SSLStrip終極版——location瞞天過海
前言
之前介紹了HTTPS 前端劫持的方案,雖然很有趣,然而現實卻并不理想。其唯一、也是***的缺陷,就是無法阻止腳本跳轉。若是沒有這個缺陷,那就非常***了——當然也就沒有必要寫這篇文章了。
說到底,還是因為無法重寫location這個對象——它是腳本跳轉的唯一渠道。盡管也流傳一些Hack能勉強實現,但終究是不靠譜的。
事實上,在最近封稿的HTML5 標準里,已非常明確了location 的地位——Unforgeable。
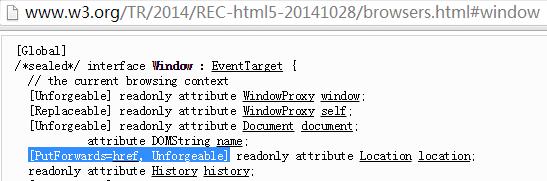
這是個不幸的消息。不過也是件好事,讓我們徹底打消各種偏門邪道的念頭,尋求一條全新的出路。
替換明文URL
上回也提到,可以參考 SSLStrip 那樣,把腳本里的 HTTPS URL 全都替換成 HTTP 版本,即可滿足部分場合。
當然,缺陷也是顯而易見的。只要 URL 不是以明文出現 —— 例如通過字符串拼接而成,那就完全無法識別了,最終還是無法避免跳轉到 HTTPS 頁面上。
這種情況并不少見,所以我們需要更先進的解決方案。
替換location
盡管我們無法重寫 location,但要山寨一個和 location 功能一樣的玩意,還是非常容易的。我們只需定義幾個 getter 和 setter,即可模擬出一個功能完全相同的location2。但如何將原先的 location 映射過來呢?
這時,后端的作用就發揮出來了。類似替換 HTTPS URL,這次我們只關注腳本里的 location 字符,把它們都改成 location2 —— 于是所有和地址欄相關的讀寫,都將落到我們的代理上面。之后能做什么,不用說大家也都明白吧。

代理所有的 setter:如果跳轉到 HTTPS 就將其攔下,然后降級到 HTTP 版本上。
代理所有的 getter:如果當前處于降級的頁面,我們將返回的路徑都還原 HTTPS 字符,即可騙過協議判斷腳本,讓那些自檢功能徹底失效!
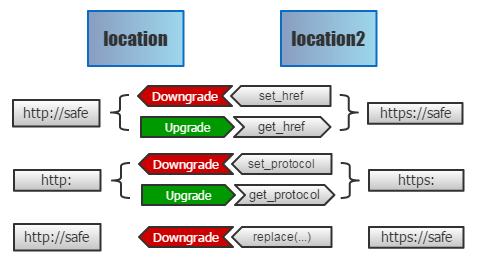
相比之前的 URL 替換,這個方案***太多 —— URL 是動態創建的非常普遍,但 location 不是明文出現的,及其罕見。
除非腳本是加密過的,否則即使用 Uglify 那樣的壓縮工具,也不會把全局變量給混淆。至于人為刻意去轉義它,更是無稽之談了。
if (window['loc\ation'].protocol != 'https:') {
// ...
}
到此,我們的目標已經明確了:
前端:實現一個 location 代理。
后端:將腳本里出現的 location 替換成代理變量名。
處理外鏈腳本
雖然替換頁面腳本的內容并不困難,但對于外鏈腳本,那就不容樂觀了。
現實中,不少頁面外鏈了 HTTPS 絕對路徑 的腳本。這時,我們的中間人就無能為力了。為了避免這種情況,我們仍需替換頁面里的 HTTPS URL,讓中間人能掌控更多的資源。

要替換 URL 倒也不難,一個簡單的正則就能實現 —— 但既然使用正則,我們面對的只能是字符串了。
然而事實上,收到的都是最原始的二進制數據,甚至未必都是 UTF-8 的。在上一篇文章里,我們為了簡單,直接使用二進制的方式注入。但在如今,這個方法顯然不可行了。
使用二進制,不僅難以控制,而且很不嚴謹。我們很難得知匹配到的是獨立的字符,還是一個寬字符的部分字節。因此,我們還是得用傳統可靠的方式來處理字符串。
處理字集編碼
我們得借助字集轉換庫,例如大名鼎鼎的 iconv,來協助完成這件事:
首先將二進制數據轉換成 UTF-8 字符串
有了標準的字符串,我們的正則即可順利執行了
將處理完的字符串,重新換回先前的編碼
盡管這一來一回得折騰兩次,性能又得耗費不少,但這仍是必須的。
事實上,這個過程也不是想象的那么順利。有相當多的服務器,并沒有在返回的 Content-Type 里指定編碼字集,于是我們只能嘗試從頁面的 中獲取。
但這個標簽兼容諸多規范,例如過去的:
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; CHARSET=GBK">
以及如今流行的:
<meta charset="GBK" />
盡管通過正則很容易獲取,但用正則的前提還是得先有字符串,于是我們陷入了僵局。
不過好在標簽、屬性、字集名,基本都是純 ASCII 字符,所以可先將二進制轉成默認的 UTF-8 字符串,從中取出字集信息,然后再進行轉碼。
處理數據分塊
得益于豐富的第三方擴展,上述問題都不難解決。
然而,之前提到過『前端劫持』的一個巨大優勢 —— 無需處理所有數據,只需在***個 chunk 里注入代碼即可。但現在,這項優勢面臨著嚴峻的考驗。
我們要替換頁面里的 HTTPS 資源、location 變量等等,它們會出現在頁面的各個位置。如果我們對每個 chunk 進行單獨過濾、轉發,這樣會有問題嗎?
