500 行 Python 代碼做一個英文解析器
語法分析器描述了一個句子的語法結構,用來幫助其他的應用進行推理。自然語言引入了很多意外的歧義,以我們對世界的了解可以迅速地發(fā)現(xiàn)這些歧義。舉一個我很喜歡的例子:
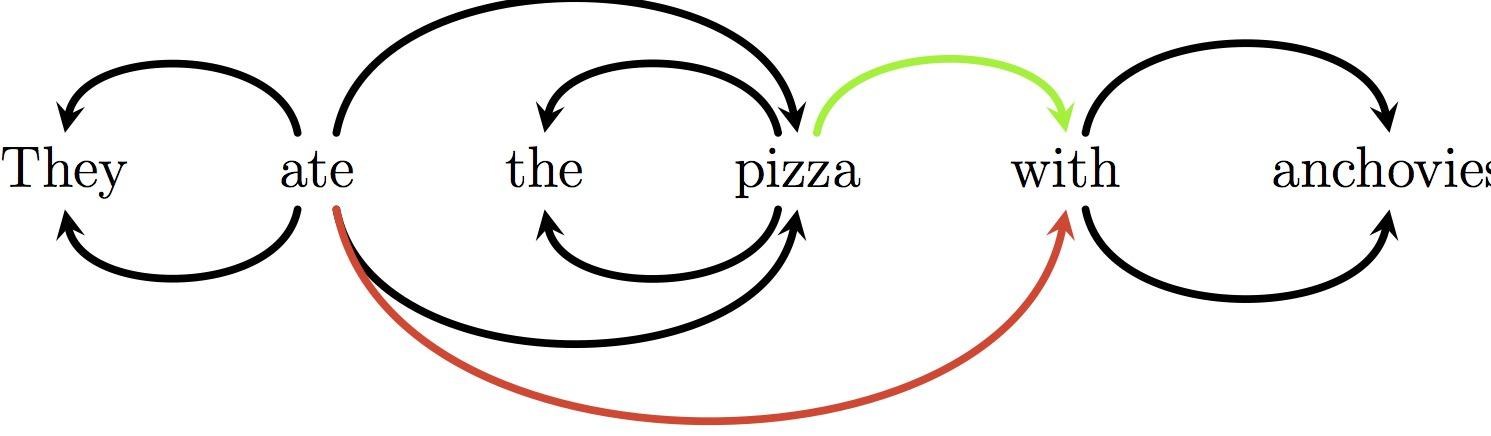
They ate the pizza with anchovies

正確的解析是連接“with”和“pizza”,而錯誤的解析將“with”和“eat”聯(lián)系在了一起:
過去的一些年,自然語言處理(NLP)社區(qū)在語法分析方面取得了很大的進展。現(xiàn)在,小小的 Python 實現(xiàn)可能比廣泛應用的 Stanford 解析器表現(xiàn)得更出色。
解析器 準確度 速度(詞/秒) 語言 位置
Stanford 89.6% 19 Java > 50,000[1]
parser.py 89.8% 2,020 Python ~500
Redshift 93.6% 2,580 Cython ~4,000
文章剩下的部分首先設置了問題,接著帶你了解為此準備的簡潔實現(xiàn)。parser.py 代碼中的前 200 行描述了詞性的標注者和學習者(這里)。除非你非常熟悉 NLP 方向的研究,否則在研究這篇文章之前至少應該略讀。
Cython 系統(tǒng)和 Redshift 是為我目前的研究而寫的。和麥考瑞大學的合同到期后,我計劃六月份對它進行改進,用于一般用途。目前的版本托管在 GitHub 上。
問題描述
在你的手機中輸入這樣一條指令是非常友善的:
Set volume to zero when I’m in a meeting, unless John’s school calls.
