













讓SQL用戶快速進入Hadoop大數據時代 —— Transwarp Inceptor是怎樣煉成的
在使用Spark作出計算平臺的解決方案中,有兩種主流編程模型,一類是基于Spark API或者衍生出來的語言,另一種是基于SQL語言。SQL作為數據庫領域的事實標準語言,相比較用API(如MapReduce API,Spark API等)來構建大數據分析的解決方案有著先天的優勢:一是產業鏈完善,各種報表工具、ETL工具等可以很好的對接;二是用SQL開發有更低的技術門檻;三是能夠降低原有系統的遷移成本等。因此,SQL語言也漸漸成為大數據分析的主流技術標準。本文將深入解析Inceptor的架構、編程模型和編譯優化技術,并提供基準測試在多平臺上的性能對比數據。
1. Inceptor架構
Transwarp Inceptor是基于Spark的分析引擎,如圖1所示,從下往上有三層架構:最下面是存儲層,包含分布式內存列式存儲(Transwarp Holodesk),可建在內存或者SSD上;中間層是Spark計算引擎層,星環做了大量的改進保證引擎有超強的性能和高度的健壯性;最上層包括一個完整的SQL 99和PL/SQL編譯器、統計算法庫和機器學習算法庫,提供完整的R語言訪問接口。

圖1:Transwarp Inceptor架構圖
Transwarp Inceptor可以分析存儲在HDFS、HBase或者Transwarp Holodesk分布式緩存中的數據,可以處理的數據量從GB到數十TB,即使數據源或者中間結果的大小遠大于內存容量也可高效處理。另外Transwarp Inceptor通過改進Spark和YARN的組合,提高了Spark的可管理性。同時星環不僅僅是將Spark作為一個缺省計算引擎,也重寫了SQL編譯器,提供更加完整的SQL支持。
同時,Transwarp Inceptor還通過改進Spark使之更好地與HBase融合,可以為HBase提供完整的SQL支持,包括批量SQL統計、OLAP分析以及高并發低延時的SQL查詢能力,使得HBase的應用可以從簡單的在線查詢應用擴展到復雜分析和在線應用結合的混合應用中,大大拓展了HBase的應用范圍。
2. 編程模型
Transwarp Inceptor提供兩種編程模型:一是基于SQL的編程模型,用于常規的數據分析、數據倉庫類應用市場;二是基于數據挖掘編程模型,可以利用R語言或者Spark MLlib來做一些深度學習、數據挖掘等業務模型。
2.1 SQL模型
Transwarp Inceptor實現了自己的SQL解析執行引擎,可以兼容SQL 99和HiveQL,自動識別語法,因此可以兼容現有的基于Hive開發的應用。由于Transwarp Inceptor完整支持標準的SQL 99標準,傳統數據庫上運行的業務可以非常方便的遷移到Transwarp Inceptor系統上。此外Transwarp Inceptor支持PL/SQL擴展,傳統數據倉庫的基于PL/SQL存儲過程的應用(如ETL工具)可以非常方便的在Inceptor上并發執行。另外Transwarp Inceptor支持部分SQL 2003標準,如窗口統計功能、安全審計功能等,并對多個行業開發了專門的函數庫,因此可以滿足多個行業的特性需求。
2.2 數據挖掘計算模型
Transwarp Inceptor實現了機器學習算法庫與統計算法庫,支持常用機器學習算法并行化與統計算法并行化,并利用Spark在迭代計算和內存計算上的優勢,將并行的機器學習算法與統計算法運行在Spark上。例如:機器學習算法庫有包括邏輯回歸、樸素貝葉斯、支持向量機、聚類、線性回歸、關聯挖掘、推薦算法等,統計算法庫包括均值、方差、中位數、直方圖、箱線圖等。Transwarp Inceptor可以支持用R語言或者Spark API在平臺上搭建多種分析型應用,例如用戶行為分析、精準營銷、對用戶貼標簽、進行分類。
3. SQL編譯與優化
