深度學習概覽之自然語言處理:從基本概念到前沿研究
自然語言處理介紹
介紹
自然語言處理(NLP)研究的問題是關于如何構建通過處理和理解語言來執行某些任務的系統。這些任務可包括
- 問答(像 Siri、Alexa、Cortana 所做的那些)
- 情感分析(決定是否某句話包含積極或消極的內涵)
- 圖像到文字的映射(生成一幅輸入圖像的注釋)
- 機器翻譯(將一段文字翻譯成另一種語言)
- 語音識別
- 詞性標注
- 命名實體識別
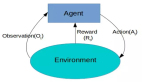
傳統的 NLP 方法涉及很多語言學領域自身的知識。要理解諸如音位和語素這樣的術語是非常基本的要求,就好像他們的研究統統都是語言學問題一樣。讓我們來看看傳統 NLP 是如何嘗試理解下面的話的。

假設我們的目標是收集關于這個詞的一些信息(表征其情感,找到它的定義等)。使用我們語言領域的知識,我們可以把這個詞分成 3 部分。

我們知道前綴「un」表示反對或相反的想法,我們知道「ed」可以指定單詞的時間段(過去時態)。通過識別詞干「興趣」的含義,我們可以很容易地推導出整個詞的定義和情感。看起來很簡單吧?然而,當考慮英語中所有不同的前綴和后綴時,需要非常熟練的語言學家來理解所有可能的組合和意義。
深度學習如何很好地解決這些問題?
從最基礎層面來說,深度學習即是表征學習(representation learning)。通過卷積神經網絡(CNN),我們可以看到不同的過濾器(filter)組合可以用來將各種物體分類。這里,我們將采用一種相似的方式,通過大數據集來創建對各種詞的表征。
本文概論
本文將以這樣的方式來組織文章的內容結構:我們將首先瀏覽一下構建 NLP 深度網絡的基本構建塊,然后來談一談最近研究論文所能帶來的一些應用。不知道我們為什么使用 RNN 或者為什么 LSTM 很有效?這些疑問都很正常,但希望你在讀完下面的這些研究論文之后能更好地了解為什么深度學習技術能夠如此顯著地促進了 NLP 的發展。
詞向量(Word Vectors)
由于深度學習愛用數學進行工作,我們將把每個詞表示為一個 d 維向量。讓我們使 d = 6。
[Image: https://quip.com/-/blob/cGAAAAubYyb/u9YfGL3mGnMUFhrXOfGArQ] 現在讓我們考慮如何填這些值。我們想要以這樣的方式填充值:向量以某種方式表示詞及其語境、含義或語義。一種方法是創建共生矩陣(coocurence matrix)。假設我們有以下句子:
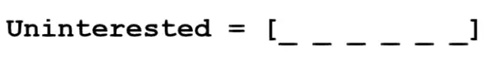
從這句話,我們要為每個特定的詞都創建一個詞向量。

共生矩陣是包含了在語料庫(或訓練集)中每個詞出現在所有其他詞之后的計數數目的矩陣。讓我們看看這個矩陣。
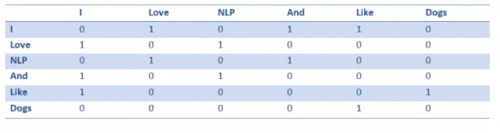
從該矩陣中提取行可以讓我們的詞向量簡單初始化。

請注意,通過這個簡單的矩陣,我們可以獲得一些非常有用的見解(insight)。例如,請注意「love」和「like」這兩個詞都包含 1,用于名詞(NLP 和狗)后的計數。它們與「I」的交集也是 1,因此表明這些詞必須是動詞。對于遠比一個句子更大的數據集,你可以想象這種相似性將變得更加清楚,因為「like」,「love」和其他同義詞將開始具有相似的單詞向量,因為它們都在相似的上下文中使用。
現在,盡管這是一個了不起的起點,但我們注意到每個詞的維數將隨著語料庫的大小線性增加。如果我們有一個百萬詞(在 NLP 標準中并不是很多),我們將有一個一百萬乘一百萬尺寸的矩陣,它將會非常稀疏(大量的 0)。從存儲效率上講這絕對不是最好的。在尋找表示這些詞向量的最優方法方面已經有許多進步。其中最著名的是 Word2Vec。
