













已經證實提高機器學習模型準確率的八大方法
導語
提升一個模型的表現有時很困難。如果你們曾經糾結于相似的問題,那我相信你們中很多人會同意我的看法。你會嘗試所有曾學習過的策略和算法,但模型正確率并沒有改善。你會覺得無助和困頓,這是 90% 的數據科學家開始放棄的時候。

不過,這才是考驗真本領的時候!這也是普通的數據科學家跟大師級數據科學家的差距所在。你是否曾經夢想過成為大師級的數據科學家呢?
如果是的話,你需要這 8 個經過證實的方法來重構你的模型。建立預測模型的方法不止一種。這里沒有金科玉律。但是,如果你遵循我的方法(見下文),(在提供的數據足以用來做預測的前提下)你的模型會擁有較高的準確率。
我從實踐中學習了到這些方法。相對于理論,我一向更熱衷于實踐。這種學習方式也一直在激勵我。本文將分享 8 個經過證實的方法,使用這些方法可以建立穩健的機器學習模型。希望我的知識可以幫助大家獲得更高的職業成就。
正文
模型的開發周期有多個不同的階段,從數據收集開始直到模型建立。
不過,在通過探索數據來理解(變量的)關系之前,建議進行假設生成(hypothesis generation)步驟(如果想了解更多有關假設生成的內容,推薦閱讀 why-and-when-is-hypothesis-generation-important )。我認為,這是預測建模過程中最被低估的一個步驟。
花時間思考要回答的問題以及獲取領域知識也很重要。這有什么幫助呢?它會幫助你隨后建立更好的特征集,不被當前的數據集誤導。這是改善模型正確率的一個重要環節。
在這個階段,你應該對問題進行結構化思考,即進行一個把此問題相關的所有可能的方面納入考慮范圍的思考過程。
現在讓我們挖掘得更深入一些。讓我們看看這些已被證實的,用于改善模型準確率的方法。
1. 增加更多數據
持有更多的數據永遠是個好主意。相比于去依賴假設和弱相關,更多的數據允許數據進行“自我表達”。數據越多,模型越好,正確率越高。
我明白,有時無法獲得更多數據。比如,在數據科學競賽中,訓練集的數據量是無法增加的。但對于企業項目,我建議,如果可能的話,去索取更多數據。這會減少由于數據集規模有限帶來的痛苦。
2. 處理缺失值和異常值
訓練集中缺失值與異常值的意外出現,往往會導致模型正確率低或有偏差。這會導致錯誤的預測。這是由于我們沒能正確分析目標行為以及與其他變量的關系。所以處理好缺失值和異常值很重要。
仔細看下面一幅截圖。在存在缺失值的情況下,男性和女性玩板球的概率相同。但如果看第二張表(缺失值根據稱呼“Miss”被填補以后),相對于男性,女性玩板球的概率更高。