接著進行適當?shù)牟呗耘渲谩T?Android 系統(tǒng)上,你可以應用 Tasker 做這樣的事情,而 NL 接口會更好一些。接收可以編輯的語義表示,你就能了解到它認為你表達的意思,并且可以修正他的想法,這樣是特別友善的。
這項工作有很多問題需要解決,但一些種類的句法形態(tài)絕對是必要的。我們需要知道:
Unless John’s school calls, when I’m in a meeting, set volume to zero
是解析指令的又一種方式,而
Unless John’s school, call when I’m in a meeting
表達了完全不同的意思。
依賴解析器返回一個單詞與單詞間的關系圖,使推理變得更容易。關系圖是樹形結構,有向邊,每個節(jié)點(單詞)有且僅有一個入弧(頭部依賴)。
用法示例:
- >>> parser = parser.Parser()
- >>> tokens = "Set the volume to zero when I 'm in a meeting unless John 's school calls".split()
- >>> tags, heads = parser.parse(tokens)
- >>> heads
- [-1, 2, 0, 0, 3, 0, 7, 5, 7, 10, 8, 0, 13, 15, 15, 11]
- >>> for i, h in enumerate(heads):
- ... head = tokens[heads[h]] if h >= 1 else 'None'
- ... print(tokens[i] + ' <-- ' + head])
- Set <-- None
- the <-- volume
- volume <-- Set
- to <-- Set
- zero <-- to
- when <-- Set
- I <-- 'm
- 'm <-- when
- in <-- 'm
- a <-- meeting
- meeting <-- in
- unless <-- Set
- John <-- 's
- 's <-- calls
- school <-- calls
- calls <-- unless
一種觀點是通過語法分析進行推導比字符串應該稍稍容易一些。語義分析映射有望比字面意義映射更簡單。
這個問題最讓人困惑的是正確性是由慣例,即注釋指南決定的。如果你沒有閱讀指南并且不是一個語言學家,就不能判斷解析是否正確,這使整個任務顯得奇怪和虛假。
例如,在上面的解析中存在一個錯誤:根據(jù) Stanford 的注釋指南規(guī)定,“John’s school calls” 存在結構錯誤。而句子這部分的結構是指導注釋器如何解析一個類似于“John’s school clothes”的例子。
這一點值得深入考慮。理論上講,我們已經(jīng)制定了準則,所以“正確”的解析應該相反。如果我們違反約定,有充分的理由相信解析任務會變得更加困難,因為任務和其他語>法的一致性會降低。【2】但是我們可以測試經(jīng)驗,并且我們很高興通過反轉策略獲得優(yōu)勢。
我們確實需要慣例中的差異——我們不希望接收相同的結構,否則結果不會很有用。注釋指南在哪些區(qū)別使下游應用有效和哪些解析器可以輕松預測之間取得平衡。
映射樹
在決定構建什么樣子的關系圖時,我們可以進行一項特別有效的簡化:對將要處理的關系圖結構進行限制。它不僅在易學性方面有優(yōu)勢,在加深算法理解方面也有作用。大部分的>英文解析工作中,我們遵循約束的依賴關系圖就是映射樹:
- 樹。除了根外,每個單詞都有一個弧頭。
- 映射關系。針對每對依賴關系 (a1, a2)和 (b1, b2),如果 a1 < b2, 那么 a2 >= b2。換句話說,依賴關系不能交叉。不可能存在一對 a1 b1 a2 b2 或者 b1 a1 b2 a2 形式的依賴關系。
在解析非映射樹方面有豐富的文獻,解析無環(huán)有向圖方面的文獻相對而言少一些。我將要闡述的解析算法用于映射樹領域。
貪婪的基于轉換的解析
我們的語法分析器以字符串符號列表作為輸入,輸出代表關系圖中邊的弧頭索引列表。如果第 i 個弧頭元素是 j, 依賴關系包括一條邊 (j, i)。基于轉換的語法分析器>是有限狀態(tài)轉換器;它將 N 個單詞的數(shù)組映射到 N 個弧頭索引的輸出數(shù)組。
start MSNBC reported that Facebook bought WhatsApp for $16bn root
0 2 9 2 4 2 4 4 7 0
弧頭數(shù)組表示了 MSNBC 的弧頭:MSNBC 的單詞索引是1,reported 的單詞索引是2, head[1] == 2。你應該已經(jīng)發(fā)現(xiàn)為什么樹形結構如此方便——如果我們輸出一個 DAG 結構,這種結構中的單詞可能包含多個弧頭,樹形結構將不再工作。