Transwarp Inceptor研發了一套完整的SQL編譯器,包括HiveQL解析器、SQL標準解析器和PL/SQL解析器,將不同的SQL語言解析成中間級表示語言,然后經過優化器轉換成物理執行計劃。SQL語言解析后經過邏輯優化器生成中間級表示語言,而中間表示語言再經過物理優化器生成最終的物理執行計劃。從架構上分,邏輯優化器和物理優化器都包含基于規則的優化模塊和基于成本的優化模塊。
為了和Hadoop生態更好的兼容,Inceptor為一個SQL查詢生成Map Reduce上的執行計劃和Spark上的執行計劃,并且可以通過一個SET命令在兩種執行引擎之間切換。
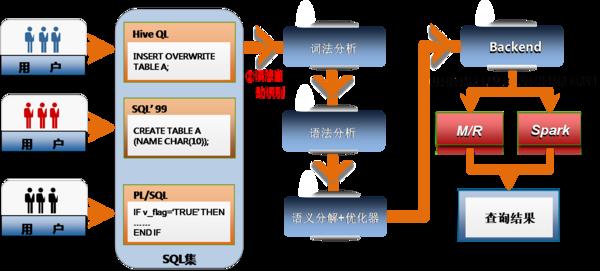
圖2:SQL編譯框架
3.1 SQL編譯與解析
Transwarp Inceptor的SQL編譯器會根據輸入的SQL查詢的類型來自動選擇不同的解析器,如PL/SQL存儲過程會自動進入PL/SQL解析器并生成一個Spark RDD的DAG從而在Spark平臺上并行計算,標準SQL查詢會進入SQL標準解析器生成Spark或Map Reduce執行計劃。由于HiveQL和標準的SQL有所出入,為了兼容HiveQL,Transwarp Inceptor保留了HiveQL解析器,并可以對非標準SQL的Hive查詢生成Spark或者Map Reduce執行計劃。
3.1.1 SQL 標準解析器
Transwarp Inceptor構建了自主研發的SQL標準解析器,用于解析SQL 99 & SQL 2003查詢并生成Spark和Map Reduce的執行計劃。詞法和語法分析層基于Antlr語法來構建詞法范式,通過Antlr來生成抽象語義樹,并會通過一些上下文的語義來消除沖突并生成正確的抽象語義樹。語義分析層解析上層生成的抽象語義樹,根據上下文來生成邏輯執行計劃并傳遞給優化器。首先Transwarp Inceptor會將SQL解析成TABLE SCAN、SELECT、FILTER、JOIN、UNION、ORDER BY、GROUP BY等主要的邏輯塊,接著會根據一些Meta信息進一步細化各個邏輯塊的執行計劃。如TABLE SCAN會分成塊讀取、塊過濾、行級別過濾、序列化等多個執行計劃。
3.1.2 PL/SQL 解析器
PL/SQL是Oracle對SQL語言的模塊化擴展,已經在很多行業中有大規模的應用,是數據倉庫領域的重要編程語言。
為了讓存儲過程在Spark上有較好的性能,PL/SQL解析器會根據存儲過程中的上下文關系來生成SQL DAG,然后對各SQL的執行計劃生成的RDD進行二次編譯,通過物理優化器將一些沒有依賴關系的RDD進行合并從而生成一個最終的RDD DAG。因此,一個存儲過程被解析成一個大的DAG,從而stage之間可以大量并發執行,避免了多次執行SQL的啟動開銷并保證了系統的并發性能。
解析并生成SQL級別的執行計劃

解析SQL的依賴關系并生成DAG, 再根據各個SQL的執行計劃來生成最終存儲過程的Spark RDD DAG
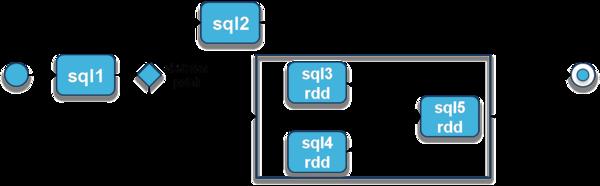
3.2 SQL優化器
Transwarp Inceptor使用Spark作為默認計算引擎,并且開發了完善的SQL優化器,因此在大量的客戶案例性能測試中,Transwarp Inceptor的性能領先Map Reduce 10-100倍,并超越部分開源MPP數據庫。SQL優化器對平臺性能的提升居功至偉。
3.2.1 基于規則的優化器(Rule Based Optimizer)
目前為止,Transwarp Inceptor共實現了一百多個優化規則,并且在持續的添加新的規則。按照功能劃分,這些規則主要分布在如下幾個模塊:
文件讀取時過濾
在文件讀取時過濾數據能夠***化的減少參與計算的數據量從而最為有效的提高性能,因此Transwarp Inceptor提供了多個規則用于生成表的過濾條件。對于一些SQL中的顯示條件,Transwarp Inceptor會盡量將過濾前推到讀取表中;而對于一些隱式的過濾條件,如可以根據join key生成的過濾規則,Inceptor會根據語義保證正確性的前提下進行規則生成。
