Linux內(nèi)存管理優(yōu)化:面向低延遲/高吞吐量數(shù)據(jù)庫(kù)GraphDB
譯文【2013年10月11日 51CTO外電頭條】本文將 LinkedIn 工程師 Apurva Mehta 在 Blog 上分享的《面向低延遲/高吞吐量數(shù)據(jù)庫(kù)(GraphDB)的 Linux 內(nèi)存管理優(yōu)化》做了簡(jiǎn)單的翻譯整理,希望對(duì)大家有所幫助。
簡(jiǎn)介
GraphDB在LinkedIn的實(shí)時(shí)分布式社交圖譜服務(wù)當(dāng)中充當(dāng)著存儲(chǔ)層的角色。我們的服務(wù)旨在處理簡(jiǎn)單查詢(例如來(lái)自LinkedIn成員的一級(jí)與二級(jí)網(wǎng)絡(luò)請(qǐng)求)與復(fù)雜查詢(例如成員之間的距離以及成員之間的關(guān)聯(lián)路徑等圖譜結(jié)果)。我們支持多種節(jié)點(diǎn)及邊界類型,而且能夠直接處理所有正處于執(zhí)行當(dāng)中的查詢。感興趣的朋友不妨點(diǎn)擊此處的博文,對(duì)應(yīng)用程序使用我們社交圖譜的方式進(jìn)行初步了解。
LinkedIn上的每一個(gè)頁(yè)面視圖都會(huì)產(chǎn)生多條指向GraphDB的查詢請(qǐng)求。這意味著GraphDB每秒鐘都要處理成千上萬(wàn)條查詢請(qǐng)求,而且99%的查詢都能在微秒級(jí)別的延遲之內(nèi)得到響應(yīng)(通常延遲為十幾微秒)。有鑒于此,即使GraphDB的響應(yīng)延遲提高到僅僅5毫秒,LinkedIn的全局訪問(wèn)效果也將受到嚴(yán)重影響。
在2013年的大部分時(shí)段,我們已經(jīng)發(fā)現(xiàn)GraphDB會(huì)在使用高峰當(dāng)中偶爾出現(xiàn)間歇性響應(yīng)延遲。我們深入調(diào)查了這些高峰時(shí)段,并努力了解Linux內(nèi)核如何管理NUMA(即非統(tǒng)一內(nèi)存訪問(wèn))系統(tǒng)上的虛擬內(nèi)存。概括來(lái)說(shuō),針對(duì)NUMA的一部分Linux優(yōu)化存在嚴(yán)重的負(fù)面作用,會(huì)因此對(duì)延遲產(chǎn)生直接性不利影響。我們認(rèn)為此次研究的成果足以幫助任何一套運(yùn)行在Linux系統(tǒng)環(huán)境下、對(duì)延遲要求較高的在線數(shù)據(jù)庫(kù)系統(tǒng)獲得性能改進(jìn)。經(jīng)過(guò)我們的優(yōu)化調(diào)整,問(wèn)題出現(xiàn)幾率(例如響應(yīng)緩慢或者查詢超時(shí)的出現(xiàn)比例)已經(jīng)下降到原先的四分之一。
在文章的***部分,我們將共同了解相關(guān)背景資料,包括:GraphDB在數(shù)據(jù)管理方面的流程大綱、性能問(wèn)題的具體表現(xiàn)以及Linux虛擬內(nèi)存管理(簡(jiǎn)稱VMM)子系統(tǒng)的運(yùn)作方式。在文章的第二部分,我們將詳細(xì)探討解決辦法、指導(dǎo)意見(jiàn)以及結(jié)論匯總,旨在通過(guò)實(shí)驗(yàn)找到問(wèn)題出現(xiàn)的根源。***,我們將歸納通過(guò)此次實(shí)例所獲得的經(jīng)驗(yàn)。
本文適合對(duì)操作系統(tǒng)運(yùn)行機(jī)制具備一定了解的朋友。
背景資料
