













基因突變研究,釋放PB級大數據的能量
15年前,人們視其為里程碑式但高不可攀的成就;10年前,這是一個有趣但是昂貴的研究工具;現在,日漸低廉的價格,迅猛提升的精確度以及正在穩定進步基礎科學體系將基因組測序帶入常規臨床護理的實踐前沿。
越來越多的機構正在開展基因組研究以鑒別出導致稀有疾病的基因突變。“我們正在尋找的基因突變的發生概率正在提高”,Russ Altman說道,他是斯坦福醫藥學院的一名生物信息教授。“在一些醫療中心,百分之50的案例都是我們研究的這些病種”。
越來越多的機構正在開展基因組研究以鑒別出導致稀有疾病的基因突變。“我們正在尋找的“基因突變”,它發生概率正在提高”,Russ Altman說道,他是斯坦福醫藥學院的一名生物信息教授。“在一些醫療中心,百分之50的案例都是我們研究的這些病種”。基因突變可以揭露誘發這些疾病 的原因以及腫瘤治療的漏洞,以及提供合理的關于一個病人個體是否會對某種藥品的反應程度-也就是我們說的遺傳藥理學。
僅僅需要1000美元的基因組測序,這個價格點,是科學家們設想的能夠應用到實踐中的價格閾值,現如今已經達到。 “我們的性價比在科學史上是絕無僅有的,在此前幾年幾乎只有6個訂單。”Paul Flicek說道,他是一位計算基因組學的專家,現供職于英國劍橋郡的歐洲分子生物學實驗室歐洲生物信息學研究所。如今San Diego等人領導的HiSeq X Ten基因測序系統,每年可以為超過18000人提供基因測序服務。
生物醫藥研究社區正在竭盡全力探索基因組分析的臨床能力。就在2014年,英國開展了“100,000基因組項目”,同時美國和中國已經有公開計劃——致力于分析超過100萬個個體的基因組。
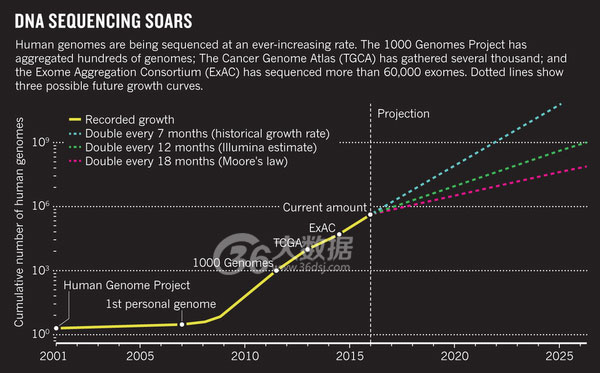
Stephens, Z. D. et al. PLoS Biol.13, e1002195 (2015)/CC by 4.0 http://creativecommons.org/licenses/by/4.0
盡管許多項目都關注于該領域中不同的部分,但它們都不約而同地將眼光放到了“大數據”上。例如,位于賓夕法尼亞州丹維爾市的Geisinger健康 系統和位于紐約的Regeneron制藥生物技術公司的一個合作項目,就致力于研究超過250,000個個體的基因序列。同時,世界范圍上的許多醫院和醫 療服務中心正在分析患有癌癥或者稀有疾病的患者的基因組
一些研究者提出了這樣的擔憂:這樣的數據洪流,其分析以及對于存儲空間的極大要求,會對計算機能力造成極大挑戰。一篇文章指出,基因組分析生成的大 數據,會讓諸如YouTube這樣的數據巨獸都自認侏儒。許多人也擔憂目前的大數據并沒有足夠分析能力去提供臨床知識。“我不知道百萬級別的基因組數目是 否足夠臨床應用,但是我清晰地知道,我們得到的數據越多,效果越好。”Marc Williams說道,他是Geisinger生物制藥公司的領導者。
基因突變的意義
現如今的臨床基因組檢測著力關注于鑒別個體的單核苷酸變異(基因中的可以造成基因破壞的最小單位)。相對于檢測全部基因組,許多研究中心著力于外顯 子組-基因組中負責蛋白質編譯的子集。這種分析思路將需要分析的數據量降低到了原來的百分之一,但是平均下來,外顯子組還是包含了超過13,000個單核 苷酸,其中,大約2%被認為能夠影響蛋白質的編碼組合,因此找到導致某種疾病的單核苷酸變異仍然是一個巨大挑戰。