Word2Vec
詞向量初始化技術背后的基本思想是,我們要在這種詞向量中存儲盡可能多的信息,同時仍然保持維度在可管理的規模(25 - 1000 維度是理想的)。Word2Vec 基于這樣一個理念來運作,即我們想要預測每個單詞周圍可能的詞。讓我們以上一句話「I love NLP and I like dogs」為例。我們要看這句話的前 3 個詞。3 因此將是我們的窗口大小 m 的值。

現在,我們的目標是找到中心詞,「love」,并預測之前和之后的詞。我們如何做到這一點?當然是通過最大化/優化某一函數!正式地表述是,我們的函數將尋求給定當前中心詞的上下文詞的最大對數概率。
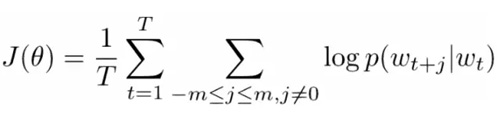
讓我們對這一點再深入地探究。上面的成本函數(cost function)基本上是說我們要添加'I'和'love'以及'NLP'和'love'的對數概率(其中「love」是兩種情況下的中心詞)。變量 T 表示訓練句子的數量。讓我們再仔細研究一下那個對數概率。
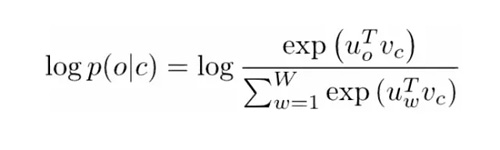
Vc 是中心詞的詞向量。每個詞由兩個向量表示(Uo 和 Uw),一個用于當該詞用作中心詞時,一個用于當它用作外部詞(outer word)時。向量是用隨機梯度下降(SGD)來訓練的。這絕對是一個理解起來更讓人困惑的方程之一,所以如果你仍然有疑問想了解到底發生了什么,你可以查看以下兩個資源:
- How does word2vec work?:https://www.quora.com/How-does-word2vec-work
- Word Embedding Explained and Visualized - word2vec and wevi:https://www.youtube.com/watch?v=D-ekE-Wlcds
一句總結:Word2Vec 尋求通過最大化給定中心詞的上下文詞的對數概率并通過 SGD 修改向量來找到不同詞的向量表示。
(可選:論文《Distributed Representations of Words and Phrases and their Compositionality》的作者接著詳細介紹了如何使用頻繁詞的負采樣(negative sampling)和下采樣(subsampling)獲得更精確的詞向量。)
有人認為,Word2Vec 最有趣的貢獻是使得不同詞向量之間表現出線性關系。經過訓練,詞向量似乎能捕獲不同的語法和語義概念。這些線性關系是如何能通過簡單的對象函數和優化技術來形成的,這一點真是相當難以置信。
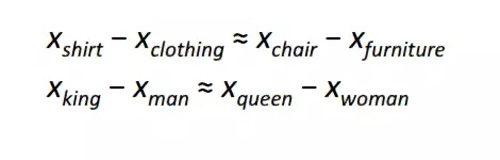
額外補充:另一種很酷的詞向量初始化方法:GloVe(將共生矩陣與 Word2Vec 的思想結合在一起):http://nlp.stanford.edu/pubs/glove.pdf
循環神經網絡(RNN)
好吧,那么現在我們有了我們的詞向量,讓我們看看它們如何與循環神經網絡結合在一起的。RNN 是當今大多數 NLP 任務的必選方法。RNN 的最大優點是它能夠有效地使用來自先前時間步驟的數據。這是一小片 RNN 的大致樣子。
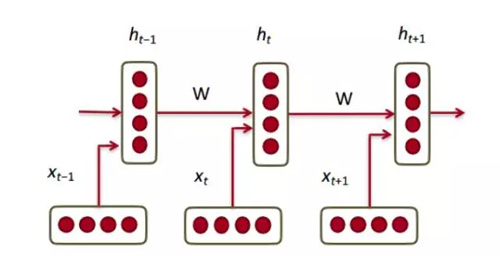
因此,在底層,我們有我們的詞向量(xt,xt-1,xt + 1)。每個向量在同一時間步驟(ht,ht-1,ht + 1)有一個隱藏狀態向量。讓我們稱之為一個模塊(module)。