1) GraphDB如何管理數(shù)據(jù)
GraphDB在本質(zhì)上是一種內(nèi)存內(nèi)數(shù)據(jù)庫(kù)。在讀取方面,我們將所有數(shù)據(jù)文件映射到虛擬內(nèi)存頁(yè)面當(dāng)中,并始終將其保留在內(nèi)存中的活動(dòng)集之下。我們的讀取活動(dòng)具備很強(qiáng)的隨機(jī)性,指向目標(biāo)遍布整個(gè)數(shù)據(jù)集,且99%的請(qǐng)求都要求將延遲控制在微秒級(jí)別。一臺(tái)典型的GraphDB主機(jī)能夠擁有48GB物理內(nèi)存,常用內(nèi)存量為20GB:其中15GB用于處理堆外虛擬內(nèi)存頁(yè)面映射數(shù)據(jù),5GB用于JVM堆。
而在寫(xiě)入方面,我們擁有一套日志-結(jié)構(gòu)化存儲(chǔ)系統(tǒng)。我們將全部數(shù)據(jù)劃分為以10MB為單位的純追加部分。目前,每一臺(tái)GraphDB主機(jī)大約擁有1500個(gè)活動(dòng)部分,其中只有25個(gè)能夠隨時(shí)接受寫(xiě)入操作,其它1475個(gè)則處于只讀狀態(tài)。
由于數(shù)據(jù)采用日志結(jié)構(gòu)化存儲(chǔ)方式,我們需要定期對(duì)其進(jìn)行壓縮。此外,由于我們所采取的壓縮計(jì)劃比較積極,因此每天每臺(tái)主機(jī)上約有九百個(gè)數(shù)據(jù)片段會(huì)被遺棄。換言之,每天每臺(tái)主機(jī)上約有容量達(dá)9GB的數(shù)據(jù)文件徹底消失,但這還僅僅是LinkedIn全局?jǐn)?shù)據(jù)增量中的一小部分。概括來(lái)講,每臺(tái)48GB主機(jī)在運(yùn)行五天之后頁(yè)面緩存就會(huì)被垃圾堆滿。
2) 問(wèn)題癥狀
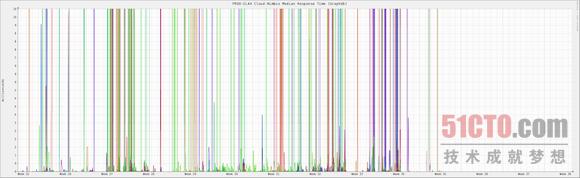
我們所遇到的性能問(wèn)題主要表現(xiàn)為在使用高峰期GraphDB出現(xiàn)響應(yīng)延遲。在高峰期出現(xiàn)的同時(shí),我們往往會(huì)面臨數(shù)量龐大的直接頁(yè)面掃描以及內(nèi)存執(zhí)行效率低下等困擾,具體情況如sar所示。在個(gè)別情況下,sar -B 下"每秒pqsand(pqscand/s)"列的輸出效率將拖慢至每秒100萬(wàn)到500萬(wàn)頁(yè)面掃描,虛擬內(nèi)存效率也會(huì)降至0%--這些癥狀往往會(huì)持續(xù)數(shù)小時(shí)。
在性能表現(xiàn)急劇下滑的過(guò)程中,系統(tǒng)的內(nèi)存壓力卻并不明顯:這是因?yàn)槲覀兛梢酝ㄟ^(guò)/proc/meminfo的記錄看到大量無(wú)效緩存頁(yè)面。此外,并不是pqscand/s中的所有高峰時(shí)段都會(huì)引發(fā)GraphDB的延遲問(wèn)題。
最讓我們感到困惑的兩個(gè)問(wèn)題是:
1、如果系統(tǒng)中不存在明顯的內(nèi)存壓力,為什么系統(tǒng)內(nèi)核會(huì)對(duì)頁(yè)面進(jìn)行掃描?
2、即使內(nèi)核開(kāi)始對(duì)頁(yè)面進(jìn)行掃描,為什么我們的響應(yīng)延遲會(huì)急劇升高?只有寫(xiě)入線程需要占用新的內(nèi)存分配,而且寫(xiě)入與讀取線程池是彼此獨(dú)立的。因此,為什么實(shí)際結(jié)果是雙方會(huì)相互產(chǎn)生影響?