過濾條件前置
Transwarp Inceptor能夠從復雜的組合過濾條件中篩選出針對特定表的過濾規則,然后通過SQL語義來確定是否能將過濾條件前推到盡量早的時候執行。如果有子查詢,過濾條件可以遞歸前推入***層的子查詢中,從而保證所有的冗余數據被刪除。
超寬表的讀取過濾
對一些列超多的表進行處理的時候,Transwarp Inceptor首先會根據SQL語義來確定要讀取的列,并在讀取表的時候進行跨列讀取減少IO和內存消耗。而如果表有過濾條件,Inceptor會做進一步優化,首先只讀取過濾條件相關的列來確定該行記錄是否需要被選擇,如果不是就跳過當前行的所有列,因此能夠***程度上的減少數據讀取。在一些商業實施中,這些優化規則能夠帶來5x - 10x的性能提升。
Shuffle Stage的優化與消除
Spark的shuffle實現的效率非常低,需要把結果寫磁盤,然后通過HTTP傳輸。Transwarp Inceptor添加了一些shuffle消除的優化規則,對SQL的DAG中不必要或者是可以合并的shuffle stage進行消除或者合并。對于必須要做Shuffle的計算任務,Inceptor通過DAGScheduler來提高shuffle的效率:Map Task會直接將結果返回給DAGScheduler,然后DAGScheduler將結果直接交給Reduce Task而不是等待所有Map Task結束,這樣能夠非常明顯的提升shuffle階段的性能。
Partition消除
Transwarp Inceptor提供單一值Partition和Range Partition,并且支持對Partition建Bucket來做多次分區。當Partition過多的時候,系統的性能會因為內存消耗和調度開銷而損失。因此,Inceptor提供了多個規則用于消除不必要的Partition,如果上下文中有隱式的對Partition的過濾條件,Inceptor也會生成對partition的過濾規則。
3.2.2 基于成本的優化器(Cost Based Optimizer)
基于規則的優化器都是根據一些靜態的信息來產生的,因此很多和動態數據相關的特性是不能通過基于規則的優化來解決,因此Transwarp Inceptor提供了基于成本的優化器來做二次優化。相關的原始數據主要來自Meta-store中的表統計信息、RDD的信息、SQL上下文中的統計信息等。依賴于這些動態的數據,CBO會計算執行計劃的物理成本并選擇最有效的執行計劃。一些非常有效的優化規則包括如下幾點:
JOIN順序調優
在實際的案例中,join是消耗計算量最多的業務,因此對join的優化至關重要。在多表JOIN模型中,Transwarp Inceptor會根據統計信息來預估join的中間結果大小,并選擇產生中間數據量最小的join順序作為執行計劃。
JOIN類型的選擇
Transwarp Inceptor支持Left-most Join Tree 和 Bush Join Tree,并且會根據統計信息來選擇生成哪種Join模型有***性能。此外,Transwarp Inceptor會根據原始表或者中間數據的大小來選擇是否開啟針對數據傾斜模型下的特殊優化等。此外,針對HBase表是否有索引的情況,Transwarp Inceptor會在普通Join和Look-up Join間做個均衡的選擇。
并發度的控制
Spark通過線程級并發來提高性能,但是大量的并發可能會帶來不必要的調度開銷,因此不同的案例在不同并發度下會有***性能。Transwarp Inceptor通過對RDD的一些屬性進行推算來選擇***并發控制,對很多的案例有著2x-3x的性能提升。
4.Transwarp Holodesk內存計算引擎
為了有效的降低SQL分析的延時,減少磁盤IO對系統性能的影響,星環科技研發了基于內存或者SSD的存儲計算引擎Transwarp Holodesk,通過將表數據直接建在內存或者SSD上以實現SQL查詢全內存計算。另外Transwarp Holodesk增加了數據索引功能,支持對多個數據列建索引,從而更大程度的降低了SQL查詢延時。
