堆排序算法普及教程
本文參考:Introduction To Algorithms,second edition。
本文我們要講的是堆排序算法。據我所知,要真正徹底認識一個算法,***是去查找此算法的原***的論文或相關文獻。
ok,此節,咱們開始吧。
一、堆排序算法的基本特性
時間復雜度:O(nlgn)...
//等同于歸并排序
最壞:O(nlgn)
空間復雜度:O(1).
不穩定。
二、堆與***堆的建立
要介紹堆排序算法,咱們得先從介紹堆開始,然后到建立***堆,***才講到堆排序算法。
2.1、堆的介紹
如下圖,
a),就是一個堆,它可以被視為一棵完全二叉樹。
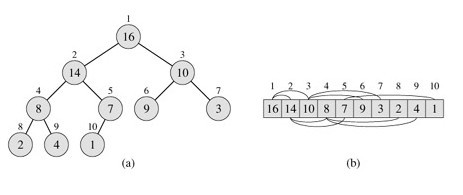
每個堆對應于一個數組b),假設一個堆的數組A,
我們用length[A]表述數組中的元素個數,heap-size[A]表示本身存放在A中的堆的元素個數。
當然,就有,heap-size[A]<=length[A]。
樹的根為A[1],i表示某一結點的下標,
則父結點為PARENT(i),左兒子LEFT[i],右兒子RIGHT[i]的關系如下:
PARENT(i)
return |_i/2_|
LEFT(i)
return 2i
RIGHT(i)
return 2i + 1
二叉堆根據根結點與其子結點的大小比較關系,分為***堆和最小堆。
***堆:
根以外的每個結點i都不大于其根結點,即根為***元素,在頂端,有
A[PARENT(i)] (根)≥ A[i] ,
最小堆:
根以外的每個結點i都不小于其根結點,即根為最小元素,在頂端,有
A[PARENT(i)] (根)≤ A[i] .
在本節的堆排序算法中,我們采用的是***堆;最小堆,通常在構造最小優先隊列時使用。
由前面,可知,堆可以看成一棵樹,所以,堆的高度,即為樹的高度,O(lgn)。
所以,一般的操作,運行時間都是為O(lgn)。
具體,如下:
The MAX-HEAPIFY:O(lgn) 這是保持***堆的關鍵.
The BUILD-MAX-HEAP:線性時間。在無序輸入數組基礎上構造***堆。
The HEAPSORT:O(nlgn) time, 堆排序算法是對一個數組原地進行排序.
The MAX-HEAP-INSERT, HEAP-EXTRACT-MAX, HEAP-INCREASE-KEY, HEAP-MAXIMUM:O(lgn)。
可以讓堆作為最小優先隊列使用。
2.2.1、保持堆的性質(O(lgn))
為了保持***堆的性質,我們運用MAX-HEAPIFY操作,作調整,遞歸調用此操作,使i為根的子樹成為***堆。
MAX-HEAPIFY算法,如下所示(核心):
- MAX-HEAPIFY(A, i)
- l ← LEFT(i)
- r ← RIGHT(i)
- if l ≤ heap-size[A] and A[l] > A[i]
- then largest ← l
- else largest ← i
- if r ≤ heap-size[A] and A[r] > A[largest]
- then largest ← r
- if largest ≠ i
- then exchange A[i] <-> A[largest]
- MAX-HEAPIFY(A, largest)
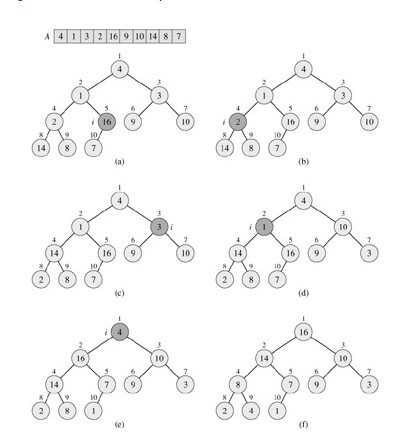
如上,首先***步,在對應的數組元素A[i], 左孩子A[LEFT(i)], 和右孩子A[RIGHT(i)] 中找到***的那一個,將其下標存儲在largest中。如果A[i]已經就是***的元素,則程序直接結束。否則,i的某個子結點為***的元素,將其,即 A[largest]與A[i]交換,從而使i及其子女都能滿足***堆性質。下標largest所指的元素變成了A[i]的值,會違反***堆性質,所以對 largest所指元素調用MAX-HEAPIFY。如下,是此MAX-HEAPIFY的演示過程(下圖是把4調整到***層,一趟操作,但摸索的時間為LogN):
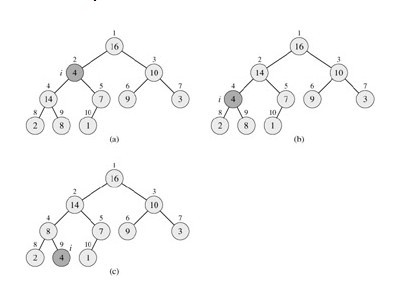
由上圖,我們很容易看出,初始構造出一***堆之后,在元素A[i],即16, 大于它的倆個子結點4、10,滿足***堆性質。所以,i下調指向著4,小于,左子14,所以,調用MAX-HEAPIFY,4與其子,14交換位置。但4 處在了14原來的位置之后,4小于其右子8,又違反了***堆的性質,所以再遞歸調用MAX-HEAPIFY,將4與8,交換位置。于是,滿足了***堆性 質,程序結束。
2.2.2、MAX-HEAPIFY的運行時間
MAX-HEAPIFY作用在一棵以結點i為根的、大小為n的子樹上時,其運行時間為調整元素A[i]、A[LEFT(i)],A[RIGHT(i)]的 關系時所用時間為O(1),再加上,對以i的某個子結點為根的子樹調用MAX-HEAPIFY所需的時間,且i結點的子樹大小至多為2n/3,所 以,MAX-HEAPIFY的運行時間為
T (n) ≤ T(2n/3) + Θ(1).