正是這些問(wèn)題的答案促使我們對(duì)NUMA系統(tǒng)的Linux優(yōu)化方案做出調(diào)整。需要強(qiáng)調(diào)的是,我們最終將注意力集中在了Linux的"區(qū)回收(zone reclaim)"功能方面。如果大家對(duì)于NUMA、Linux以及區(qū)回收不太了解,別擔(dān)心,我們會(huì)在下一部分內(nèi)容中做出詳細(xì)講解。在這些資料的輔助下,大家應(yīng)該可以順利理解文章其它部分的論證過(guò)程。
3) 關(guān)于Linux、NUMA以及區(qū)回收的那些事兒
要想深入理解問(wèn)題產(chǎn)生的根源,我們首先需要明確Linux系統(tǒng)如何處理NUMA架構(gòu)。我為大家甄選了一部分優(yōu)秀的講解資源,希望能幫助各位快速掌握相關(guān)的背景知識(shí):
- Jeff Frost:《Linux中的PostgreSQL、NUMA以及區(qū)回收模式》 。 如果大家時(shí)間有限,優(yōu)先推薦各位閱讀這篇文章。
- Christoph Lameter:《非統(tǒng)一內(nèi)存訪問(wèn)概述》。大家需要著重閱讀其中關(guān)于Linux如何從NUMA區(qū)中回收內(nèi)存的部分。
- Jeremy Cole:《MySQL“交換錯(cuò)亂”問(wèn)題以及NUMA架構(gòu)的影響》。
同樣重要的是,大家需要理解Linux從頁(yè)面緩存中使用回收頁(yè)面的具體機(jī)制。
簡(jiǎn)而言之,Linux為每個(gè)NUMA區(qū)保留著一組三個(gè)頁(yè)面列表:活動(dòng)列表、非活動(dòng)列表以及空閑列表。新頁(yè)面進(jìn)行分配時(shí)會(huì)被從空閑列表轉(zhuǎn)移到活動(dòng)列表。而LRU算法則負(fù)責(zé)將頁(yè)面從活動(dòng)列表轉(zhuǎn)移到非活動(dòng)列表,而后再由非活動(dòng)列表轉(zhuǎn)移至空閑列表。下面我為大家推薦一份學(xué)習(xí)Linux頁(yè)面緩存管理知識(shí)的***資料:
- Mel Gorman: 《了解Linux虛擬內(nèi)存管理器》,第十三章:頁(yè)面回收。
我們首先認(rèn)真閱讀了上述資料,而后嘗試關(guān)閉掉生產(chǎn)主機(jī)上的區(qū)回收模式。關(guān)閉之后,我們的性能表現(xiàn)立刻獲得顯著提升。有鑒于此,我們決定在本文中詳細(xì)描述區(qū)回收的運(yùn)作機(jī)制以及對(duì)性能造成影響的原因。
本文的其它內(nèi)容深入探討了Linux區(qū)回收的相關(guān)內(nèi)容,如果大家對(duì)區(qū)回收還不太熟悉,請(qǐng)首先閱讀前文推薦的Jeff Frost的相關(guān)論述。
重現(xiàn)并理解Linux的區(qū)回收活動(dòng)
1) 設(shè)置實(shí)驗(yàn)環(huán)境
為了理解區(qū)回收的觸發(fā)原理以及區(qū)回收如何影響性能表現(xiàn),我們編寫(xiě)了一款程序,用于模擬GraphDB的讀取與寫(xiě)入活動(dòng)。我們以二十四小時(shí)為期限運(yùn)行該程序,在前面十七個(gè)小時(shí)內(nèi)、我們開(kāi)啟了區(qū)回收模式。而在***七個(gè)小時(shí)中,我們關(guān)閉了區(qū)回收模式。該程序在整個(gè)二十四小時(shí)當(dāng)中不間斷地運(yùn)行,環(huán)境中的惟一變化就是在第十七小時(shí)通過(guò)向/proc/sys/vm/zone_reclaim_mode中寫(xiě)入"0"來(lái)禁用區(qū)回收。
下面我們來(lái)解讀該程序的運(yùn)行內(nèi)容:
1、它將2500個(gè)10MB數(shù)據(jù)文件映射至頁(yè)面緩存當(dāng)中,全部讀取一遍,而后取消映射,這樣Linux頁(yè)面緩存當(dāng)中就充斥著垃圾數(shù)據(jù)。如此一來(lái),系統(tǒng)的運(yùn)行狀態(tài)類似于GraphDB主機(jī)在正常運(yùn)行數(shù)天后的情況。
2、一組讀取線程會(huì)將另一組2500個(gè)10MB文件映射至頁(yè)面緩存當(dāng)中,再隨機(jī)讀取其中的一部分內(nèi)容。這2500個(gè)文件構(gòu)成了活動(dòng)集合,用于模擬GraphDB在日常使用中的讀取狀態(tài)。
3、一組寫(xiě)入進(jìn)程不斷創(chuàng)建10MB文件。一旦某個(gè)文件創(chuàng)建完成,寫(xiě)入線程就會(huì)從活動(dòng)集合中隨機(jī)挑選一個(gè)文件、取消其映射并用剛剛創(chuàng)建的新文件加以取代。這一過(guò)程旨在模擬GraphDB在日常使用中的寫(xiě)入活動(dòng)。
4、***,如果讀取線程完成讀取所消耗的時(shí)間超過(guò)100毫秒,則自動(dòng)輸出該次訪問(wèn)流程的usr、sys以及elapsed time。這使我們得以成功追蹤到讀取性能的變化軌跡。
我們用于運(yùn)行該程序的主機(jī)擁有48GB物理內(nèi)存。我們的工作組大約占用了其中的25GB,除此之外系統(tǒng)中沒(méi)有運(yùn)行其它任何任務(wù)。通過(guò)這種方式,我們保證主機(jī)不會(huì)遇到任何形式的內(nèi)存壓力。
大家可以點(diǎn)擊此處在Github上查看我們的模擬流程。
2) 了解區(qū)回收機(jī)制如何被觸發(fā)
當(dāng)某個(gè)進(jìn)程針對(duì)頁(yè)面發(fā)出請(qǐng)求時(shí),系統(tǒng)內(nèi)核會(huì)首先檢查***NUMA區(qū)是否擁有足夠的空余內(nèi)存以及是否存在1%以上可以回收的頁(yè)面。這一百分比可以調(diào)節(jié),并由vm.min_unmapped_ratio sysctl來(lái)決定。可回收頁(yè)面屬于由文件支持的頁(yè)面(即與頁(yè)面緩存存在映射關(guān)系的文件所產(chǎn)生的頁(yè)面),但其目前并未被映射到任何進(jìn)程當(dāng)中。在/proc/meminfo中,我們可以很清楚地看到,所謂"可回收頁(yè)面(reclaimable pages)"就是那些"活動(dòng)(文件)-非活動(dòng)(文件)-被映射"(Active(file)+Inactive(file)-Mapped)的內(nèi)容。
那么系統(tǒng)內(nèi)核如何判斷多少空閑內(nèi)存才夠用呢??jī)?nèi)存會(huì)使用區(qū)"水平標(biāo)記(watermarks)",通過(guò)/proc/sys/vm/min_free_kbytes 中的值來(lái)進(jìn)行判斷。它們同時(shí)也會(huì)檢查/proc/sys/vm/lowmem_reserve_ratio 中的值。特定主機(jī)內(nèi)經(jīng)過(guò)計(jì)算的值會(huì)被保存在/proc/zoneinfo 當(dāng)中,并搭配如下所示的"低/中/高(low/min/high)"標(biāo)簽:
- Node 1, zone Normal
- pages free 17353
- min 11284
- low 14105
- high 16926
- scanned 0
- spanned 6291456
- present 6205440