現實中,未必都是這樣理想的 —— 總會有那么一定的幾率,替換的關鍵字正好跨越兩個 chunk:
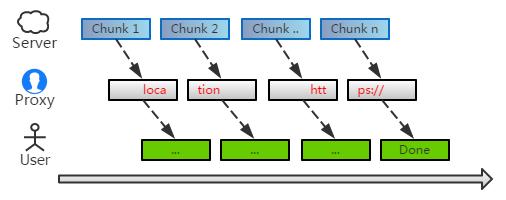
這時候,殘缺的首尾都無法匹配到,于是就會出現遺漏。關鍵字越長,出現的幾率也就越大。對于 URL 這樣長的字符串來說,這是一個潛在的隱患。
要***解決這個問題,是比較麻煩的。不過有個簡單的辦法:我們可以扣留下 chunk 末尾部分字符,拼接到下個 chunk 的之前,從而降低遺漏的可能。
當然,如果不考慮用戶體驗的話,還是收集完所有數據,***一次性處理,最省事了。
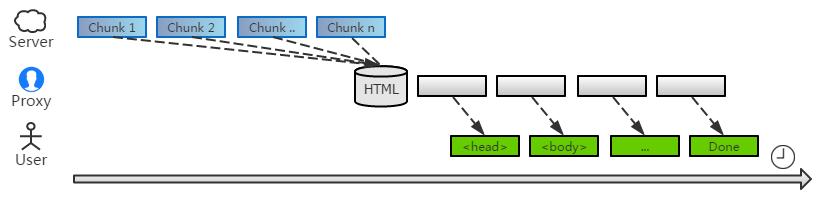
事實上還有更好的方案:中間人開啟一個緩沖區,將收到數據暫時緩存其中。當數據積累到一定量、或者超過多久沒有數據時,才開始批量處理緩存隊列。
這樣就可以避免 頻繁的 chunk 上下文處理,同時也 不會長時間阻塞用戶的響應時間,自然是兩全其美的。
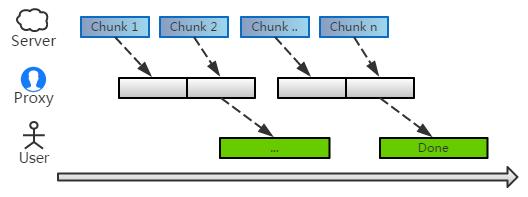
這是不是有點類似 TCP nagle 的味道呢。
前端location代理
講完了后端的相關細節,我們繼續回到前端的話題上。
實現一個 location 的代理很簡單,不過值得留意的細節倒是不少:
location 不僅存在于 window,其實 document 里也有個相同的。
location 對象本身也是可以被賦值的,效果等同于 location.href。([PutForwards=href, ...]已經很好的解釋了)
同理,location 的 toString 返回的也是 href 屬性。
如果帶有 location2 的腳本被緩存住了,那么用戶在沒有劫持的頁面里,也許就會報錯。所以還得留一條兼容的后路。
......
