Python機器學習實戰:信用卡欺詐檢測
故事背景:原始數據為個人交易記錄,但是考慮數據本身的隱私性,已經對原始數據進行了類似PCA的處理,現在已經把特征數據提取好了,接下來的目的就是如何建立模型使得檢測的效果達到最好,這里我們雖然不需要對數據做特征提取的操作,但是面對的挑戰還是蠻大的。
- import pandas as pd
- import matplotlib.pyplot as plt
- import numpy as np
- from sklearn.cross_validation import train_test_split
- from sklearn.linear_model import LogisticRegression
- from sklearn.cross_validation import KFold, cross_val_score
- from sklearn.metrics import confusion_matrix,recall_score,classification_report
數據分析與建模可不是體力活,時間就是金錢我的朋友(魔獸玩家都懂的!)如果你用Python來把玩數據,那么這些就是你的核武器啦。簡單介紹一下這幾位朋友!
- Numpy-科學計算庫 主要用來做矩陣運算,什么?你不知道哪里會用到矩陣,那么這樣想吧,咱們的數據就是行(樣本)和列(特征)組成的,那么數據本身不就是一個矩陣嘛。
- Pandas-數據分析處理庫 很多小伙伴都在說用python處理數據很容易,那么容易在哪呢?其實有了pandas很復雜的操作我們也可以一行代碼去解決掉!
- Matplotlib-可視化庫 無論是分析還是建模,光靠好記性可不行,很有必要把結果和過程可視化的展示出來。
- Scikit-Learn-機器學習庫 非常實用的機器學習算法庫,這里面包含了基本你覺得你能用上所有機器學習算法啦。但還遠不止如此,還有很多預處理和評估的模塊等你來挖掘的!
- data = pd.read_csv("creditcard.csv") data.head()

首先我們用pandas將數據讀進來并顯示最開始的5行,看見木有!用pandas讀取數據就是這么簡單!這里的數據為了考慮用戶隱私等,已經通過PCA處理過了,現在大家只需要把數據當成是處理好的特征就好啦!
接下來我們核心的目的就是去檢測在數據樣本中哪些是具有欺詐行為的!
- count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
- count_classes.plot(kind = 'bar')
- plt.title("Fraud class histogram")
- plt.xlabel("Class")
- plt.ylabel("Frequency"
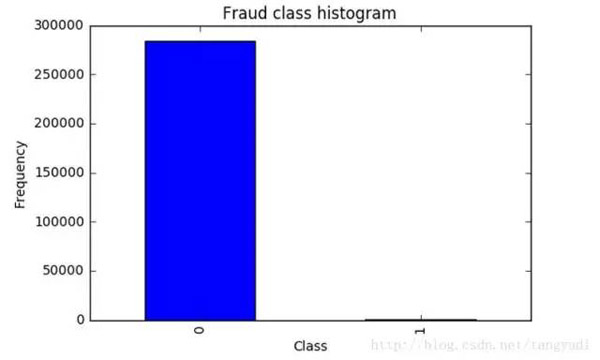
千萬不要著急去用機器學習算法建模做這個分類問題。首先我們來觀察一下數據的分布情況,在數據樣本中有明確的label列指定了class為0代表正常情況,class為1代表發生了欺詐行為的樣本。從上圖中可以看出來。。。等等,你不是說有兩種情況嗎,為啥圖上只有class為0的樣本啊?再仔細看看,納尼。。。class為1的并不是木有,而是太少了,少到基本看不出來了,那么此時我們面對一個新的挑戰,樣本極度不均衡,接下來我們首先要解決這個問題,這個很常見也是很頭疼的問題。
這里我們提出兩種解決方案 也是數據分析中最常用的兩種方法,下采樣和過采樣!
