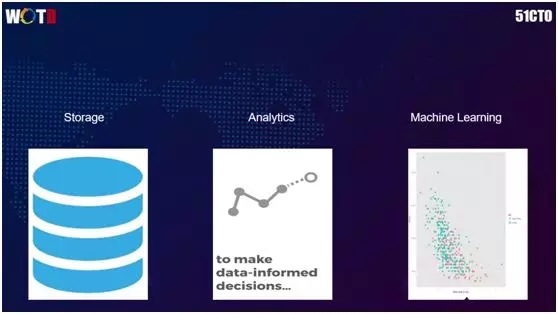
我們對于數據的使用流程分為:
- 最底層是數據的存儲(Storage),一般具有高配置的計算能力和容量。
- 中間層是基于數據的挖掘與分析,我們根據不同的場景,通過 Data Mining和 Analytics,來實現用戶管理、定價和風險控制,從而為運營(Operating)團隊提供可參考的模型矩陣(Matrix)。
- 最上層是我們根據不同的產品結構所開展的基于數據的機器學習、人工智能、決策預判等。

我們在企業中比較推崇 Data Informed Culture,我們通過檢查各種試驗性的假設、和深度挖掘各種商業數據,從而構建出機器學習的模型。
同時,我們通過持續監控與跟蹤,將數據作為決策的重要依據,保證平臺上的任何推薦都能夠嚴格基于數據的指標。
Airbnb 的大數據架構
下面我們從 Airbnb 大數據架構的構建理念、整體的架構特點和對部分系統的 Deep Dive 來深入探討。
Airbnb 大數據架構理念
雖然經歷了幾代數據架構的升級,但是我們的理念一直保持如下五個特點:
- 開源軟件的使用,在開源社區里有著非常多的優秀產品可為我們提供幫助。
- 使用標準的組件和方法,可以提高通用性和重用性。
- 關注可擴展性,在設計的最初就要考慮到系統的 scale up(擴容),從而使得整體架構既簡單易懂,有靈活伸縮。
- 解決數據用戶的實際問題,真正滿足數據使用者的需求,給他們提供所需的環境。
- 留有余量,為了提高產品效率,公司產品線的增加往往相對于現有的數據架構的壓力并非是線性上升的,因此我們要在設計之初就留有足夠的余量。
Airbnb 大數據架構實戰

上圖所列的數據雖不是最新,但與當前的實際體量也差不多。我們日志消息的容量大概有 10B,數據倉庫的容量大概是 50PB 以上,機器的數量大約有幾千臺,而數據的年增長率則是每年 5 倍的增長速度。

上圖展示的是我們數據架構的一個概覽。從左向右,首先是兩種輸入:
- Event Logs,一般是由用戶行為所觸發,它連接的是改進版 Kafka,即:底層是 Kafka 的 Jenkins,而我們在上層做了許多優化。
- MySQL Dumps,來自傳統關系型數據庫的在線數據流被 Sqoop 傳遞到 Hadoop 的 HDFS 中。
而中間則由 Gold Hive Cluster 和 Silver Hive Cluster 兩個部分組成,所有的 Raw Data 和 Log 在被處理之前,全都被送入 Gold Cluster 進行各種應用、分類和特征的提取。
在產生相應的 table 之后,再被放入 Server 中。那么如果所有的變化都是批量產生的話,我們就能夠很容易地實現同步。
但是如果出現 Interfering Change(干擾變更)時,為了保持一致性,我們自己寫了一個 Re-air 的工具,去同步兩個單獨的 Data Clusters。
最上面是 Airflow Scheduling,Airflow 是我們公司內部自行開發的一個系統,我們用它去做 schedule job。
通過良好的 UI,它能夠實現數據流的分配管理,控制任務間依賴關系和時間調度。同時它還能夠調度上圖右邊的 Spark Cluster。
最下方是 Presto Cluster,它是 Facebook 研發出的一套開源的分布式 SQL 查詢引擎,適用于交互式分析查詢。
其右邊對應的分別是:負責界面顯示的 Airpal、簡易的數據搜索分析工具Caravel、和 Tableau 公司的可視化數據分析產品。
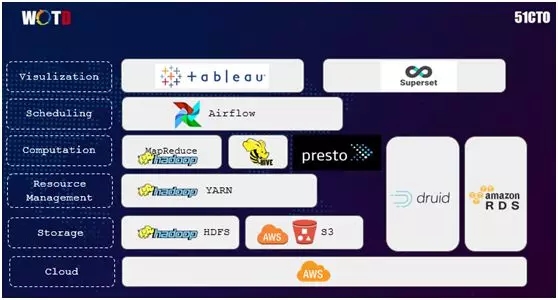
如上圖所示,我們的 Data Cluster 云是架構在亞馬遜的 AWS 上,其中全球部分被放置在美國東部,而中國部分則被放置在新加坡:
- 在存儲方面,我們使用的是 Hadoop 的 HDFS 和 AWS 的 S3。
- 在資源管理上,我們用到了 YARN。同時我們通過 Druid 和亞馬遜的 RDS,實現了對數據庫連接的監控,以及操作與擴展。
- 在計算上,我們采用的是 MapReduce、HIVE 和 Presto。
- 在調度上,我們使用的是自己開發的 Airflow。
- 在可視化上,我們用到了現成的 Tableau 和 Superset。