內(nèi)存會(huì)在區(qū)內(nèi)空閑頁(yè)面數(shù)量低于水平標(biāo)記時(shí)執(zhí)行頁(yè)面回收。而當(dāng)空閑頁(yè)面的數(shù)量高于"低"水平標(biāo)記后,頁(yè)面回收操作就會(huì)中止。此外,這一計(jì)算過(guò)程針對(duì)的是各獨(dú)立區(qū):即使其它區(qū)仍擁有足夠的空閑內(nèi)存,只要當(dāng)前區(qū)被觸發(fā),回收機(jī)制就會(huì)付諸實(shí)施。
下面我們通過(guò)圖表來(lái)展示實(shí)驗(yàn)過(guò)程中的活動(dòng)表現(xiàn)。其中值得注意的包括以下幾點(diǎn):
- 黑色線條代表區(qū)中的頁(yè)面掃描,并以右側(cè)的y軸為基準(zhǔn)生成圖形。
- 紅色線條代表區(qū)中的空閑頁(yè)面數(shù)量。
- 綠色線條代表的是"低"水平標(biāo)記。
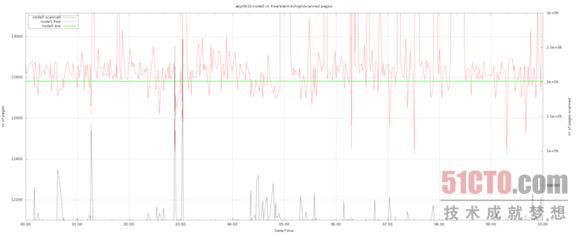
通過(guò)實(shí)驗(yàn),我們觀察到了與生產(chǎn)主機(jī)類似的表現(xiàn)。在所有情況下,頁(yè)面掃描情況都與空閑頁(yè)面情況保持吻合--二者的數(shù)值恰好相反。換句話來(lái)說(shuō),Linux會(huì)在空閑頁(yè)面數(shù)量低于"低"水平標(biāo)記時(shí)觸發(fā)區(qū)回收機(jī)制。
3) 系統(tǒng)區(qū)回收機(jī)制的特性
理解了區(qū)回收模式的觸發(fā)原理,下面我們將關(guān)注重點(diǎn)放在其它方面--區(qū)回收模式如何影響性能表現(xiàn)。為了實(shí)現(xiàn)這一目標(biāo),我們?cè)趯?shí)驗(yàn)過(guò)程中每秒一次收集來(lái)自下列源的信息:
- /proc/zoneinfo
- /proc/vmstat
- /proc/meminfo
- numactl -H
在根據(jù)這些文件中的數(shù)據(jù)繪制圖表并總結(jié)活動(dòng)模式后,我們發(fā)現(xiàn)了一些非常有趣的特性--這些特性正是解答區(qū)回收機(jī)制對(duì)讀取性能產(chǎn)生負(fù)面影響的關(guān)鍵所在。
在前期觀察中,區(qū)回收機(jī)制處于啟用狀態(tài),這時(shí)Linux執(zhí)行的大多是直接回收(即回收任務(wù)在應(yīng)用程序線程內(nèi)直接執(zhí)行,并被計(jì)作直接頁(yè)面掃描)。一旦區(qū)回收模式被關(guān)閉,直接回收活動(dòng)立刻停止,但由kswapd執(zhí)行的回收數(shù)量卻開(kāi)始增加。這就解釋了我們?yōu)楹螘?huì)在sar中觀察到每秒pqscand如此之高:

其次,即使我們的讀取與寫(xiě)入操作并未發(fā)生變化,Linux活動(dòng)與非活動(dòng)列表內(nèi)的頁(yè)面數(shù)量也在區(qū)回收模式關(guān)閉后發(fā)生了顯著變化。需要強(qiáng)調(diào)的是,在區(qū)回收機(jī)制的開(kāi)啟時(shí),Linux會(huì)在活動(dòng)列表中保留總大小約20GB的頁(yè)面信息。而在區(qū)回收機(jī)制關(guān)閉后,Linux在活動(dòng)列表內(nèi)的信息保留量增加到約25GB,這正是我們整個(gè)工作集的大小:
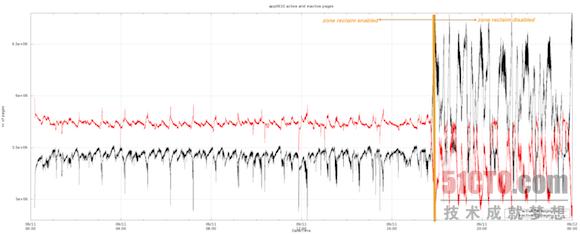
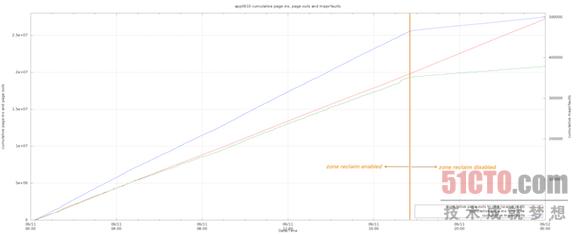