雖然 heads 可以表示為一個數(shù)組,我們確實喜歡保持一定的替代方式來訪問解析,以方便高效的提取特征。Parse 類就是這樣:
- class Parse(object):
- def __init__(self, n):
- self.n = n
- self.heads = [None] * (n-1)
- self.lefts = []
- self.rights = []
- for i in range(n+1):
- self.lefts.append(DefaultList(0))
- self.rights.append(DefaultList(0))
- def add_arc(self, head, child):
- self.heads[child] = head
- if child < head:
- self.lefts[head].append(child)
- else:
- self.rights[head].append(child)
和語法解析一樣,我們也需要跟蹤句子中的位置。我們通過在 words 數(shù)組中置入一個索引和引入棧機制實現(xiàn),棧中可以壓入單詞,設置單詞的弧頭時,彈出單詞。所以我們的狀態(tài)數(shù)據(jù)結構是基礎。
- 一個索引 i, 活動于符號列表中
- 到現(xiàn)在為止語法解析器中的加入的依賴關系
- 一個包含索引 i 之前產(chǎn)生的單詞的棧,我們已為這些單詞聲明了弧頭。
解析過程的每一步都應用了三種操作之一:
- SHIFT = 0; RIGHT = 1; LEFT = 2
- MOVES = [SHIFT, RIGHT, LEFT]
- def transition(move, i, stack, parse):
- global SHIFT, RIGHT, LEFT
- if move == SHIFT:
- stack.append(i)
- return i + 1
- elif move == RIGHT:
- parse.add_arc(stack[-2], stack.pop())
- return i
- elif move == LEFT:
- parse.add_arc(i, stack.pop())
- return i
- raise GrammarError("Unknown move: %d" % move)
LEFT 和 RIGHT 操作添加依賴關系并彈棧,而 SHIFT 壓棧并增加緩存中 i 值。
因此,語法解析器以一個空棧開始,緩存索引為0,沒有依賴關系記錄。選擇一個有效的操作,應用到當前狀態(tài)。繼續(xù)選擇操作并應用直到棧為空且緩存索引到達輸入數(shù)組的終點。(沒有逐步跟蹤是很難理解這種算法的。嘗試準備一個句子,畫出映射解析樹,接著通過選擇正確的轉換序列遍歷完解析樹。)
下面是代碼中的解析循環(huán):
- class Parser(object):
- ...
- def parse(self, words):
- tags = self.tagger(words)
- n = len(words)
- idx = 1
- stack = [0]
- deps = Parse(n)
- while stack or idx < n:
- features = extract_features(words, tags, idx, n, stack, deps)
- scores = self.model.score(features)
- valid_moves = get_valid_moves(i, n, len(stack))
- next_move = max(valid_moves, key=lambda move: scores[move])
- idx = transition(next_move, idx, stack, parse)
- return tags, parse
- def get_valid_moves(i, n, stack_depth):
- moves = []
- if i < n:
- moves.append(SHIFT)
- if stack_depth >= 2:
- moves.append(RIGHT)
- if stack_depth >= 1:
- moves.append(LEFT)
- return moves
我們以標記的句子開始,進行狀態(tài)初始化。然后將狀態(tài)映射到一個采用線性模型評分的特征集合。接著尋找得分***的有效操作,應用到狀態(tài)中。
這里的評分模型和詞性標注中的一樣工作。如果對提取特征和使用線性模型評分的觀點感到困惑,你應該復習這篇文章。下面是評分模型如何工作的提示:
- class Perceptron(object)
- ...