幾十年來,生物醫學研究人員盡職盡責地沉浸在他們對于單核苷酸變異的新發現,這些發現大多來自公共數據庫,例如人類基因突變數據庫,由醫學遺傳研究 所的英國卡迪夫大學運營,又例如dbSNP數據庫,其由美國國家生物技術中心維護。然而,這些突變的影響往往是從細胞培養物或動物模型中,或者理論預測確 定的,對于臨床診斷工具來說,它未能提供足夠的指導。 “在許多情況下,協會分別與證據相對較低的水平制造的,”威廉姆斯說。
幾十年來,生物醫藥研究者們盡職盡責地投入在對于公共資源數據中的單核苷酸變異的發掘中,這些公共資源包括Human Gene Mutation Database(人類基因突變數據庫),現在是卡蒂夫大學醫學遺傳學研究所在運營著,又例如dbSNP數據庫,由美國國家生物技術信息中心負責其維護工 作。然而,這些突變帶來的生物學影響,通常是由細胞培養物或者動物模型所決定的,甚至是理論預測的,這些指導是不足以使用在臨床應用上的。“在許多案例 中,支持這種關聯(疾病與基因突變的關聯)的證據仍然不足”。
“You’re shooting yourself in the foot if you’re collecting data you don’t know how to interpret.”
”如果你不知道如何解釋你收集而來的數據,那么這無異于用槍指著自己的腳然后按動扳機。“
對于結構性的變異來說,情況將會更加復雜。例如,成塊重復或者成塊缺失的基因組,相比起單個核苷酸的突變,是更加難以檢測的。在完全基因組序列中,每個人 都可能有上百萬個基因突變,盡管它們中的大部分都不負責編譯蛋白質,但它們多多少少有參與到普通的基因行為中,所以它們仍然可以導致疾病。然而,我們對于 這些基因的特性以及功能,知之甚少。盡管我們感覺到了了解這些突變的緊迫性,但在臨床應用上,它不能給我們最好的短期回報。
You’re shooting yourself in the foot if you’re collecting data you don’t know how to interpret,”
如果你不知道如何解釋你收集而來的數據,那么這無異于用槍指著自己的腳然后按動扳機。Altman說道。
人們已經做出了一些努力去糾正以上這個問題。由美國國家人類基因組研究所
設立的臨床基因組資源,是一個描述“疾病-變異”關系的數據庫,它包含了藥物對某些變異的病理反應以及支持這種關聯的證據。Genomics England(一個組織),運營著“100,000基因組項目”,設立了“臨床解釋伙伴”,旨在推動這個領域的進步,我們可以看到,醫生和研究者會通力 合作來構建健壯的模型以建立疾病與特定基因變異之間的關系。
然而,數量和質量一樣重要。能帶來巨大影響的基因突變通常是有害的,因此它們會十分稀少以及需要大量的的病理樣本以分析。建立有統計意義的“疾病-變異”關聯,尤其是對于影響效果比較不明顯的這種關聯,也需要大量的人類個體數據。
在冰島,deCODE Genetics(一個組織)調研了超過150,000個個體的家譜以及病理歷史記錄,結合15,000份全基因組序列,其調研結果已經向人們展示了基于 大規模人類個體的基因組學的力量。這些發現使得deCODE能夠推斷地區人口級別的疾病風險因素,包括與乳腺癌,糖尿病和阿爾茨海默氏病有關的基因變異。
他們也允許一些往日只能在創造轉基因動物上才能做的研究。“我們已經建立了10000名患有功能性缺失的冰島人的基因數據”。Kari Stefansson說道,他是該公司的首席執行官。“我們正在投入巨大資源以研究某些基因的敲除對這些個體的影響”。