我們,可以證得此式子的遞歸解為T(n)=O(lgn)。具體證法,可參考算法導論第6章之6.2節,這里,略過。
2.3.1、建堆(O(N))
BUILD-MAX-HEAP(A)
- heap-size[A] ← length[A]
- for i ← |_length[A]/2_| downto 1
- do MAX-HEAPIFY(A, i) //建堆,怎么建列?原來就是不斷的調用MAX-HEAPIFY(A, i)來建立***堆。
BUILD-MAX-HEAP通過對每一個其它結點,都調用一次MAX-HEAPIFY,
來建立一個與數組A[1...n]相對應的***堆。A[(|_n/2_|+1) ‥ n]中的元素都是樹中的葉子。
因此,自然而然,每個結點,都可以看作一個只含一個元素的堆。
關于此過程BUILD-MAX-HEAP(A)的正確性,可參考算法導論 第6章之6.3節。
下圖,是一個此過程的例子(下圖是不斷的調用MAX-HEAPIFY操作,把所有的違反堆性質的數都要調整,共N趟操作,然,摸索時間最終精確為O(N)):
2.3.2、BUILD-MAX-HEAP的運行時間
因為每次調用MAX-HEAPPIFY的時間為O(lgn),而共有O(n)次調用,所以BUILD-MAX-HEAP的簡單上界為O(nlgn)。算法導論一書提到,盡管這個時間界是對的,但從漸進意義上,還不夠精確。
那么,更精確的時間界,是多少列?
由于,MAX-HEAPIFY在樹中不同高度的結點處運行的時間不同,且大部分結點的高度都比較小,
而我們知道,一n個元素的堆的高度為|_lgn_|(向下取整),且在任意高度h上,至多有|-n/2^h+1-|(向上取整)個結點。
因此,MAX-HEAPIFY作用在高度為h的結點上的時間為O(h),所以,BUILD-MAX-HEAP的上界為:O(n)。具體推導過程,略。
三、堆排序算法
所謂的堆排序,就是調用上述倆個過程:一個建堆的操作、BUILD-MAX-HEAP,一個保持***堆的操作、MAX-HEAPIFY。詳細算法如下:
HEAPSORT(A) //n-1次調用MAX-HEAPIFY,所以,O(n*lgn)
- BUILD-MAX-HEAP(A) //建***堆,O(n)
- for i ← length[A] downto 2
- do exchange A[1] <-> A[i]
- heap-size[A] ← heap-size[A] - 1
- MAX-HEAPIFY(A, 1) //保持堆的性質,O(lgn)
如上,即是堆排序算法的完整表述。下面,再貼一下上述堆排序算法中的倆個建堆、與保持***堆操作:
- BUILD-MAX-HEAP(A) //建堆
- heap-size[A] ← length[A]
- for i ← |_length[A]/2_| downto 1
- do MAX-HEAPIFY(A, i)
- MAX-HEAPIFY(A, i) //保持***堆
- l ← LEFT(i)
- r ← RIGHT(i)
- if l ≤ heap-size[A] and A[l] > A[i]
- then largest ← l
- else largest ← i
- if r ≤ heap-size[A] and A[r] > A[largest]
- then largest ← r
- if largest ≠ i
- then exchange A[i] <-> A[largest]
- MAX-HEAPIFY(A, largest)
以下是,堆排序算法的演示過程(通過,頂端***的元素與***一個元素不斷的交換,交換后又不斷的調用MAX-HEAPIFY以重新維持***堆的性質,***,一個一個的,從大到小的,把堆中的所有元素都清理掉,也就形成了一個有序的序列。這就是堆排序的全部過程。):
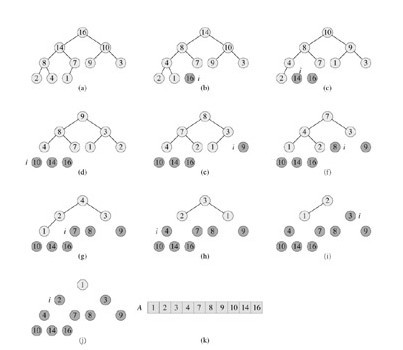
上圖中,a->b,b->c,....之間,都有一個頂端***元素與最小元素交換后,調用MAX-HEAPIFY的過程,我們知道,此MAX-HEAPIFY的運行時間為O(lgn),而要完成整個堆排序的過程,共要經過O(n)次這樣的MAX-HEAPIFY操作。所以,才有堆排序算法的運行時間為O(n*lgn)。
后續:把堆想象成為一種樹,二叉樹之類的。所以,用堆做數據查找、刪除的時間復雜度皆為O(logN)。 那么是一種什么樣的二叉樹列?一種特殊的二叉樹,分為***堆,最小堆。***堆,就是上頭大,下頭小。最小堆就是上頭小,下頭大。
作者:July