- def score(self, features):
- all_weights = self.weights
- scores = dict((clas, 0) for clas in self.classes)
- for feat, value in features.items():
- if value == 0:
- continue
- if feat not in all_weights:
- continue
- weights = all_weights[feat]
- for clas, weight in weights.items():
- scores[clas] += value * weight
- return scores
這里僅僅對每個特征的類權重求和。這通常被表示為一個點積,然而我發(fā)現(xiàn)處理很多類時就不太適合了。
定向解析器(RedShift)遍歷多個候選元素,但最終只會選擇***的一個。我們將關注效率和簡便而忽略其準確性。我們只進行了單一的分析。我們的搜索策略將是完全貪婪的,就像詞性標記一樣。我們將鎖定在選擇的每一步。
如果認真閱讀了詞性標記,你可能會發(fā)現(xiàn)下面的相似性。我們所做的是將解析問題映射到一個使用“扁平化”解決的序列標記問題,或者非結構化的學習算法(通過貪婪搜索)。
#p#
特征集
特征提取代碼總是很丑陋。語法分析器的特征指的是上下文中的一些標識。
- 緩存中的前三個單詞 (n0, n1, n2)
- 堆棧中的棧頂?shù)娜齻€單詞 (s0, s1, s2)
- s0 最左邊的兩個孩子 (s0b1, s0b2);
- s0 最右邊的兩個孩子 (s0f1, s0f2);
- n0 最左邊的兩個孩子 (n0b1, n0b2);
我們指出了上述12個標識的單詞表,詞性標注,和標識關聯(lián)的左右孩子數(shù)目。
因為使用的是線性模型,特征指的是原子屬性組成的三元組。
- def extract_features(words, tags, n0, n, stack, parse):
- def get_stack_context(depth, stack, data):
- if depth >;= 3:
- return data[stack[-1]], data[stack[-2]], data[stack[-3]]
- elif depth >= 2:
- return data[stack[-1]], data[stack[-2]], ''
- elif depth == 1:
- return data[stack[-1]], '', ''
- else:
- return '', '', ''
- def get_buffer_context(i, n, data):
- if i + 1 >= n:
- return data[i], '', ''
- elif i + 2 >= n:
- return data[i], data[i + 1], ''
- else:
- return data[i], data[i + 1], data[i + 2]
- def get_parse_context(word, deps, data):
- if word == -1:
- return 0, '', ''
- deps = deps[word]
- valency = len(deps)
- if not valency:
- return 0, '', ''
- elif valency == 1:
- return 1, data[deps[-1]], ''
- else:
- return valency, data[deps[-1]], data[deps[-2]]
- features = {}
- # Set up the context pieces --- the word, W, and tag, T, of:
- # S0-2: Top three words on the stack
- # N0-2: First three words of the buffer
- # n0b1, n0b2: Two leftmost children of the first word of the buffer
- # s0b1, s0b2: Two leftmost children of the top word of the stack
- # s0f1, s0f2: Two rightmost children of the top word of the stack
- depth = len(stack)
- s0 = stack[-1] if depth else -1
- Ws0, Ws1, Ws2 = get_stack_context(depth, stack, words)
- Ts0, Ts1, Ts2 = get_stack_context(depth, stack, tags)
- Wn0, Wn1, Wn2 = get_buffer_context(n0, n, words)
- Tn0, Tn1, Tn2 = get_buffer_context(n0, n, tags)
- Vn0b, Wn0b1, Wn0b2 = get_parse_context(n0, parse.lefts, words)
- Vn0b, Tn0b1, Tn0b2 = get_parse_context(n0, parse.lefts, tags)
- Vn0f, Wn0f1, Wn0f2 = get_parse_context(n0, parse.rights, words)
- _, Tn0f1, Tn0f2 = get_parse_context(n0, parse.rights, tags)
- Vs0b, Ws0b1, Ws0b2 = get_parse_context(s0, parse.lefts, words)
- _, Ts0b1, Ts0b2 = get_parse_context(s0, parse.lefts, tags)
- Vs0f, Ws0f1, Ws0f2 = get_parse_context(s0, parse.rights, words)
- _, Ts0f1, Ts0f2 = get_parse_context(s0, parse.rights, tags)
- # Cap numeric features at 5?