這些工作的成功,很大程度上得益于冰島人口基因型的同質性,但其他項目需要更為廣泛的基因頻譜。一些工作例如國際千人基因組計劃已經編錄了一些世界范圍的多樣化基因,但絕大部分數據仍然偏向于高加索人群,這使得其對于臨床醫學用處不大。“因為它們都來自與一個基因組祖先,可以這么說,非洲祖先攜帶的基因變異比非非洲祖先多。”Isaac Kohane說道,他是位于馬薩諸塞州波士頓的哈佛藥學院的生物信息學家。“在高加索人種上稀有的基因突變,在非洲人種身上可能是很常見的,而且還可能不會造成任何疾病”。
部分問題源于參考基因組,也就是準繩基因序列,科學家們通過它來確認異常基因,該序列由multinational Genome Reference Consortium維護。其首個版本是由世界各地的多個種族的隨機捐贈者拼湊而成,但最新的版本,我們稱為GRCh38,結合了更多的關于人種基因多樣 性的信息。
置身于云
在人口規模上收集基因組乃至于外顯子組將會產生極其巨大的數據量,每年可能高達40PB。盡管如此,原始數據的存儲并不是主要的計算問題。“基因組學家只是普通人群中對硬盤容量有更大需求的一群人。”Flicek說道,“我不認為存儲會是一個關鍵的問題”。
人們更為關注的是如此巨量的數據將如何被分析研究。“計算需求和人口數是線性相關的”,Marylyn Ritchie說道,他是賓夕法尼亞州立大學的基因組學家。“但當你加入了更多變量,關注更多的組合可能的時候,其對計算能力的要求就成指數相關。”如果 有相關的臨床癥狀或者額外的基因數據(更多變量),那么分析就會變得尤為困難。處理如此數以千計的個體基因數據可以徹底癱瘓實驗室中的統計分析工具。
擴大數據規模需要我們在思路上進行創新,但是我們也沒有必要從零開始。“像氣象,金融和天文學領域都已經在整合各種數據這條路上走了很 久。”Ritchie說道,“我和Google以及FaceBook的人們交流過,我們的大數據,盡管和他們的大數據有不同之處,但我們應該和他們交流, 找出他們是如何做的,并且將其合適的方法整合到我們的領域中。
不幸的是,許多才華橫溢,具有大數據開發經驗的程序員都被硅谷企業所吸引。Philip Bourne,現任美國國家衛生研究院的數據科學副主任,他認為,造成這種情況的一部分原因是,對于這么一個公共資源推動的科學項目,人們還缺乏認知上的 提升和重視,從而使得該領域許多軟件開發員和數據經營者仍然處于寒冬之中。”例如,這群人中的一部分希望能夠成為一名學者,但是他們不能得到教師的地位, 這是不合理的。”
計算機的處理能力是另外一個關鍵因素。“這不是一個桌面游戲——真正的從業者都精通基于成百上千個CPU以及大內存的大規模并行計算。Kohane 說道,許多分析大規模數據的研究組都正在轉向基于云計算的架構,其中數據被放置于一個巨大的數據池中并供給任何一個有需要的計算單元進行分析。
人們漸漸地產生了這種想法:你將你的算法帶到數據中去。Tim Hubbard說道,這是Genomics England組織的首席生物信息學家。對于Genomics England組織來說,它們的架構被放置在一個安全的政府設施中,嚴格控制外部訪問。而其他小組則漸漸轉向了商用云系統,例如Amazon或者 Google提供的云服務。
隱私保護
原則上,基于云計算的托管服務可以鼓勵數據集共享和協作. 但患者的知情同意權以及隱私權利會因為這高度敏感的臨床信息而變得棘手和敏感,同時伴隨著倫理和法律問題。
在歐盟,具有不同法律條令的成員國更是成為這種合作的阻礙。除此之外,與非歐盟國家的共享還依賴于笨重的體制以建立安全的數據保護,或者是個別組織之間限 制性雙邊協議的完備性。為了解決這個問題,一個跨國組織——全球基因組學與健康聯盟,制定了有關基因組責任分擔以及健康方面數據資源的框架,其包括了隱私 權和知情同意權的指導方針,同樣也框定了成員責任以及違規行為的法律后果。