我們來具體看看 Streaming Ingestion(數據流攝取)的流程。首先,我們主要獲取的是兩種輸入:
- Event Logs
- DB Mutations
為了記錄數據庫的變化(mutations),我們自行開發了一個叫做 SpinalTap 的系統,用來捕獲每個表(table)的變化。
該系統是由通用分布式集群管理與調度框架 Helix 來進行管理的。Helix 不但開源,而且我個人覺得比 Zookeeper 更好用。
然后數據順次進入 Kafka 的 Jenkins,Spark Streaming,之后到達 Hbase 的數據倉庫。

上圖是 Re-air 的抽象邏輯圖,其中最重要的就是實現在 Gold、Cluster 和 Silver Cluster 之間 HDFS 的實時同步。另外在它對所有數據同步的過程中,也能具有去重的效果。

說到兩個獨立的集群,現在許多公司都在嘗試這樣的架構,我們也是力推 Gold+Silver 的集群模式。
它的優勢在于:
- 用戶作業的錯誤能夠被完全隔離。
- 容量規劃更為方便。我們可以對兩個集群的容量及各種參數進行預估,在管理角度上更為清晰。
- 保證 SLA。您一旦形成了獨立集群的概念和能力,就能快速地升級或部署新的函數與應用。
- 具有更為可靠性的災難恢復能力。
當然,該架構也會存在著如下的缺點:
- 用戶容易混淆,據官方數據聲稱,用戶容易混淆兩個集群。
- 數據同步,這是兩個集群的最大挑戰,不過我們用 Re-air 解決了此問題。
- 運營成本可能會有所增加。

前面我們提到過兩個數據倉庫之間的同步策略,具體說來一般分為兩種方式:
- 批量同步。優點是:掃描 HDFS、Metastore,拷貝相關的數據,簡單粗暴、也不需要維護狀態;缺點是:當您的存儲容量變得很大時,延時會比較高。
- 增量同步。優點是:更為智能化,它可以記錄數據源的變化,通過拷貝到目標集群,執行相關操作。其延時非常低,我們在兩邊的同步延遲可以達到秒級;缺點是:復雜,需要維護和處理好許多狀態。

如今業界許多公司都在使用 Airflow,來實現統一的調度管理系統(Schedule System)。我們公司內部也開發出了一套自己的工作流系統。
它有著獨特的 UI,能提供許多內置的 Operators。我們可以通過自定義各種 Job(作業),來支持 Hive、Presto、MySQL、S3 等系統。
當然,相類似的系統也有:Apache 的 Oozie、Azkaban、AWS 的 SWF 等,但是 Airflow 更好用一些。

簡單來說,如果您要做一套 Flow,那么首先需要定義不同流程的特征(feature)。
通過收集,我們便可羅列出自己環境中的 DAG,其中包括各種成功或失敗的任務(tasks)。