***,我們觀察到在區(qū)回收模式被關(guān)閉后,頁(yè)面內(nèi)活動(dòng)出現(xiàn)了顯著差別。值得關(guān)注的一點(diǎn)在于,雖然從頁(yè)面緩存到磁盤駐留的速率保持不變,但區(qū)回收被關(guān)閉后從磁盤駐留到頁(yè)面內(nèi)的速率顯著降低。主要故障率的變動(dòng)情況與頁(yè)面內(nèi)傳輸速率完全一致。下面的圖表證明了這一結(jié)論:
***,我們發(fā)現(xiàn)程序中的高占用內(nèi)存訪問(wèn)活動(dòng)的數(shù)量在區(qū)回收模式被關(guān)閉后大幅減少。以下圖表顯示了內(nèi)存訪問(wèn)延遲(單位為毫秒)以及響應(yīng)時(shí)間在系統(tǒng)及用戶CPU層面的具體消耗。可以看到,該程序的大部分運(yùn)行時(shí)間被消耗在了I/O等待方面,而且偶爾還會(huì)在系統(tǒng)CPU當(dāng)中遭遇阻塞。
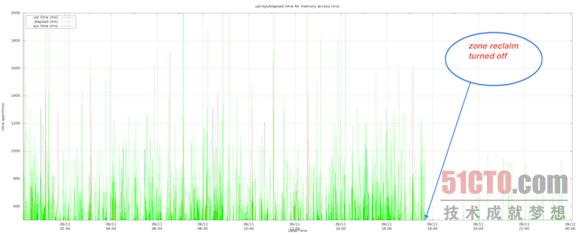
4) 區(qū)回收模式如何影響讀取性能
基于以上統(tǒng)計(jì)結(jié)果,看起來(lái)由區(qū)回收所觸發(fā)的直接回收途徑似乎在將頁(yè)面從活動(dòng)列表中移除并轉(zhuǎn)移到非活動(dòng)列表方面表現(xiàn)得太過(guò)激進(jìn)。特別是在區(qū)回收機(jī)制啟用時(shí),活動(dòng)頁(yè)面似乎會(huì)被直接清盤并被塞進(jìn)非活動(dòng)列表,而后再被移出到空閑列表當(dāng)中。有鑒于此,讀取活動(dòng)會(huì)遭遇極高的主要故障機(jī)率,性能表現(xiàn)也變得一落千丈。
導(dǎo)致問(wèn)題進(jìn)一步加劇的則是shrink_inactive_list函數(shù),作為直接回收路徑的組成部分、它似乎在區(qū)中采用了一種全局自旋鎖,從而阻止其它線程在回收過(guò)程中對(duì)區(qū)產(chǎn)生修改。正因?yàn)槿绱耍覀儾艜?huì)在高峰時(shí)段發(fā)現(xiàn)系統(tǒng)CPU在讀取線程中出現(xiàn)鎖定,這很可能是因?yàn)槎鄠€(gè)線程之間存在沖突。
NUMA內(nèi)存平衡機(jī)制同樣會(huì)觸發(fā)直接頁(yè)面掃描
我們剛剛了解了區(qū)回收模式如何觸發(fā)直接頁(yè)面掃描,也證實(shí)了這類將頁(yè)面數(shù)據(jù)擠出活動(dòng)列表的粗暴掃描正是讀取性能下滑的罪魁禍?zhǔn)住3藚^(qū)回收之外,我們還發(fā)現(xiàn)一項(xiàng)名為Transparent HugePages (簡(jiǎn)稱THP)的紅帽Linux功能在對(duì)NUMA區(qū)進(jìn)行內(nèi)存"平衡調(diào)整"時(shí)同樣會(huì)觸發(fā)直接頁(yè)面掃描。
在THP功能的推動(dòng)下,系統(tǒng)會(huì)以透明化方式為匿名(即非文件支持)內(nèi)存分配2MB"大型頁(yè)面"。這種做法能夠提高TLB中的命中率并降低系統(tǒng)中頁(yè)面列表的大小。紅帽方面表示,THP在特定工作負(fù)載中能夠帶來(lái)高達(dá)10%的性能提升。
另外,由于這項(xiàng)功能以透明化方式運(yùn)作,因此它還利用一部分代碼將大型頁(yè)面分割成多個(gè)常規(guī)頁(yè)面(在/proc/vmsat中被統(tǒng)計(jì)為thp_split),或者將多個(gè)常規(guī)頁(yè)面匯聚成巨大頁(yè)面(被統(tǒng)計(jì)為thp_collapse)。
我們已經(jīng)看到,即使區(qū)中不存在內(nèi)存壓力,thp_split仍然會(huì)導(dǎo)致很高的直接頁(yè)面掃描比率。我們還發(fā)現(xiàn)Linux系統(tǒng)會(huì)將我們的5GB Java堆分割成巨大頁(yè)面,從而將其在不同NUMA區(qū)之間進(jìn)行移動(dòng)。大家請(qǐng)看如下圖表:總大小約5GB、來(lái)自兩個(gè)NUMA區(qū)的數(shù)據(jù)被分割成巨大頁(yè)面,其中一部分被從Node 1移動(dòng)到了Node 0。這類活動(dòng)必然會(huì)帶來(lái)很高的直接頁(yè)面掃描比率。