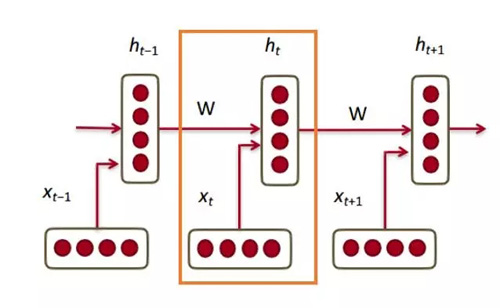
RNN 的每個模塊中的隱藏狀態是在前一時間步驟的詞向量和隱藏狀態向量二者的函數。
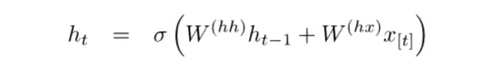
如果你仔細看看上標,你會看到有一個權重矩陣 Whx,我們將它乘以我們的輸入,并且在上一個時間步驟中,用一個循環出現的權重矩陣 Whh 乘以隱藏狀態向量。請記住,這些循環出現的權重矩陣(recurrent weight matrix)在所有時間步驟上都是相同的。這是 RNN 的關鍵點。仔細考慮一下這一點,它與傳統的(比如 2 層的神經網絡)非常不同。在這種情況下,我們通常對于每個層(W1 和 W2)都有不同的 W 矩陣。這里,循環權重矩陣在網絡中是相同的。
為了得到特定模塊的輸出(Yhat),將以 h 乘以 WS,這是另一個權重矩陣。
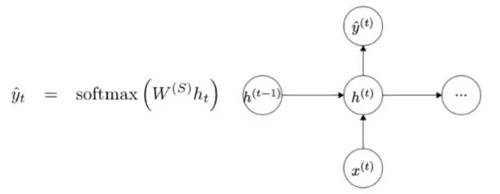
讓我們現在退一步并且來理解 RNN 的優點是什么。與傳統神經網絡的最明顯的區別是,RNN 接受輸入的序列(在我們的例子中是詞)。你可以將其與典型的 CNN 進行對比,在 CNN 中你只需要一個單一的圖像作為輸入。然而,使用 RNN,輸入可以是從一個短句到一篇 5 段文章等各種長度。此外,該序列中的輸入的順序(order)可以極大地影響在訓練期間權重矩陣和隱藏狀態向量的改變情況。在訓練之后,隱藏狀態將有望捕獲來自過去的信息(以前的時間步驟)。
門控循環單位(GRU)
現在讓我們來看門控循環單元(GRU)。這種單元的目的是為計算 RNN 中的隱藏狀態向量提供一種更復雜的方法。這種方法得以使我們保留捕獲長距依賴(long distance dependencies)的信息。讓我們想想看為什么在傳統 RNN 設置中長期依賴會成為一個問題。在反向傳播期間,誤差將流經 RNN,即從最近的時間步驟至最早的時間步驟。如果初始梯度是個小數字(例如<0.25),則通過第 3 或第 4 模塊,梯度實際上將會消失(鏈式規則乘以梯度),因此較早時間步驟的隱藏狀態將無法更新。
在傳統的 RNN 中,隱藏狀態向量通過下面的公式計算得來。
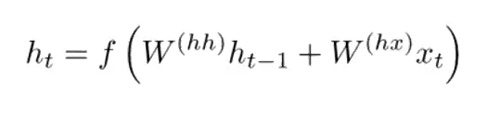
GRU 提供了一個計算此隱藏狀態向量 h(t) 的不同方式。計算分為 3 個分量,一個更新門(update gate),一個重置門(reset gate)以及一個新的記憶容器(memory container)。兩個門均是前一時間步驟上輸入詞向量和隱藏狀態的函數。
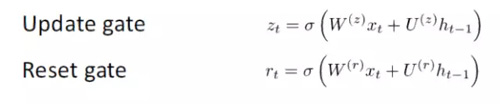
關鍵區別在于每個門使用不同的權重。這種區別通過不同的上標來表示。更新門使用 Wz 和 Uz,而重置門使用 Wr 和 Ur。
現在,通過以下方式計算新的記憶容器:

空心點表示Hadamard積
現在,如果你仔細看看公式,你將看到,如果重置門單元接近 0,那么整個項也變為 0,此時可以忽略來自之前時間步驟的 ht-1 的信息。在這種情況下,單元只是新的詞向量 xt 的函數。
h(t) 的最終公式寫為:
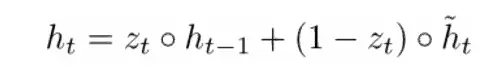
ht 是一個由三部分構成的函數:重置門、更新門和記憶容器。通過觀察當 zt 接近 1 和接近 0 時會發生什么是理解這點最好的方法。當 zt 接近 1 時,新的隱藏狀態向量 ht 主要取決于先前的隱藏狀態,且因為(1-zt)變為 0 使得我們會忽略當前的存儲容器。當 zt 接近 0 時,新的隱藏狀態向量 ht 主要取決于當前的存儲容器,此時我們會忽略之前的隱藏狀態。觀察這三部分最直觀的方法可以總結如下。