只要考慮充分,實現一個 location 的切面還算是比較容易的。
動態腳本劫持
前面談到替換頁面的 HTTPS URL,以確保外鏈腳本明文傳輸。
然而現實中,并非所有腳本都是靜態的。如今這個腳本泛濫的時代,動態加載模塊是很常見的事。如果引入的是一個 HTTPS 的腳本,那么我們的中間人又無從下手了。
不過值得慶幸的是,模塊攔截不像 location 那樣無法實現。現實中,有非常多的方法可以攔截動態模塊。在之前寫的《XSS 前端防火墻 —— 可疑模塊攔截》 一文里,已經詳細討論過各種方法和細節,這里正好派上用場。
事實上,除了腳本外,框架頁同樣也存在這個問題。上一篇文章里,我們采用 CSP 來阻擋 HTTPS 的框架頁。但那僅僅是屏蔽,并不是真正意義的攔截。只有加上如今這套鉤子系統,才算一個完善的攔截系統。
演示
說了那么多,真正的核心無非就是改變腳本里的 location 變量而已,其他的一切都只是為了輔助它。
下面我們找幾個之前無法成功的網站,試驗下這個加強版的劫持工具。
上一篇文章里提到京東登錄,就是通過腳本跳轉的。我們首先就拿它測試:
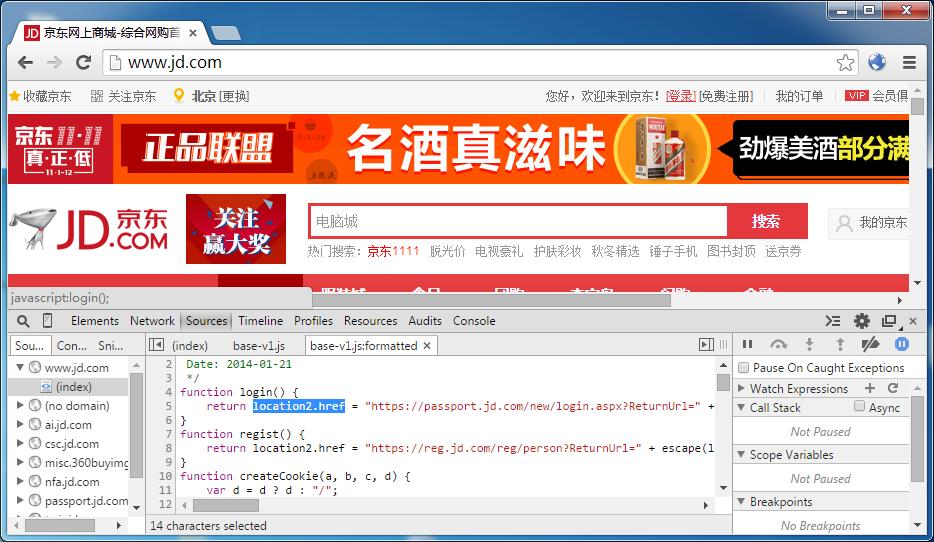
當流量經過中間人代理,頁面和腳本里的 location 都變成了我們的變量名。于是之后和地址欄相關的一切,盡在我們的掌控之中了:
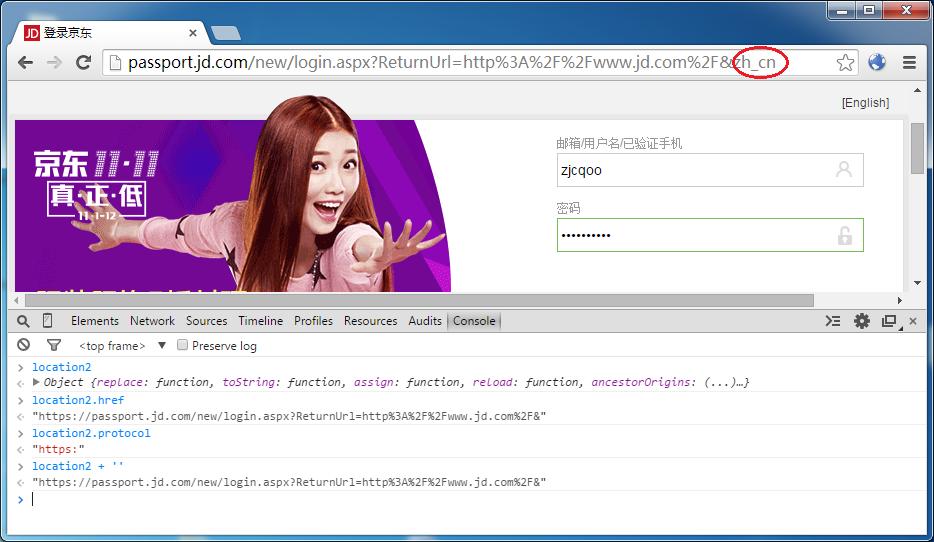
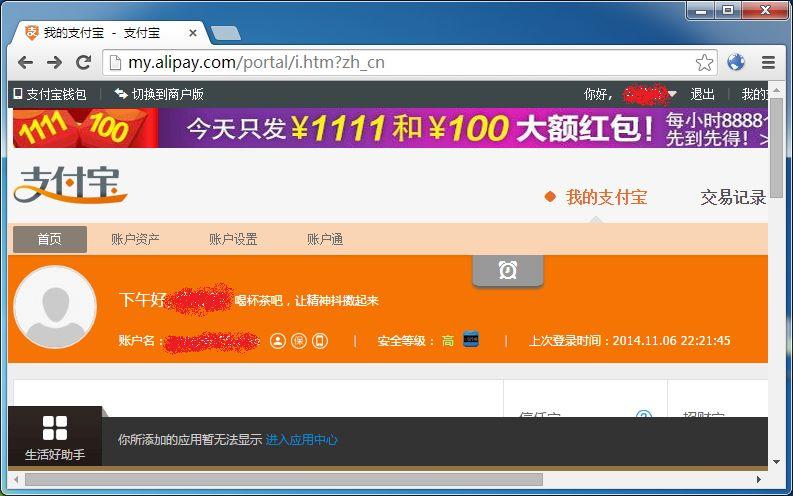