- # String-distance
- Ds0n0 = min((n0 - s0, 5)) if s0 != 0 else 0
- features['bias'] = 1
- # Add word and tag unigrams
- for w in (Wn0, Wn1, Wn2, Ws0, Ws1, Ws2, Wn0b1, Wn0b2, Ws0b1, Ws0b2, Ws0f1, Ws0f2):
- if w:
- features['w=%s' % w] = 1
- for t in (Tn0, Tn1, Tn2, Ts0, Ts1, Ts2, Tn0b1, Tn0b2, Ts0b1, Ts0b2, Ts0f1, Ts0f2):
- if t:
- features['t=%s' % t] = 1
- # Add word/tag pairs
- for i, (w, t) in enumerate(((Wn0, Tn0), (Wn1, Tn1), (Wn2, Tn2), (Ws0, Ts0))):
- if w or t:
- features['%d w=%s, t=%s' % (i, w, t)] = 1
- # Add some bigrams
- features['s0w=%s, n0w=%s' % (Ws0, Wn0)] = 1
- features['wn0tn0-ws0 %s/%s %s' % (Wn0, Tn0, Ws0)] = 1
- features['wn0tn0-ts0 %s/%s %s' % (Wn0, Tn0, Ts0)] = 1
- features['ws0ts0-wn0 %s/%s %s' % (Ws0, Ts0, Wn0)] = 1
- features['ws0-ts0 tn0 %s/%s %s' % (Ws0, Ts0, Tn0)] = 1
- features['wt-wt %s/%s %s/%s' % (Ws0, Ts0, Wn0, Tn0)] = 1
- features['tt s0=%s n0=%s' % (Ts0, Tn0)] = 1
- features['tt n0=%s n1=%s' % (Tn0, Tn1)] = 1
- # Add some tag trigrams
- trigrams = ((Tn0, Tn1, Tn2), (Ts0, Tn0, Tn1), (Ts0, Ts1, Tn0),
- (Ts0, Ts0f1, Tn0), (Ts0, Ts0f1, Tn0), (Ts0, Tn0, Tn0b1),
- (Ts0, Ts0b1, Ts0b2), (Ts0, Ts0f1, Ts0f2), (Tn0, Tn0b1, Tn0b2),
- (Ts0, Ts1, Ts1))
- for i, (t1, t2, t3) in enumerate(trigrams):
- if t1 or t2 or t3:
- features['ttt-%d %s %s %s' % (i, t1, t2, t3)] = 1
- # Add some valency and distance features
- vw = ((Ws0, Vs0f), (Ws0, Vs0b), (Wn0, Vn0b))
- vt = ((Ts0, Vs0f), (Ts0, Vs0b), (Tn0, Vn0b))
- d = ((Ws0, Ds0n0), (Wn0, Ds0n0), (Ts0, Ds0n0), (Tn0, Ds0n0),
- ('t' + Tn0+Ts0, Ds0n0), ('w' + Wn0+Ws0, Ds0n0))
- for i, (w_t, v_d) in enumerate(vw + vt + d):
- if w_t or v_d:
- features['val/d-%d %s %d' % (i, w_t, v_d)] = 1
- return features
訓練
學習權重和詞性標注使用了相同的算法,即平均感知器算法。它的主要優(yōu)勢是,它是一個在線學習算法:例子一個接一個流入,我們進行預測,檢查真實答案,如果預測錯誤則調(diào)整意見(權重)。
循環(huán)訓練看起來是這樣的:
- class Parser(object):
- ...