- 更新門, 如果 zt〜1,則 ht 完全忽略當前詞向量,且只復制上一個隱藏狀態(如果行不通,看看 ht 方程,并且注意當 zt〜1 時 1 - zt 項發生什么)。如果 zt〜0,則 ht 完全忽略上一時間步驟上的隱藏狀態,且依賴新的記憶容器。此門讓模型控制著之前隱藏狀態中應影響當前隱藏狀態的信息的多少。
- 重置門, 如果 rt〜1,則存儲容器阻止來自之前隱藏狀態的信息。如果 rt〜0,則存儲容器忽略之前的隱藏狀態。如果該信息在將來不具有相關性,則此門會令模型刪除信息。
- 記憶容器:取決于重置門。
闡明 GRU 有效性的常見示例如下。假設你有以下語段。
和相關問題「2 個數字的和是什么?」。由于中間語句對手頭問題絕對沒有影響,重置門和更新門將允許網絡在一定意義上「忘記」中間語句,同時僅學習應修改隱藏狀態的特定信息(這種情況下是數字)。
長短時記憶單元(LSTM)
如果你對 GRU 感到滿意的話,那么 LSTM 并不會讓你更加滿意。LSTM 也是由一系列的門組成。
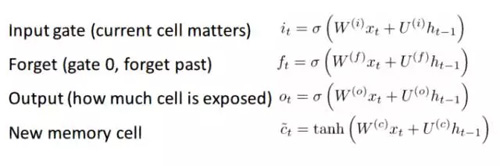
肯定有更多的信息需要采集。因為這可以被認為是 GRU 背后的想法的延伸,我不會進行深入地分析。如果你想對每一個門和每一步計算進行深入地演算,請查看 Chris Olah 的一篇非常好的博客文章:http://colah.github.io/posts/2015-08-Understanding-LSTMs/。這是迄今為止,在 LSTM 上最受歡迎的教程,它一定會幫助你理解這些單元工作的這么好的原因和其工作方式。
LSTM 和 GRU 的比較
讓我們從兩者相似之處看起。這兩種單元具有能夠保持序列中字的長期依賴性的特殊功能。長期依賴性指兩個詞或者短語可能會在不同的時間段出現的情況,但是它們之間的關系對于解決最終目標仍然至關重要。LSTM 和 GRU 能夠通過忽略或者保持序列中的某些信息的門來獲取這些依賴性。
兩個單元之間的差異在于它們所擁有的門的數量(GRU – 2, LSTM – 3)。這影響了輸入通過的非線性數,并最終影響整體計算。GRU 也不具有與 LSTM 相同的記憶單元(ct)。
看論文之前
只是做一個快速的注釋。還有一些其他的深度模型在自然語言處理(NLP)當中很有用。遞歸神經網絡(recursive neural networks)和用于自然語言處理(NLP)的卷積神經網絡(CNN)有時會在實踐中應用,但不像循環神經網絡(Recurrent neural Network)那樣流行。循環神經網絡(RNN)是在大多數深度學習自然語言處理(NLP)系統中的支柱。
好的。現在我們對與自然語言處理(NLP)相關的深度學習有了不錯的理解,讓我們來看一些論文。由于在自然語言處理(NLP)中有許多不同領域的問題(從機器翻譯到問題回答),我們可以研究許多論文,但是我發現其中有三篇論文有著獨到的見解。2016 年,在自然語言處理(NLP)方面有著巨大的進步,但是讓我們從 2015 年的一篇論文看起。
- 論文:記憶網絡(Memory Networks)
- 鏈接:https://arxiv.org/pdf/1410.3916v11.pdf
簡介:第一篇文章,我們將要討論的是在問答(Queston Answering)子領域的一個非常有影響力的論文。作者是 Jason Weston、Sumit Chopra 和 Antoine Bordes,這篇論文介紹了一類稱為記憶網絡的模型。
