快速排序算法普及教程
閑不多說。接下來,咱們立刻進入本文章的主題,排序算法。
眾所周知,快速排序算法是排序算法中的重頭戲。
因此,本文就從快速排序開始。
------------------------------------------------------
一、快速排序算法的基本特性
時間復雜度:O(n*lgn)
最壞:O(n^2)
空間復雜度:O(n*lgn)
不穩定。
快速排序是一種排序算法,對包含n個數的輸入數組,平均時間為O(nlgn),最壞情況是O(n^2)。
通常是用于排序的***選擇。因為,基于比較的排序,最快也只能達到O(nlgn)。
二、快速排序算法的描述
算法導論,第7章
快速排序時基于分治模式處理的,
對一個典型子數組A[p...r]排序的分治過程為三個步驟:
1.分解:
A[p..r]被劃分為倆個(可能空)的子數組A[p ..q-1]和A[q+1 ..r],使得
A[p ..q-1] <= A[q] <= A[q+1 ..r]
2.解決:通過遞歸調用快速排序,對子數組A[p ..q-1]和A[q+1 ..r]排序。
3.合并。
三、快速排序算法
版本一:
QUICKSORT(A, p, r)
- if p < r
- then q ← PARTITION(A, p, r) //關鍵
- QUICKSORT(A, p, q - 1)
- QUICKSORT(A, q + 1, r)
數組劃分
快速排序算法的關鍵是PARTITION過程,它對A[p..r]進行就地重排:
- PARTITION(A, p, r)
- x ← A[r]
- i ← p - 1
- for j ← p to r - 1
- do if A[j] ≤ x
- then i ← i + 1
- exchange A[i] <-> A[j]
- exchange A[i + 1] <-> A[r]
- return i + 1
ok,咱們來舉一個具體而完整的例子。
來對以下數組,進行快速排序,
2 8 7 1 3 5 6 4(主元)
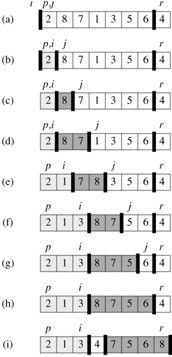
一、
i p/j
2 8 7 1 3 5 6 4(主元)
j指的2<=4,于是i++,i也指到2,2和2互換,原數組不變。
j后移,直到指向1..
二、
j(指向1)<=4,于是i++
i指向了8,所以8與1交換。
數組變成了:
i j
2 1 7 8 3 5 6 4
三、j后移,指向了3,3<=4,于是i++
i這是指向了7,于是7與3交換。
數組變成了:
i j
2 1 3 8 7 5 6 4
四、j繼續后移,發現沒有再比4小的數,所以,執行到了***一步,
即上述PARTITION(A, p, r)代碼部分的 第7行。
因此,i后移一個單位,指向了8
i j
2 1 3 8 7 5 6 4
A[i + 1] <-> A[r],即8與4交換,所以,數組最終變成了如下形式,
2 1 3 4 7 5 6 8
ok,快速排序***趟完成。
4把整個數組分成了倆部分,2 1 3,7 5 6 8,再遞歸對這倆部分分別快速排序。
i p/j
2 1 3(主元)
2與2互換,不變,然后又是1與1互換,還是不變,***,3與3互換,不變,
最終,3把2 1 3,分成了倆部分,2 1,和3.
再對2 1,遞歸排序,最終結果成為了1 2 3.
7 5 6 8(主元),7、5、6、都比8小,所以***趟,還是7 5 6 8,
不過,此刻8把7 5 6 8,分成了 7 5 6,和8.[7 5 6->5 7 6->5 6 7]
再對7 5 6,遞歸排序,最終結果變成5 6 7 8。
ok,所有過程,全部分析完成。
***,看下我畫的圖:

快速排序算法版本二
不過,這個版本不再選取(如上***版本的)數組的***一個元素為主元,
而是選擇,數組中的***個元素為主元。
- /**************************************************/
- /* 函數功能:快速排序算法 */
- /* 函數參數:結構類型table的指針變量tab */
- /* 整型變量left和right左右邊界的下標 */
- /* 函數返回值:空 */
- /* 文件名:quicsort.c 函數名:quicksort () */
- /**************************************************/
- void quicksort(table *tab,int left,int right)
- {
- int i,j;
- if(left<right)
- {
- i=left;j=right;
- tab->r[0]=tab->r[i]; //準備以本次最左邊的元素值為標準進行劃分,先保存其值
- do
- {
- while(tab->r[j].key>tab->r[0].key&&i<j)
- j--; //從右向左找第1個小于標準值的位置j
- if(i<j) //找到了,位置為j
- {
- tab->r[i].key=tab->r[j].key;i++;
- } //將第j個元素置于左端并重置i
- while(tab->r[i].key<tab->r[0].key&&i<j)
- i++; //從左向右找第1個大于標準值的位置i
- if(i<j) //找到了,位置為i
- {
- tab->r[j].key=tab->r[i].key;j--;
- } //將第i個元素置于右端并重置j
- }while(i!=j);
- tab->r[i]=tab->r[0]; //將標準值放入它的最終位置,本次劃分結束
- quicksort(tab,left,i-1); //對標準值左半部遞歸調用本函數
- quicksort(tab,i+1,right); //對標準值右半部遞歸調用本函數
- }
- }
----------------
ok,咱們,還是以上述相同的數組,應用此快排算法的版本二,來演示此排序過程:
這次,以數組中的***個元素2為主元。
2(主) 8 7 1 3 5 6 4
請細看:
2 8 7 1 3 5 6 4
i-> <-j
(找大) (找小)
一、j
j找***個小于2的元素1,1賦給(覆蓋重置)i所指元素2
得到:
1 8 7 3 5 6 4
i j
二、i
i找到***個大于2的元素8,8賦給(覆蓋重置)j所指元素(NULL<-8)
1 7 8 3 5 6 4
i <-j
三、j
j繼續左移,在與i碰頭之前,沒有找到比2小的元素,結束。
***,主元2補上。
***趟快排結束之后,數組變成:
1 2 7 8 3 5 6 4
第二趟,
7 8 3 5 6 4
i-> <-j
(找大) (找小)
一、j
j找到4,比主元7小,4賦給7所處位置
得到:
4 8 3 5 6
i-> j
二、i
i找比7大的***個元素8,8覆蓋j所指元素(NULL)
4 3 5 6 8
i j
4 6 3 5 8
i-> j
i與j碰頭,結束。
第三趟:
4 6 3 5 7 8
......