- def train_one(self, itn, words, gold_tags, gold_heads):
- n = len(words)
- i = 2; stack = [1]; parse = Parse(n)
- tags = self.tagger.tag(words)
- while stack or (i + 1) < n:
- features = extract_features(words, tags, i, n, stack, parse)
- scores = self.model.score(features)
- valid_moves = get_valid_moves(i, n, len(stack))
- guess = max(valid_moves, key=lambda move: scores[move])
- gold_moves = get_gold_moves(i, n, stack, parse.heads, gold_heads)
- best = max(gold_moves, key=lambda move: scores[move])
- self.model.update(best, guess, features)
- i = transition(guess, i, stack, parse)
- # Return number correct
- return len([i for i in range(n-1) if parse.heads[i] == gold_heads[i]])
訓練過程中最有趣的部分是 get_gold_moves。 通過Goldbery 和 Nivre (2012),我們的語法解析器的性能可能會有所提升,他們曾指出我們錯了很多年。
在詞性標注文章中,我提醒大家,在訓練期間,你要確保傳遞的是***兩個預測標記做為當前標記的特征,而不是***兩個黃金標記。測試期間只有預測標記,如果特征是基于訓練過程中黃金序列的,訓練環(huán)境就不會和測試環(huán)境保持一致,因此將會得到錯誤的權重。
在語法分析中我們面臨的問題是不知道如何傳遞預測序列!通過采用黃金標準樹結構,并發(fā)現(xiàn)可以轉換為樹的過渡序列,等等,使得訓練得以工作,你獲得返回的動作序列,保證執(zhí)行運動,將得到黃金標準的依賴關系。
問題是,如果語法分析器處于任何沒有沿著黃金標準序列的狀態(tài)時,我們不知道如何教它做出的“正確”運動。一旦語法分析器發(fā)生了錯誤,我們不知道如何從實例中訓練。
這是一個大問題,因為這意味著一旦語法分析器開始發(fā)生錯誤,它將停止在不屬于訓練數(shù)據(jù)的任何一種狀態(tài)——導致出現(xiàn)更多的錯誤。
對于貪婪解析器而言,問題是具體的:一旦使用方向特性,有一種自然的方式做結構化預測。
像所有的***突破一樣,一旦你理解了這些,解決方案似乎是顯而易見的。我們要做的就是定義一個函數(shù),此函數(shù)提問“有多少黃金標準依賴關系可以從這種狀態(tài)恢復”。如果能定義這個函數(shù),你可以依次進行每種運動,進而提問,“有多少黃金標準依賴關系可以從這種狀態(tài)恢復?”。如果采用的操作可以讓少一些的黃金標準依賴實現(xiàn),那么它就是次優(yōu)的。
這里需要領會很多東西。
因此我們有函數(shù) Oracle(state):
Oracle(state) = | gold_arcs ∩ reachable_arcs(state) |
我們有一個操作集合,每種操作返回一種新狀態(tài)。我們需要知道:
- shift_cost = Oracle(state) – Oracle(shift(state))
- right_cost = Oracle(state) – Oracle(right(state))
- left_cost = Oracle(state) – Oracle(left(state))
現(xiàn)在,至少一種操作返回0。Oracle(state)提問:“前進的***路徑的成本是多少?”***路徑的***步是轉移,向右,或者向左。
事實證明,我們可以得出 Oracle 簡化了很多過渡系統(tǒng)。我們正在使用的過渡系統(tǒng)的衍生品 —— Arc Hybrid 是 Goldberg 和 Nivre (2013)提出的。
我們把oracle實現(xiàn)為一個返回0-成本的運動的方法,而不是實現(xiàn)一個功能的Oracle(state)。這可以防止我們做一堆昂貴的復制操作。希望代碼中的推理不是太難以理解,如果感到困惑并希望刨根問底的花,你可以參考 Goldberg 和 Nivre 的論文。
- def get_gold_moves(n0, n, stack, heads, gold):
- def deps_between(target, others, gold):
- for word in others:
- if gold[word] == target or gold[target] == word:
- return True
- return False
- valid = get_valid_moves(n0, n, len(stack))
- if not stack or (SHIFT in valid and gold[n0] == stack[-1]):
- return [SHIFT]
- if gold[stack[-1]] == n0:
- return [LEFT]
- costly = set([m for m in MOVES if m not in valid])
- # If the word behind s0 is its gold head, Left is incorrect
- if len(stack) >= 2 and gold[stack[-1]] == stack[-2]:
- costly.add(LEFT)
- # If there are any dependencies between n0 and the stack,
- # pushing n0 will lose them.