我們無(wú)法在自己的實(shí)驗(yàn)環(huán)境下重現(xiàn)這一狀況,而且這似乎也不能算是導(dǎo)致直接頁(yè)面掃描的常見(jiàn)原因。不過(guò)我們手中有大量數(shù)據(jù)可以證明,Transparent HugePages功能與NUMA系統(tǒng)的協(xié)作效果并不理想,因此我們決定在自己的RHEL設(shè)備上運(yùn)行下列命令來(lái)禁用該功能。
- echo never > /sys/kernel/mm/transparent_hugepage/enabled
經(jīng)驗(yàn)教訓(xùn)
1) Linux的NUMA優(yōu)化對(duì)于典型數(shù)據(jù)庫(kù)負(fù)載并無(wú)意義
數(shù)據(jù)庫(kù)的主要性能提升源自在內(nèi)存中對(duì)大量數(shù)據(jù)進(jìn)行緩存處理,而NUMA優(yōu)化并不能做到這一點(diǎn)。需要強(qiáng)調(diào)的是,利用內(nèi)存緩存規(guī)避磁盤讀寫(xiě)所節(jié)約的時(shí)間要遠(yuǎn)遠(yuǎn)超過(guò)將內(nèi)存接入多插槽系統(tǒng)中特定插槽所換來(lái)的延遲改進(jìn)。
Linux的NUMA優(yōu)化機(jī)制可以通過(guò)以下幾種方式禁用,從而提高性能表現(xiàn):
- 關(guān)閉區(qū)回收模式:向 /etc/sysctl.conf 中添加vm.zone_reclaim_mode = 0并運(yùn)行sysctl -p以載入新設(shè)定。
- 為自己的應(yīng)用程序啟用NUMA交叉存取功能: 在運(yùn)行應(yīng)用時(shí)加入numactl --interleave=all 命令。
以上兩種設(shè)置已經(jīng)成為我們?nèi)可a(chǎn)系統(tǒng)中的默認(rèn)狀態(tài)。
2) 不要對(duì)Linux設(shè)置掉以輕心:親手管理頁(yè)面緩存中的垃圾內(nèi)容
由于GraphDB的日志結(jié)構(gòu)化存儲(chǔ)系統(tǒng)無(wú)法重新使用其數(shù)據(jù)片段,因此承受著時(shí)間的推移我們?cè)贚inux頁(yè)面緩存中產(chǎn)生了大量垃圾內(nèi)容。事實(shí)證明,Linux在正確清理這類垃圾內(nèi)容時(shí)表現(xiàn)得相當(dāng)糟糕:它通常會(huì)不由分說(shuō)地把一切數(shù)據(jù)扔進(jìn)廢紙簍,這種過(guò)分激進(jìn)的處理方式令我們的讀取性能遭遇極高的主要故障比率。直接回收與kswapd都起到了助紂為虐的作用,但前者的負(fù)面作用更為明顯。
我們已經(jīng)為自己的存儲(chǔ)系統(tǒng)添加了片段池,這樣我們就能夠重復(fù)使用這些片段。通過(guò)這種方式,我們降低了需要?jiǎng)?chuàng)建的文件數(shù)量,同時(shí)減小了對(duì)Linux頁(yè)面緩存造成的處理壓力。通過(guò)初步測(cè)試,我們發(fā)現(xiàn)片段池機(jī)制帶來(lái)了令人鼓舞的出色效果。
寫(xiě)在***的話
自從對(duì)區(qū)回收機(jī)制產(chǎn)生懷疑,我們就立即著手在生產(chǎn)系統(tǒng)中關(guān)閉這一模式。事實(shí)證明,我們的調(diào)整帶來(lái)了顯著成效。在過(guò)去的四個(gè)月中,我們的生產(chǎn)主機(jī)一直處于中位延遲狀態(tài)下。不必掌聲鼓勵(lì)、也無(wú)需鮮花簇?fù)恚P(guān)閉區(qū)回收機(jī)制這樣一個(gè)小小的決定讓LinkedIn迎來(lái)了顯而易見(jiàn)的性能提升--這正是我們技術(shù)人員的***樂(lè)趣!