4.1 存儲格式
Transwarp Holodesk基于列式存儲做了大量的原創性改進帶來更高的性能和更低的數據膨脹率。首先數據被序列化后存儲到內存或SSD上以節省者資源占用。如圖3所示,每個表的數據被存儲成若干個Segment,每個Segment被劃分成若干個Block,每個Block按照列方式存儲于SSD或內存中。另外每個Block的頭部都加上Min-Max Filter和Bloom Filter用于過濾無用的數據塊,減少不必要的數據進入計算階段。
Transwarp Holodesk根據查詢條件的謂詞屬性對每個數據塊的對應列構建數據索引,索引列采用自己研發的Trie結構進行組織存儲,非索引列采用字典編碼的方式進行組織存儲。Trie不僅能對具有公共前綴的字符串進行壓縮,而且可以對輸入的字符串排序,從而可以利用二分查找快速查詢所需數據的位置,從而快速響應查詢需求。
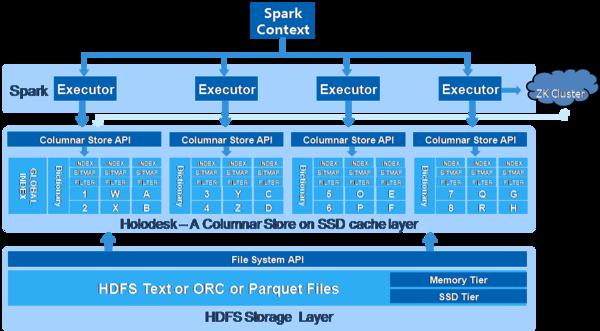
圖3:Holodesk存儲格式
HDFS 2.6支持Storage Tier讓應用程序可以選擇存儲層為磁盤或者SSD,但是沒有專用的存儲格式設計是無法有效利用SSD的讀寫吞吐量和低延,因此現有的Text以及行列混合(ORC/Parquet)都不能有效的利用SSD的高性能。為此驗證存儲結構對性能的影響,我們將HDFS構建在SSD上并選用某基準測試來做了進一步的性能對比,結果如圖4所示:采用文本格式,PCI-E SSD帶來的性能提升僅1.5倍;采用專為內存和SSD設計的Holodesk列式存儲,其性能相比較SSD上的HDFS提升高達6倍。

圖4:SSD上Holodesk對HDFS的性能加速比
4.2 性能優勢
某運營商客戶在12臺x86服務器上搭建了Transwarp Inceptor,將Transwarp Holodesk 配置在PCIE-SSD上,并與普通磁盤表以及DB2來做性能對比測試。最終測試數據如圖5所示:
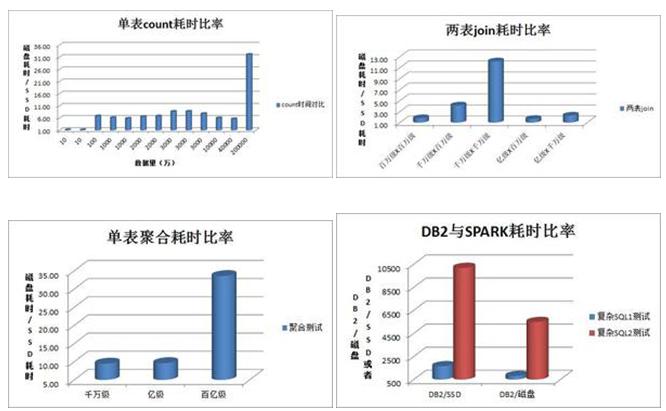
圖5:某運營商Holodesk性能測試結果
在純粹的count測試一項,Holodesk性能相對于磁盤表***領先32倍;對于join測試一項,Transwarp Holodesk***領先磁盤表多達12倍;在單表聚合測試中,Holodesk提升倍數達10~30倍。另外Transwarp Holodesk在和DB2的對比中也表現優秀,兩個復雜SQL查詢在DB2數據庫中需要運行1小時以上,但是在使用Transwarp Holodesk均是分鐘級和秒級就返回結果。
內存的價格大約是同樣容量SSD的十倍左右,為了給企業提供更高性價比的計算方案,Transwarp Holodesk針對SSD進行了大量的優化,使得應用在SSD上運行具有與在內存上比較接近的性能,從而為客戶提供了性價比更高的計算平臺。
在對TPC-DS的IO密集型查詢的測試中,無論上構建在PCI-E SSD還是內存上,Holodesk對比磁盤表有一個數量級上的性能提升;而SSD上的Holodesk性能只比內存差10%左右。

圖6:數據在磁盤、SSD和內存中的性能表現
5. 穩定的Spark執行引擎
企業目前應用開源Spark的主要困難在穩定性、可管理性和功能不夠豐富上。開源Spark在穩定性上還有比較多的問題,在處理大數據量時可能無法運行結束或出現Out of memory,性能時快時慢,有時比Map/Reduce更慢,無法應用到復雜數據分析業務中。
Transwarp Inceptor針對各種出錯場景設計了多種解決方法,如通過基于成本的優化器選擇最合適的執行計劃、加強對數據結構內存使用效率的有效管理、對常見的內存出錯問題通過磁盤進行數據備份等方式,極大提高了Spark功能和性能的穩定性,上述問題都已經解決并經過商業案例的考驗。Transwarp Inceptor能穩定的運行7*24小時,并能在TB級規模數據上高效進行各種穩定的統計分析。
