如何設計一個復雜的分布式爬蟲系統?
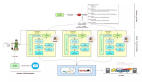
一個復雜的分布式爬蟲系統由很多的模塊組成,每個模塊是一個獨立的服務(SOA架構),所有的服務都注冊到Zookeeper來統一管理和便于線上擴展。模塊之間通過thrift(或是protobuf,或是soup,或是json,等)協議來交互和通訊。
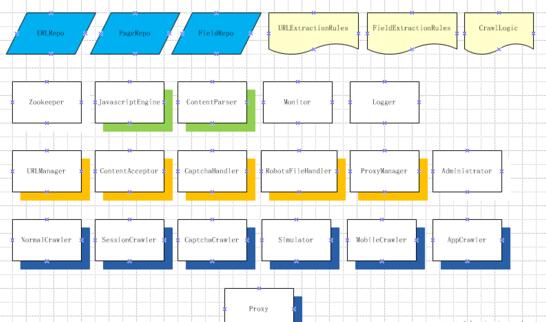
Zookeeper負責管理系統中的所有服務,簡單的配置信息的同步,同一服務的不同拷貝之間的負載均衡。它還有一個好處是可以實現服務模塊的熱插拔。
URLManager是爬蟲系統的核心。負責URL的重要性排序,分發,調度,任務分配。單個的爬蟲完成一批URL的爬取任務之后,會找 URLManager要一批新的URL。一般來說,一個爬取任務中包含幾千到一萬個URL,這些URL***是來自不同的host,這樣,不會給一個 host在很短一段時間內造成高峰值。
ContentAcceptor負責收集來自爬蟲爬到的頁面或是其它內容。爬蟲一般將爬取的一批頁面,比如,一百個頁面,壓縮打包成一個文件,發送給ContentAcceptor。ContentAcceptor收到后,解壓,存儲到分布式文件系統或是分布式數據庫,或是直接交給 ContentParser去分析。
CaptchaHandler負責處理爬蟲傳過來的captcha,通過自動的captcha識別器,或是之前識別過的captcha的緩存,或是通過人工打碼服務,等等,識別出正確的碼,回傳給爬蟲,爬蟲按照定義好的爬取邏輯去爬取。
RobotsFileHandler負責處理和分析robots.txt文件,然后緩存下來,給ContentParser和 URLManager提供禁止爬取的信息。一個行為端正的爬蟲,原則上是應該遵守robots協議。但是,現在大數據公司,為了得到更多的數據,基本上遵守這個協議的不多。robots文件的爬取,也是通過URLManager作為一種爬取類型讓分布式爬蟲去爬取的。
ProxyManager負責管理系統用到的所有Proxy,說白了,負責管理可以用來爬取的IP。爬蟲詢問ProxyManager,得到一批 Proxy IP,然后每次訪問的時候,會采用不同的IP。如果遇到IP被屏蔽,即時反饋給ProxyManager,ProxyManager會根據哪個host屏蔽了哪個IP做實時的聰明的調度。
Administor負責管理整個分布式爬蟲系統。管理者通過這個界面來配置系統,啟動和停止某個服務,刪除錯誤的結果,了解系統的運行情況,等等。
各種不同類型的爬取任務,比如,像給一個URL爬取一個頁面( NormalCrawler),像需要用戶名和密碼注冊然后才能爬取( SessionCrawler ),像爬取時先要輸入驗證碼( CaptchaCrawler ),像需要模擬用戶的行為來爬取( Simulator ),像移動頁面和內容爬取( MobileCrawler ),和像App內內容的爬取( AppCrawler),需要不同類型的爬蟲來爬取。當然,也可以開發一個通用的爬蟲,然后根據不同的類型實施不同的策略,但這樣一個程序內的代碼復雜,可擴展性和可維護性不強。
一個爬蟲內部的爬取邏輯,通過解釋從配置文件 CrawlLogic 來的命令來實現,而不是將爬取邏輯硬編碼在爬蟲程序里面。對于復雜的爬取邏輯,甚至可以通過用代碼寫的插件來實現。
ContentParser根據URLExtractionRules來抽取需要繼續爬取的URL,因為focus的爬蟲只需要爬取需要的數據,不是網站上的每個URL都需要爬取。ContentParser還會根據FieldExtractionRules來抽取感興趣的數據,然后將原始數據結構化。由于動態生成的頁面很多,很多數據是通過Javascript顯示出來的,需要JavascriptEngine來幫助分析頁面。這兒需要提及下,有些頁面大量使用AJAX來實時獲取和展示數據,那么,需要一個能解釋Javascript的爬蟲類型來處理這些有AJAX的情形。
為了監控整個系統的運行情況和性能,需要 Monitor 系統。為了調試系統,保障系統安全有據可循,需要 Logger 系統。有了這些,系統才算比較完備。
所有的數據會存在分布式文件系統或是數據庫中,這些數據包括URL( URLRepo),Page( PageRepo )和Field( FieldRepo ),至于選擇什么樣的存儲系統,可以根據自己現有的基礎設施和熟悉程度而定。
為了擴大爬蟲系統的吞吐量,每個服務都可以橫向擴展,包括橫向復制,或是按URL來分片(sharding)。由于使用了Zookeeper,給某個服務增加一個copy,只用啟動這個服務就可以了,剩下的Zookeeper會自動處理。
這里只是給出了復雜分布式爬蟲系統的大框架,具體實現的時候,還有很多的細節需要處理,這時,之前做過爬蟲系統,踩過坑的經驗就很重要了。