微信為啥不丟“離線消息”?
需求緣起
當發送方用戶A發送消息給接收方用戶B時,如果用戶B在線,之前的文章《微信為啥不丟“在線消息”?》聊過,可以通過應用層的確認,發送方的超時重傳,接收方的去重保證業務層面消息的不丟不重。
那如果接收方用戶B不在線,系統是如何保證消息的可達性的呢?這是本文要討論的問題。
問題:接收方不在線時,消息發送的流程是怎么樣的?
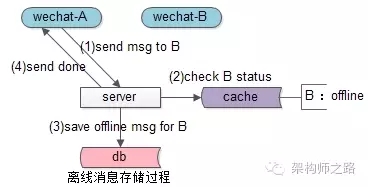
回答:如上圖所述,
(1)用戶A發送消息給用戶B
(2)服務器查看用戶B的狀態為offline
(3)服務器將消息存儲到DB中
(4)服務器返回用戶A發送成功(對于發送方而言,消息落地DB就認為發送成功)
問題:離線消息表的設計,拉取離線的過程?
receiver_uid, msg_id, time, sender_uid,msg_type, msg_content …
訪問模式:接收方B要拉取發送方A給ta發送的離線消息,只需在receiver_uid(B), sender_uid(A)上查詢,然后把離線消息刪除,再把消息返回B即可。
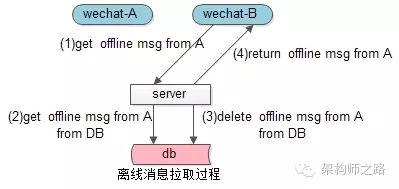
整體流程如上圖所述,
(1)用戶B拉取用戶A發送給ta的離線消息
(2)服務器從DB中拉取離線消息
(3)服務器從DB中把離線消息刪除
(4)服務器返回給用戶B想要的離線消息
問題:上述流程存在的問題?
回答:如果用戶B有很多好友,登陸時客戶端需要對所有好友進行離線消息拉取,客戶端與服務器交互次數較多
客戶端偽代碼:
- for(all uid in B’s friend-list){ // 登陸時所有好友都要拉取
- get_offline_msg(B,uid); // 與服務器交互
- }
優化方案一:先拉取各個好友的離線消息數量,真正用戶B進去看離線消息時,才往服務器發送拉取請求(手機端為了節省流量,經常會使用這個按需拉取的優化)
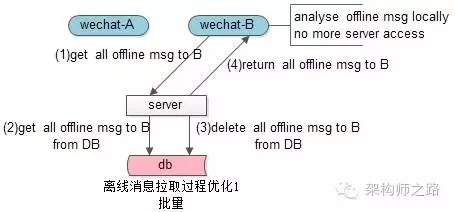
優化方案二:一次性拉取所有好友發送給用戶B的離線消息,到客戶端本地再根據sender_uid進行計算,這樣的話,離校消息表的訪問模式就變為->只需要按照receiver_uid來查詢了。登錄時與服務器的交互次數降低為了1次。
問題:用戶B一次性拉取所有好友發給ta的離線消息,消息量很大時,一個請求包很大,速度慢,容易卡頓怎么辦?
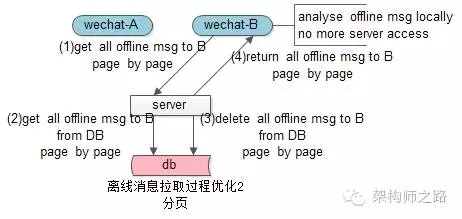
回答:分頁拉取,根據業務需求,先拉取***(或者最舊)的一頁消息,再按需一頁頁拉取。
問題:如何保證可達性,上述步驟第三步執行完畢之后,第四個步驟離線消息返回給客戶端過程中,服務器掛點,路由器丟消息,或者客戶端crash了,那離線消息豈不是丟了么(數據庫已刪除,用戶還沒收到)?
回答:嗯,如果按照上述的1,2,3,4步流程,的確是的,那如何保證離線消息的可達性?
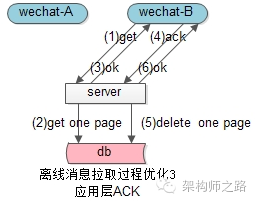
如同在線消息的應用層ACK機制一樣,離線消息拉時,不能夠直接刪除數據庫中的離線消息,而必須等應用層的離線消息ACK(說明用戶B真的收到離線消息了),才能刪除數據庫中的離線消息。
問題:如果用戶B拉取了一頁離線消息,卻在ACK之前crash了,下次登錄時會拉取到重復的離線消息么?
回答:拉取了離線消息卻沒有ACK,服務器不會刪除之前的離線消息,故下次登錄時系統層面還會拉取到。但在業務層面,可以根據msg_id去重。SMC理論:系統層面無法做到消息不丟不重,業務層面可以做到,對用戶無感知。
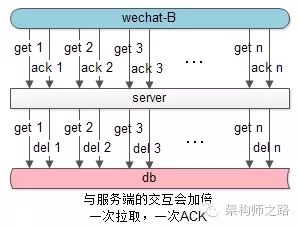
問題:假設有N頁離線消息,現在每個離線消息需要一個ACK,那么豈不是客戶端與服務器的交互次數又加倍了?有沒有優化空間?
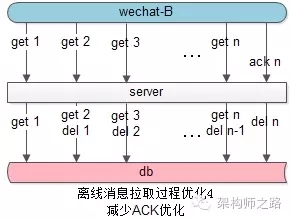
回答:不用每一頁消息都ACK,在拉取第二頁消息時相當于***頁消息的ACK,此時服務器再刪除***頁的離線消息即可,***一頁消息再ACK一次。這樣的效果是,不管拉取多少頁離線消息,只會多一個ACK請求,與服務器多一次交互。
總結
“離線消息”的可達性可能比大家想象的要復雜,常見的優化有:
(1)對于同一個用戶B,一次性拉取所有用戶發給ta的離線消息,再在客戶端本地進行發送方分析,相比按照發送方一個個進行消息拉取,能大大減少服務器交互次數
(2)分頁拉取,先拉取計數再按需拉取,是無線端的常見優化
(3)應用層的ACK,應用層的去重,才能保證離線消息的不丟不重
(4)下一頁的拉取,同時作為上一頁的ACK,能夠極大減少與服務器的交互次數
文章轉載自微信公眾號“架構師之路”