技術上的高速發展正在改變基因組學研究。
在數據傳輸協議上,“在出資人同意的前提下,你可以保存自己的數據以及獲取的結果規則頁面”。Bartha Knoppers說道,他是蒙特利爾麥克吉爾大學的生物倫理學家,主管聯盟監督工作以及倫理工作組。該框架還要求“安全區域”,即在去除個人數據保證了隱 私安全的同時,也保留其數據的可研究能力,在此前提下,允許研究機構獲取并分析中央數據倉庫的信息數據。“我們還希望把它鏈接到臨床數據和醫療記錄,若不 這樣做,我們永遠也得不到精密醫學診斷。
對許多歐洲國家來說,將基因組信息整合為電子健康信息正變得越發重要。“我們的目標是將這個作為標準的國家健康服務”Hubbard說道。英國的 “100000基因組項目”將在這條路上前進,但同時其他國家正在緊追不舍。例如,比利時最近就公布了一項計劃,以探索醫學基因組學等。
所有國家受益于集中式的,政府運營的健康中心。在美國,情況就比較分散,不同的健康服務中心依賴于不同的健康信息系統,由不同的信息供應商提供,這些數據,往往不是設計來處理復雜的基因組的。而在這方面,美國國立衛生研究院的電子醫療記錄和基因組學網絡設立了一個標桿。
從數據到診斷
當前,我們收集并維護這些豐富的基因組信息,是為了解釋基因突變對于個體生理健康的影響,而這其中,最早實現的是病理學。臨床藥理學聯盟已經將藥物 -基因關聯(來自PharmGKB數據庫)投入實施并用于臨床使用。例如,帶有某種基因突變的個體將會對特定的抗凝劑產生很差的反應效果,從而導致心臟病 發作的的可能性增加。“問題在于,我們如何讓一名忙碌到只有12分鐘來診斷一位病人并且用45秒以對癥下藥的醫生,采納我們這種更加有意義的做法?”
將健康護理與基因發現更好地結合起來,仍然是人類面對的一個問題,完成這個過程需要我們投入更多的時間和精力。從研究的角度看,結合基因型與表現型信息給 我們帶來累累碩果。大部分疾病相關基因變異是通過全基因組關聯研究而鑒別得來的,在這個研究過程中,大量的患有某種疾病的個體參與了我們的檢測,以確定遺 傳特征識別。研究人員現在可以從健康記錄反向工作,以確定什么臨床表現是與給定的基因變異密切相關的。
基因組只是故事的一部分,其他“組”也有作為健康晴雨表的可能性。今年七月,Jun Wang辭去了他BGI主席的工作,創辦了一個機構,致力于分析BGI的百萬人群計劃的基因組信息,其中包括蛋白質組,轉錄組以及代謝組等等。“我將設立 一個全新的機構,使用人工智能來探索這個領域的大數據。他說道。
來日方長
隨著研究人員努力整合來自健康檔案、基因組和其他生理數據的臨床試驗數據,患者本身也可以作出貢獻。“當我們專注于病人的日常行為,包括營養,運動,吸煙和飲酒等,沒有比這更好的數據了”里奇說道。
可穿戴設備,如智能手機和FitBits,正在收集有關運動與心臟速率數據,而這樣的數據量不斷攀升,因為收集這種數據不費吹灰之力。
每個患者都可能成為一個大數據生產者。“我們在家里或者公共場所收集的數據將會大大超過我們所積累的臨床數據。Kohane說道。”我們正在努力收 集不同數據模式的這些大模塊——從基因組到臨床醫學環境——然后將其鏈接到具體的病人身上。“隨著這些進展具體化,他們可以利用碎片化的計算方式,使得今 日我們的大數據計算就像袖珍計算機問題一樣。隨著科學家想方設法碎片化數據,病人們將是最終的獲益者。
原文標題:Big data: The power of petabytes