記憶網絡的直觀思想是:為了準確地回答關于一段文本的問題,你需要以某種方式記憶被提供的最初的信息。如果我問你「RNN 代表什么?」,(假設你已經完全閱讀了這篇文章),你將會給我一個答案。因為你通過閱讀這篇文章的第一部分所得到的信息,將會存儲在你記憶中的某個地方。你只需要幾秒鐘來找到這個信息,并用文字將其表述出來。現在,我不知道大腦是如何作到這一點的,但是為信息保留存儲空間的想法仍然存在。
本文中描述的記憶網絡是唯一的,因為它是一種能夠讀寫的關聯記憶(associative memory)。有趣的是,我們并沒有這種類型的卷積神經網絡或者 Q 網絡(Q-Network)(應用于強化學習)或者傳統的神經網絡的記憶。這是因為問答任務很大程度上依賴于建模的能力或者保持追蹤長期依賴性的能力,比如追蹤故事中的角色或事件的時間線。使用卷積神經網絡和 Q 網絡,「記憶(memory)」是一種內置在網絡的權重。因為它可以學習從狀態到動作的不同的篩選或者映射。首先,可以使用 RNN 和 LSTM,但是它們通常不能記憶來自過去的輸入(這在回答任務中中非常重要)。
網絡架構
好的,現在讓我們來看一看這個網絡如何處理它給出的初始文本。就像大多數機器學習算法一樣,第一步是將輸入轉化為特征表示。這需要使用詞向量、詞性標簽等。這真的取決于編程者。

下一步將采用特征表示 I(x),并允許更新我們的記憶 m 以反映我們接收到的最新的輸入 x。
![]()
你可以認為記憶 m 是一種由單獨的記憶 mi 組成的數組。這些單獨的記憶 mi 中的每一個都可以作為整體的記憶 m,特征表示 I(x) 和/或者它本身。該函數 G 可以簡單地將整個表示 I(x) 存儲在單獨的記憶單元 mi 中。基于新的輸入,你可以修改函數 G 來更新過去的記憶。第三和第四步包括基于問題讀取記憶以獲得特征表示 o,然后對其解碼以輸出最終答案 r。

R 函數可以用來將特征表示從記憶轉化為問題的即可靠又準確的答案。
現在,讓我們來看第三步。我們希望這個 O 模塊輸出一個特征表示,使其最佳地匹配給定問題 X 的一個可能的答案。現在這個問題將要與每個獨立的記憶單元進行匹配并且基于記憶單元支持該問題的程度被「評分」。
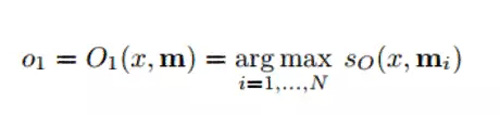
我們使用評分函數的 argmax 值來找到支持問題的最佳輸出表示(你也可以取多個最高得分單位,不必限于 1)。評分函數是計算不同問題和選取存儲單元的不同嵌入之間的矩陣乘積的函數(更多細節請查看論文)。你也可以這樣認為,你將兩個單詞的單詞向量相乘以找到他們的相似之處。然后將輸出表示 o 饋送入 RNN 或者 LSTM 或者另一個輸出可靠答案的評分函數。
該網絡以監督的方式訓練,其中訓練數據包括原始文本、問題、支撐句(supporting sentences)、以及 ground truth 答案。這里是目標函數。

對于那些感興趣的人,這是構建這種記憶網絡方法的論文。
End to End Memory Networks:https://arxiv.org/pdf/1503.08895v5.pdf
Dynamic Memory Networks:https://arxiv.org/pdf/1506.07285v5.pdf
Dynamic Coattention Networks :https://arxiv.org/pdf/1611.01604v2.pdf
論文:用于情感分析的 LSTM 樹(Tree LSTMs for Sentiment Analysis)
鏈接:https://arxiv.org/pdf/1503.00075v3.pdf