以下,分析原理,一致,略過。
***的結果,如下圖所示:
1 2 3 4 5 6 7 8
相信,經過以上內容的具體分析,你一定明了了。
***,貼一下我畫的關于這個排序過程的圖:


完。一月五日補充。
OK,上述倆種算法,明白一種即可。
-------------------------------------------------------------
五、快速排序的最壞情況和最快情況。
最壞情況發生在劃分過程產生的倆個區域分別包含n-1個元素和一個0元素的時候,
即假設算法每一次遞歸調用過程中都出現了,這種劃分不對稱。那么劃分的代價為O(n),
因為對一個大小為0的數組遞歸調用后,返回T(0)=O(1)。
估算法的運行時間可以遞歸的表示為:
T(n)=T(n-1)+T(0)+O(n)=T(n-1)+O(n).
可以證明為T(n)=O(n^2)。
因此,如果在算法的每一層遞歸上,劃分都是***程度不對稱的,那么算法的運行時間就是O(n^2)。
亦即,快速排序算法的最壞情況并不比插入排序的更好。
此外,當數組完全排好序之后,快速排序的運行時間為O(n^2)。
而在同樣情況下,插入排序的運行時間為O(n)。
//注,請注意理解這句話。我們說一個排序的時間復雜度,是僅僅針對一個元素的。
//意思是,把一個元素進行插入排序,即把它插入到有序的序列里,花的時間為n。
再來證明,最快情況下,即PARTITION可能做的最平衡的劃分中,得到的每個子問題都不能大于n/2.
因為其中一個子問題的大小為|_n/2_|。另一個子問題的大小為|-n/2-|-1.
在這種情況下,快速排序的速度要快得多。為,
T(n)<=2T(n/2)+O(n).可以證得,T(n)=O(nlgn)。
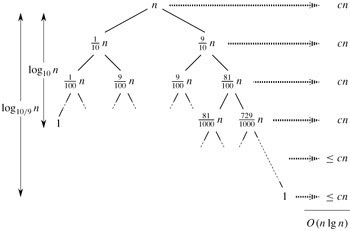
直觀上,看,快速排序就是一顆遞歸數,其中,PARTITION總是產生9:1的劃分,
總的運行時間為O(nlgn)。各結點中示出了子問題的規模。每一層的代價在右邊顯示。
每一層包含一個常數c。
=============================================
請各位自行,思考以下這個版本,對應于上文哪個版本?
- HOARE-PARTITION(A, p, r)
- x ← A[p]
- i ← p - 1
- j ← r + 1
- while TRUE
- do repeat j ← j - 1
- until A[j] ≤ x
- repeat i ← i + 1
- until A[i] ≥ x
- if i < j
- then exchange A[i] ↔ A[j]
- else return j
我常常思考,為什么有的人當時明明讀懂明白了一個算法,
而一段時間過后,它又對此算法完全陌生而不了解了列?
我想,究其根本,還是沒有徹底明白此快速排序算法的原理,與來龍去脈...
那作何改進列,只能找發明那個算法的原作者了,從原作者身上,再多挖掘點有用的東西出來。
=========================================
***,再給出一個快速排序算法的簡潔示例:
Quicksort函數
- void quicksort(int l, int u)
- { int i, m;
- if (l >= u) return;
- swap(l, randint(l, u));
- m = l;
- for (i = l+1; i <= u; i++)
- if (x[i] < x[l])
- swap(++m, i);
- swap(l, m);
- quicksort(l, m-1);
- quicksort(m+1, u);
- }
如果函數的調用形式是quicksort(0, n-1),那么這段代碼將對一個全局數組x[n]進行排序。
函數的兩個參數分別是將要進行排序的子數組的下標:l是較低的下標,而u是較高的下標。
函數調用swap(i,j)將會交換x[i]與x[j]這兩個元素。
***次交換操作將會按照均勻分布的方式在l和u之間隨機地選擇一個劃分元素。