- if SHIFT not in costly and deps_between(n0, stack, gold):
- costly.add(SHIFT)
- # If there are any dependencies between s0 and the buffer, popping
- # s0 will lose them.
- if deps_between(stack[-1], range(n0+1, n-1), gold):
- costly.add(LEFT)
- costly.add(RIGHT)
- return [m for m in MOVES if m not in costly]
進行“動態(tài) oracle”訓練過程會產(chǎn)生很大的精度差異——通常為1-2%,和運行時的方式?jīng)]有區(qū)別。舊的“靜態(tài)oracle”貪婪訓練過程已經(jīng)完全過時;沒有任何理由那樣做了。
#p#
總結
我感覺,語言技術,特別是那些相關語法,特別神秘。我不能想象什么樣的程序可以實現(xiàn)。
我認為對于人們來說,***的解決方案可能相當復雜是很自然的。200,000 行的Java包感覺為宜。
但是,僅僅實現(xiàn)一個單一算法時,算法代碼往往很短。當你只實現(xiàn)一種算法時,在寫之前你確實知道要寫什么,你不需要關注任何不必要的具有很大性能影響的抽象概念。
注釋
[1] 我真的不確定如何計算Stanford解析器的代碼行數(shù)。它的jar文件裝載了200k大小內(nèi)容,包括大量不同的模型。這并不重要,但在50k左右似乎是安全的。
[2]例如,如何解析“John’s school of music calls”?你需要確認“John’s school”短語和“John’s school calls”、“John’s school of music calls”有相同的結構。對可以放入短語的不同的“插槽”進行推理是我們推理句法分析的關鍵途徑。你能想到每個短語為具有不同形狀的連接器,你需要插入不同的插槽——每個短語也有一定數(shù)量不同形狀的插槽。我們正試圖弄清楚什么樣的連接器在什么地方,因此可以搞清句子是如何連接在一起的。
[3]這里有使用了“深度學習”技術的 Stanford 解析器更新版本,此版本準確性更高。但是,最終模型的準確度仍排在***的移進歸約分析器后面。這是一篇偉大的文章,該想法在一個語法分析器上實現(xiàn),這個語法分析器是不是***進其實并不重要。
[4]一個細節(jié):Stanford 依賴關系實際上是給定黃金標準短語結構樹自動生成的。參考這里的Stanford依賴轉換器頁面:http://nlp.stanford.edu/software/stanford-dependencies.shtml。
無根據(jù)猜測
長期以來,增量語言處理算法是科學界的主要興趣。如果你想要編寫一個語法分析器來測試人類語句處理器如何工作的理論,那么,這個分析器需要建立部分解釋器。這里有充分的證據(jù),包括常識性反思,它設立我們不緩存的輸入,說話者完成表達立即分析。
但與整齊的科學特征相比,當前算法勝出!盡我所能告訴大家,勝出的秘訣就是:
- 增量。早期的文字限制搜索。
- 錯誤驅動。訓練包含一個發(fā)生錯誤即更新的操作假設。
和人類語句處理的聯(lián)系看起來誘人。我期待看到這些工程的突破是否帶來一些心理語言學方面的進步。
參考書目
NLP 的文獻幾乎完全開放。所有相關論文都可以在這里找到:http://aclweb.org/anthology/。
我所描述的解析器是動態(tài)oracle arc-hybrid 系統(tǒng)的實現(xiàn):
Goldberg, Yoav; Nivre, Joakim
Training Deterministic Parsers with Non-Deterministic Oracles
TACL 2013
然而,我編寫了自己的特征。arc-hybrid 系統(tǒng)的最初描述在這里:
Kuhlmann, Marco; Gomez-Rodriguez, Carlos; Satta, Giorgio
Dynamic programming algorithms for transition-based dependency parsers
ACL 2011
這里最初描述了動態(tài)oracle訓練方法:
A Dynamic Oracle for Arc-Eager Dependency Parsing
Goldberg, Yoav; Nivre, Joakim
COLING 2012
當Zhang 和 Clark 研究定向搜索時,這項工作依賴于以轉換為基礎的解析器在準確性上的重大突破。他們發(fā)表了很多論文,但***的引用是:
Zhang, Yue; Clark, Steven
Syntactic Processing Using the Generalized Perceptron and Beam Search
Computational Linguistics 2011 (1)
另外一篇重要的文章是這個短篇的特征工程文章,這篇文章進一步提高了準確性:
Zhang, Yue; Nivre, Joakim
Transition-based Dependency Parsing with Rich Non-local Features
ACL 2011
作為定向解析器的學習框架,廣義的感知器來自這篇文章
Collins, Michael
Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms
EMNLP 2002
實驗細節(jié)
文章開頭的結果引用了華爾街日報語料庫第22條。Stanford 解析器執(zhí)行如下:
- java -mx10000m -cp "$scriptdir/*:" edu.stanford.nlp.parser.lexparser.LexicalizedParser \
- -outputFormat "penn" edu/stanford/nlp/models/lexparser/englishFactored.ser.gz $*
應用了一個小的后處理,撤銷Stanford 解析器為數(shù)字添加的假設標記,使數(shù)字符合 PTB 標記:
- """Stanford parser retokenises numbers. Split them."""
- import sys
- import re
- qp_re = re.compile('\xc2\xa0')
- for line in sys.stdin:
- line = line.rstrip()
- if qp_re.search(line):
- line = line.replace('(CD', '(QP (CD', 1) + ')'
- line = line.replace('\xc2\xa0', ') (CD ')
- print line
由此產(chǎn)生的PTB格式的文件轉換成使用 Stanford 轉換器的依賴關系:
- for f in $1/*.mrg; do
- echo $f
- grep -v CODE $f > "$f.2"
- out="$f.dep"
- java -mx800m -cp "$scriptdir/*:" edu.stanford.nlp.trees.EnglishGrammaticalStructure \
- -treeFile "$f.2" -basic -makeCopulaHead -conllx > $out
- done
我不能輕易的讀取了,但它應該只是使用相關文獻的一般設置,將一個目錄下的每個.mrg文件轉換成一個CoNULL格式的 Stanford 基本依賴文件。
接著我從華爾街日報語料庫第22條轉換了黃金標準樹進行評估。準確的分數(shù)是指所有未標記標識中未標記的附屬分數(shù)(如弧頭索引)
為了訓練 parser.py,我將華爾街日報語料庫 02-21 的黃金標準 PTB 樹結構輸出到同一個轉換腳本中。
一言以蔽之,Stanford 模型和 parser.py 在同一組語句中進行訓練,在我們知道答案的持有測試集上進行預測。準確性是指我們答對多少正確的語句首詞。
在一個 2.4Ghz 的 Xeon 處理器上測試速度。我在服務器上進行了實驗,為 Stanford 解析器提供了更多內(nèi)存。parser.py 系統(tǒng)在我的MacBook Air上運行良好。在parser.py 的實驗中,我使用了PyPy;與早期的基準相比,CPython大約快了一半。
parser.py 運行如此之快的一個原因是它進行未標記解析。根據(jù)以往的實驗,經(jīng)標記的解析器可能慢400倍,準確度提高大約1%。如果你能訪問數(shù)據(jù),使程序適應已標記的解析器對讀者來說將是很好的鍛煉機會。
RedShift 解析器的結果是從版本 b6b624c9900f3bf 取出的,運行如下:
- ./scripts/train.py -x zhang+stack -k 8 -p ~/data/stanford/train.conll ~/data/parsers/tmp
- ./scripts/parse.py ~/data/parsers/tmp ~/data/stanford/devi.txt /tmp/parse/
- ./scripts/evaluate.py /tmp/parse/parses ~/data/stanford/dev.conll