注意地址欄里有一個 zh_cn 的標記,那正是 URL 向下轉型后的識別暗號。
通過 location2 獲取到的一切屬性,看起來就像在 HTTPS 頁面上一模一樣。即使腳本里有自檢功能,也會被我們的虛擬環境所欺騙。
點擊登錄,自然是成功的。

畢竟,HTTPS 和 HTTP 只是傳輸上的差異。在應用層上,頁面是無法知曉的 —— 除了詢問腳本的 location,但它已被我們劫持了。
除了京東的腳本跳轉,財付通網站則是通過非主流的 進行的。
好在我們對頁面里的 HTTPS URL 都替換了,所以仍然能夠跳轉到降級后的頁面:
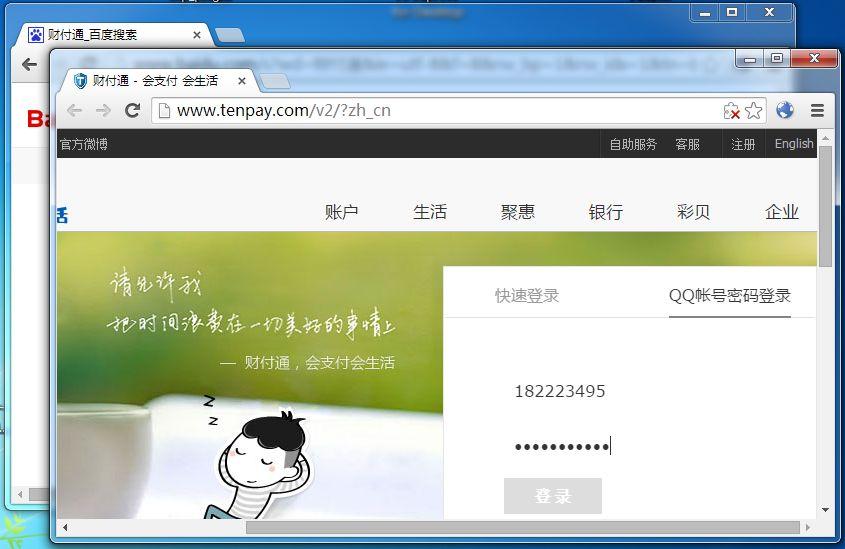
值得注意的是,如果是從 QQ 圖標里點進來的,那么頁面就直接進入 HTTPS 版本,就不會被劫持了。但從第三方過來那就聽天由命了。
由于一般開發人員的思維,是不可能轉義 location 這個變量的。因此這套方案幾乎可以通殺所有的安全站點。
當然,外國的網站也是一樣的。只要之前沒有被 HSTS 所緩存,劫持依舊輕松自如。
......
所以,只要發揮無盡的想象,實現一個工程化的通用劫持方案,依然是可行的。
防范措施
如果你是仔細看完本文的話,應該早就想到如何應對了。
事實上,由于 JS 具有超強的靈活性,幾乎無法從靜態源碼推測運行時的行為。
因此,只要將涉及 location 相關操作,進行簡單的轉義混淆,就能躲過中間人的劫持了。畢竟,要在劫持流量的同時,還要對腳本進行語法分析,這個代價不免有點大了。