簡介:下一篇文章討論了情感分析方面的進步,確定短語是否有正面或者負面的含義/意義。更正式地說,情感可以被定義為「對于某個情況或事件的看法或者態度」。當時,LSTM 是情感分析網絡中最常用的單元。作者:Kai Sheng Tai、Richard Socher 和 Christopher Manning,本文介紹了以一種非線性的結構將 LSTM 連接在一起的新方法。
這種非線性組合背后的動機在于自然語言中表現出的將序列中的詞變成短語的特性。這些取決于詞的順序的短語可以有著與原始的組成詞不同的意義。為了表示這種特性,LSTM 單元的網絡被布置成樹狀結構,其中不同單元受其子節點的影響。
網絡架構
LSTM 樹和標準樹之間的一個區別是,后者的隱藏狀態是當前輸入和先前時間步長的隱藏狀態的一個函數。然而,對于 LSTM 樹,其隱藏狀態是當前輸入和其子單元的隱藏狀態的函數。
有著新的基于樹的結構,一些數學變換,包括具有遺忘門(forget gates)的子單元。對于那些對細節感興趣的人,請查看論文獲取更多信息。然而,我想要關注的是為什么這些模塊比線性 LSTM 工作的更好。
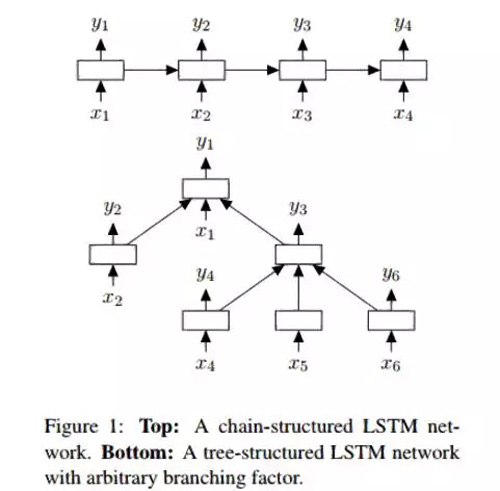
使用 LSTM 樹,單個的單元能夠并入其所有子節點的隱藏狀態。這非常有趣,因為一個單元可以不同地評價其每個子節點。在訓練期間,神經網絡可以實現特定詞(也許是在情感分析中的「not」或者「very」),這對句子的整體情感非常重要。將節點評價的更高為網絡提供了極高的靈活性,并可以提高其性能。
論文:神經機器翻譯(Neural Machine Translation)
鏈接:https://arxiv.org/pdf/1609.08144v2.pdf
簡介:我們今天要討論的最后一篇論文描述了機器翻譯任務的另一種方法。作者為谷歌大腦的 Jeff Dean、Greg Corrado、Orial Vinyals 等人,本文介紹了一種機器翻譯系統,該系統為谷歌流行的翻譯任務的支柱。與之前使用的谷歌生產系統相比,該系統平均減少了 60% 的翻譯錯誤。
傳統的自動翻譯方法包括基于短語匹配的變體。這種方法需要大量的語言領域的知識,最終它的設計被證明太脆弱并且缺乏泛化能力。傳統方法的一個問題是它將嘗試逐個翻譯輸入的句子。結果,更有效的方法是(神經機器翻譯(NMT)使用的方法)一次翻譯整個句子,從而允許上下文更加廣泛并且使語言重新排列的更加自然。
網絡架構
本文作者介紹了一個深層 LSTM 網絡,可以端對端的訓練 8 個編碼器和解碼器層。我們可以將這個系統分為 3 個部分,編碼器 RNN、解碼器 RNN 和注意模塊。從更高的等級,編碼器致力于將輸入的句子轉變為向量的表示,解碼器產生輸出表示,然后注意模塊告知解碼器在解碼任務期間要關注什么(這是一種使用句子的整體語境的思想)。
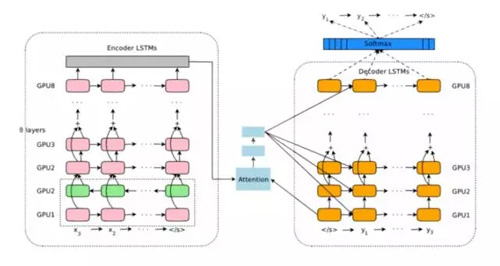
本論文的其余部分主要集中于大規模部署這樣的服務相關的挑戰。將詳細討論諸如計算資源量、延遲和大容量部署等主題。機器之心曾經報道過對這項研究的解讀,請參閱《深度 | 逐層剖析,谷歌機器翻譯突破背后的神經網絡架構是怎樣的?》
結論
我們總結了關于深度學習幫助自然語言處理任務的方法。在我看來,該領域一些的未來目標關注在改進客戶服務聊天機器人、完善機器翻譯、并希望使問答系統能夠獲得對非結構化或者冗長的文本(比如維基百科頁面)的更深入的了解。
【本文是51CTO專欄機構機器之心的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】