左側:缺失值處理前;右側:缺失值處理后
從上面的例子中,我們可以看出缺失值對于模型準確率的不利影響。所幸,我們有各種方法可以應對缺失值和異常值:
缺失值:對于連續變量,可以把缺失值替換成平均值、中位數、眾數。對于分類變量,可以把變量作為一個特殊類別看待。你也可以建立模型預測缺失值。KNN 為處理缺失值提供了很好的方法。想了解更多這方面內容,推薦閱讀《Methods to deal and treat missing values》。
異常值:你可以刪除這些條目,進行轉換,分箱。如同缺失值,你也可以對異常值進行區別對待。想了解更多這方面內容,推薦閱讀《How to detect Outliers in your dataset and treat them?》。
3. 特征工程學
這一步驟有助于從現有數據中提取更多信息。新信息作為新特征被提取出來。這些特征可能會更好地解釋訓練集中的差異變化。因此能改善模型的準確率。
假設生成對特征工程影響很大。好的假設能帶來更好的特征集。這也是我一直建議在假設生成上花時間的原因。特征工程能被分為兩個步驟:
特征轉換:許多場景需要進行特征轉換:
A) 把變量的范圍從原始范圍變為從 0 到 1 。這通常被稱作數據標準化。比如,某個數據集中***個變量以米計算,第二個變量是厘米,第三個是千米,在這種情況下,在使用任何算法之前,必須把數據標準化為相同范圍。
B) 有些算法對于正態分布的數據表現更好。所以我們需要去掉變量的偏向。對數,平方根,倒數等方法可用來修正偏斜。
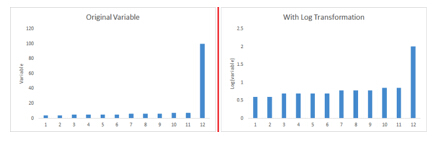
C) 有些時候,數值型的數據在分箱后表現更好,因為這同時也處理了異常值。數值型數據可以通過把數值分組為箱變得離散。這也被稱為數據離散化。
創建新特征:從現有的變量中衍生出新變量被稱為特征創建。這有助于釋放出數據集中潛藏的關系。比如,我們想通過某家商店的交易日期預測其交易量。在這個問題上日期可能和交易量關系不大,但如果研究這天是星期幾,可能會有更高的相關。在這個例子中,某個日期是星期幾的信息是潛在的。我們可以把這個信息提取為新特征,優化模型。
4. 特征選擇
特征選擇是尋找眾多屬性的哪個子集合,能夠***的解釋目標變量與各個自變量的關系的過程。
你可以根據多種標準選取有用的特征,例如:
所在領域知識:根據在此領域的經驗,可以選出對目標變量有更大影響的變量。
可視化:正如這名字所示,可視化讓變量間的關系可以被看見,使特征選擇的過程更輕松。
統計參數:我們可以考慮 p 值,信息價值(information values)和其他統計參數來選擇正確的參數。
PCA:這種方法有助于在低維空間表現訓練集數據。這是一種降維技術。 降低數據集維度還有許多方法:如因子分析、低方差、高相關、前向后向變量選擇及其他。
5. 使用多種算法
使用正確的機器學習算法是獲得更高準確率的理想方法。但是說起來容易做起來難。
這種直覺來自于經驗和不斷嘗試。有些算法比其他算法更適合特定類型數據。因此,我們應該使用所有有關的模型,并檢測其表現。
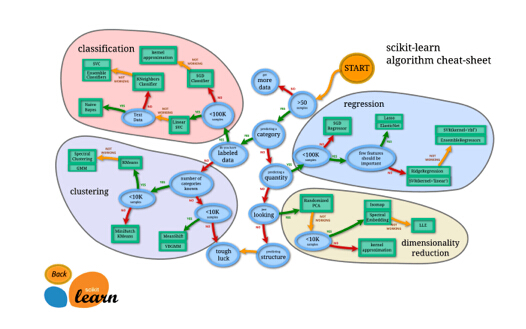
來源:Scikit-Learn 算法選擇圖
6. 算法的調整
我們都知道機器學習算法是由參數驅動的。這些參數對學習的結果有明顯影響。參數調整的目的是為每個參數尋找***值,以改善模型正確率。要調整這些參數,你必須對它們的意義和各自的影響有所了解。你可以在一些表現良好的模型上重復這個過程。
例如,在隨機森林中,我們有 max_features, number_trees, random_state, oob_score 以及其他參數。優化這些參數值會帶來更好更準確的模型。
想要詳細了解調整參數帶來的影響,可以查閱《Tuning the parameters of your Random Forest model》。下面是隨機森林算法在scikit learn中的全部參數清單:
RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False,class_weight=None)
7. 集成模型
在數據科學競賽獲勝方案中最常見的方法。這個技術就是把多個弱模型的結果組合在一起,獲得更好的結果。它能通過許多方式實現,如:
- Bagging (Bootstrap Aggregating)
- Boosting
想了解更多這方面內容,可以查閱《Introduction to ensemble learning》。
使用集成方法改進模型正確率永遠是個好主意。主要有兩個原因:
- 集成方法通常比傳統方法更復雜;
- 傳統方法提供好的基礎,在此基礎上可以建立集成方法。
注意!
到目前為止,我們了解了改善模型準確率的方法。但是,高準確率的模型不一定(在未知數據上)有更好的表現。有時,模型準確率的改善是由于過度擬合。
8. 交叉驗證
如果想解決這個問題,我們必須使用交叉驗證技術(cross validation)。交叉驗證是數據建模領域最重要的概念之一。它是指,保留一部分數據樣本不用來訓練模型,而是在完成模型前用來驗證。

這種方法有助于得出更有概括性的關系。想了解更多有關交叉檢驗的內容,建議查閱《Improve model performance using cross validation》。



