通過如圖所示的樹形視圖(Tree View),您可以迅速地通過時間狀態來找到被阻止的地方。

您還能夠獲知關鍵組件間的邏輯關系,如上圖所示。

而通過任務耗時曲線圖,您可以了解到在過去的屢次運行中,不同任務的具體耗時情況,出現過的異常值,以及最耗時的環節。

我們再來看看 Superset,它是由 Apache 提供的一種開源的大數據可視化工具,我們對其也進行了自行開發。

Superset 的功能比較強大,您可以自行建立不同的 Dashboard(儀表盤),它支持各種應用數據的查詢,并能以曲線、餅圖或表的形式展示出來,還能定制化顯示頁面。

通過簡單的頁面點擊,數據能夠立即呈現出來。同時它還能提供各式各樣的 Matrix(模型矩陣),以供進一步做細粒度的分析。
Airbnb 大數據架構對中國的支持
最后我介紹一下大數據架構對中國的支持。對于 Airbnb 這樣的海外公司在進入中國市場的過程中,鑒于中國對于數據安全性的合規要求等方面的挑戰,我們找到了一些相應的解決方案。
大數據架構在中國的挑戰
由于 Airbnb 是一個旅游的平臺,所以我們會存儲一些和個人相關的信息。例如:我們會要求用戶上傳身份證的相關信息。
如果是房東的話,我們還要求他注冊家里的各種數據。因此,我們不能將數據簡單放到谷歌上。
同時,中國的研發團隊不僅需要最大程度地使用中國本地的數據,還要用到位于美國數據中心的全球數據。
因此,保證數據的安全性和使用時的高效性,是我們所面臨的兩大挑戰。
解決方案

我們在亞洲的新加坡有個 Gold 和 Silver Cluster 區域中心,而在中國北京我們用的是 Jade,其結構一模一樣,只是在業務上有細微的差別。
如前面所提到的,我們在存儲上用到了 HDFS 和 S3。而實際上,我們在全球絕大多數地區都使用的是 HDFS,只是在 Jade Cluster 里我們用的是 S3。
數據支持
首先來看看 Universal Export(統一導出)對數據的支持。我們無時無刻地在向中國這邊輸送著全球的信息數據。

上圖是數據輸出的簡要邏輯圖。最左邊是全球的數據表輸入,由于安全性的原因,我們通過 Filter 進行過濾,并且在生產環境中建立了一個基于 HDFS 的 Staging Table。
而其右邊則是另一個基于 S3 的 Staging Table,因此這些數據在跨區域到達亞洲的時候,我們這邊會有相應的 Job(作業)去進行評估和過濾。
另外,我們通過兩套數據的方式,大幅提高了對于數據的訪問使用速度,以及系統之間的復制效率。
服務監控
下面簡單介紹一下我們端對端的服務級別監控,如下圖:
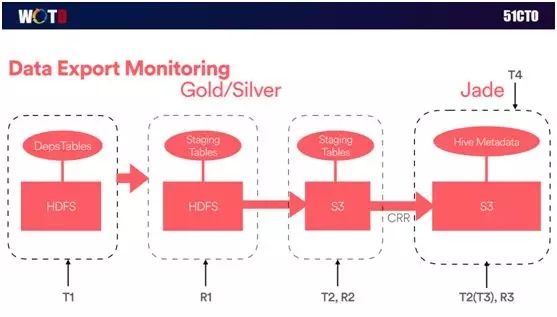
由于系統對于實時性要求比較高,我們需要通過良好的監控,以獲知在什么時候、在何處出現了什么問題。
因此我們在整個過程中都“打上”了各種時間標記,從而能夠無時無刻地監控到不同交易之間的時間差,同時也包括每一步之間數據的差異性。

如上圖所示,我們實現了按小時輸出日志事件、按天輸出近 300 張表、10TB 的數據量,這些都歸功于我們在全球和中國范圍內的大數據整體架構。
王宇,于華中科技大學和石溪大學(Stony Book University)獲得本科與碩士學位。曾就職 Quantcast 和 Qualcomm。在 Quantcast 主要負責廣告的實時競價和精準投放;在 Qualcomm 負責搭建芯片數據的云存儲和分析系統。現加入 Airbnb 中國基礎構架組(China Infrastructure),任職高級軟件工程師,負責 Airbnb 中國產品相關的基礎構架(Data Infrastructure) 和反欺詐服務(Anti-Fraud)。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】