6. SQL引擎效能驗證
TPC-DS是TPC組織為Decision Support System設計的一個測試集,包含對大數據集的統計/報表生成/聯機查詢/數據挖掘等復雜應用,測試用的數據有各種不同的分布與傾斜,與真實場景非常接近。隨著國內外各代表性的Hadoop發行版廠商以TPC-DS為標準測評產品,TPC-DS也就逐漸成為了業界公認的Hadoop系統測試準則。
6.1 驗證對比的平臺和配置
我們搭建了兩個集群分別用于Transwarp Inceptor與Cloudera Data Hub/Impala的測試。每個集群采用4臺普通兩路x86服務器搭建,每臺服務器硬件配置如下:
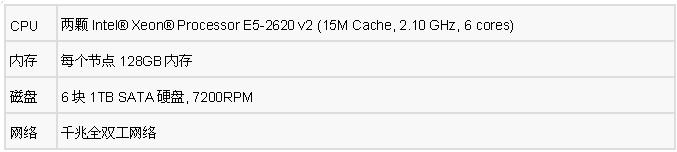
考慮到磁盤的容量和HDFS的存儲復制模式,我們選擇的是500GB的數據總量。SQL測試案例的選擇上,在Cloudera Impala中使用的是由Cloudera改動過的TPC-DS測試子集,在Transwarp Inceptor我們選用的是TPC-DS為Oracle生成的測試集合,保留了原有的各種復雜SQL,因此能夠客觀反映出Inceptor在SQL支持上的情況。

6.2 Transwarp Inceptor VS Cloudera Impala
Transwarp Inceptor由于有完善的SQL支持,能夠運行全部所有的99個SQL查詢。而由于Cloudera官方發布的TPC-DS測試集只包含19個SQL案例,因此我們只能運行這19個SQL,實驗證明這部分查詢在Impala上全部正常運行完成。
圖7是所有的測試集合的性能對比圖。圖中縱坐標小于1表述測試案例中Cloudera Impala性能超過Transwarp Inceptor,而大于1則表示Transwarp Inceptor有更好的性能表現。對于Cloudera Impala不能支持的SQL,我們就標記這個性能比為100。從圖中可見,在Cloudera Impala支持的19個SQL中,有8個SQL的表現超過Transwarp Inceptor,2個表現相當,另外9個Transwarp Inceptor比Cloudera Impala表現的更好。
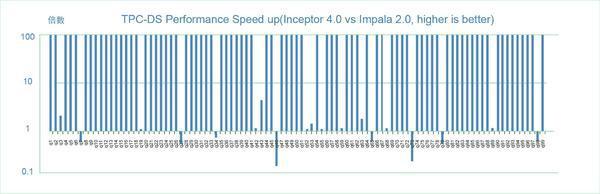
圖7:Transwarp Inceptor與Cloudera Impala的性能比較
6.3 Transwarp Inceptor VS Map Reduce
我們使用了同樣的硬件和軟件配置完成和開源的Hive執行效率相比,Transwarp Inceptor能夠帶來10x-100x的性能提升。圖8是TPC-DS的部分SQL查詢在Inceptor和CDH 5.1 Hive的性能提升倍數,其中***的提升倍數竟可達到123倍。

圖8:Transwarp Inceptor與開源Hive的性能比較
7. 結語
隨著在大數據領域國內外開始處于同一起跑線,我們相信像星環科技這樣國內具有代表性的Hadoop發行版廠商將在中國的廣闊市場空間中獲得長足發展,并且由于中國市場激烈的競爭與磨練,逐步打磨出超越國外先進廠商的技術與實力。
劉汪根。2013年加入星環,作為早期員工參與了星環大數據平臺的構建,現擔任數據平臺部研發經理,主要負責與管理星環大數據平臺數據平臺的研發工作,如SQL編譯器,Spark執行引擎等工作,產品涵括Transwarp Inceptor/Transwarp Stream等軟件。
【編者按】星環科技從2013年6月開始研發基于Spark的SQL執行引擎,在2013年底推出Transwarp Inceptor 1.0,并落地了國內***7x24小時的商用項目。經過1年多的持續創新與改進,星環已經在國內落地了數十個Inceptor的商用項目。這是一篇星環Spark解決方案的技術解析,也是Spark用戶可以效仿的優化之道。