先挑個軟柿子捏,下采樣比較簡單實現,咱們就先搞定第一種方案!下采樣的意思就是說,不是兩類數據不均衡嗎,那我讓你們同樣少(也就是1有多少個 0就消減成多少個),這樣不就均衡了嗎。
很簡單的實現方法,在屬于0的數據中,進行隨機的選擇,就選跟class為1的那類樣本一樣多就好了,那么現在我們已經得到了兩組都是非常少的數據,接下來就可以建模啦!不過在建立任何一個機器學習模型之前不要忘了一個常規的操作,就是要把數據集切分成訓練集和測試集,這樣會使得后續驗證的結果更為靠譜。
在訓練邏輯回歸的模型中做了一件非常常規的事情,就是對于一個模型,咱們再選擇一個算法的時候伴隨著很多的參數要調節,那么如何找到最合適的參數可不是一件簡單的事,依靠經驗值并不是十分靠譜,通常情況下我們需要大量的實驗也就是不斷去嘗試最終得出這些合適的參數。
不同C參數對應的最終模型效果:
- C parameter: 0.01
- Iteration 1 : recall score = 0.958904109589
- Iteration 2 : recall score = 0.917808219178
- Iteration 3 : recall score = 1.0
- Iteration 4 : recall score = 0.972972972973
- Iteration 5 : recall score = 0.954545454545
- Mean recall score 0.960846151257
- C parameter: 0.1
- Iteration 1 : recall score = 0.835616438356
- Iteration 2 : recall score = 0.86301369863
- Iteration 3 : recall score = 0.915254237288
- Iteration 4 : recall score = 0.932432432432
- Iteration 5 : recall score = 0.878787878788
- Mean recall score 0.885020937099
- C parameter: 1
- Iteration 1 : recall score = 0.835616438356
- Iteration 2 : recall score = 0.86301369863
- Iteration 3 : recall score = 0.966101694915
- Iteration 4 : recall score = 0.945945945946
- Iteration 5 : recall score = 0.893939393939
- Mean recall score 0.900923434357
- C parameter: 10
- Iteration 1 : recall score = 0.849315068493
- Iteration 2 : recall score = 0.86301369863
- Iteration 3 : recall score = 0.966101694915
- Iteration 4 : recall score = 0.959459459459
- Iteration 5 : recall score = 0.893939393939
- Mean recall score 0.906365863087
- C parameter: 100
- Iteration 1 : recall score = 0.86301369863
- Iteration 2 : recall score = 0.86301369863
- Iteration 3 : recall score = 0.966101694915
- Iteration 4 : recall score = 0.959459459459
- Iteration 5 : recall score = 0.893939393939
- Mean recall score 0.909105589115
- Best model to choose from cross validation is with C parameter = 0.01
在使用機器學習算法的時候,很重要的一部就是參數的調節,在這里我們選擇使用最經典的分類算法,邏輯回歸!千萬別把邏輯回歸當成是回歸算法,它就是最實用的二分類算法!這里我們需要考慮的c參數就是正則化懲罰項的力度,那么如何選擇到最好的參數呢?這里我們就需要交叉驗證啦,然后用不同的C參數去跑相同的數據,目的就是去看看啥樣的C參數能夠使得最終模型的效果最好!可以到不同的參數對最終的結果產生的影響還是蠻大的,這里最好的方法就是用驗證集去尋找了!
模型已經造出來了,那么怎么評判哪個模型好,哪個模型不好呢?我們這里需要好好想一想!
一般都是用精度來衡量,也就是常說的準確率,但是我們來想一想,我們的目的是什么呢?是不是要檢測出來那些異常的樣本呀!換個例子來說,假如現在醫院給了我們一個任務要檢測出來1000個病人中,有癌癥的那些人。那么假設數據集中1000個人中有990個無癌癥,只有10個有癌癥,我們需要把這10個人檢測出來。假設我們用精度來衡量,那么即便這10個人沒檢測出來,也是有 990/1000 也就是99%的精度,但是這個模型卻沒任何價值!這點是非常重要的,因為不同的評估方法會得出不同的答案,一定要根據問題的本質,去選擇最合適的評估方法。
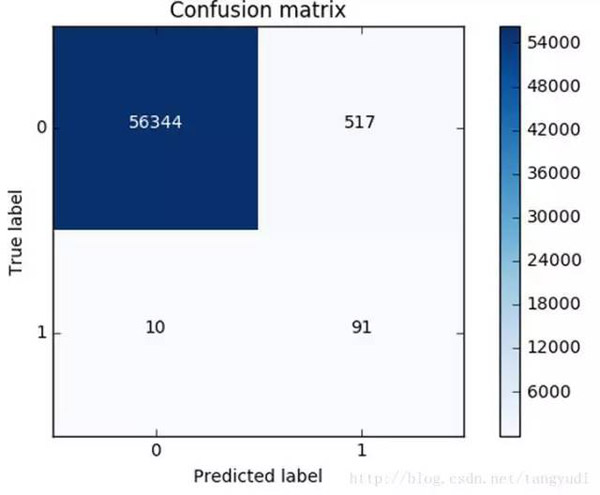
同樣的道理,這里我們采用recall來計算模型的好壞,也就是說那些異常的樣本我們的檢測到了多少,這也是咱們最初的目的!這里通常用混淆矩陣來展示。

這個圖就非常漂亮了!(并不是說畫的好而是展示的很直接)從圖中可以清晰的看到原始數據中樣本的分布以及我們的模型的預測結果,那么recall是怎么算出來的呢?就是用我們的檢測到的個數(137)去除以總共異常樣本的個數(10+137),用這個數值來去評估我們的模型。利用混淆矩陣我們可以很直觀的考察模型的精度以及recall,也是非常推薦大家在評估模型的時候不妨把這個圖亮出來可以幫助咱們很直觀的看清楚現在模型的效果以及存在的問題。
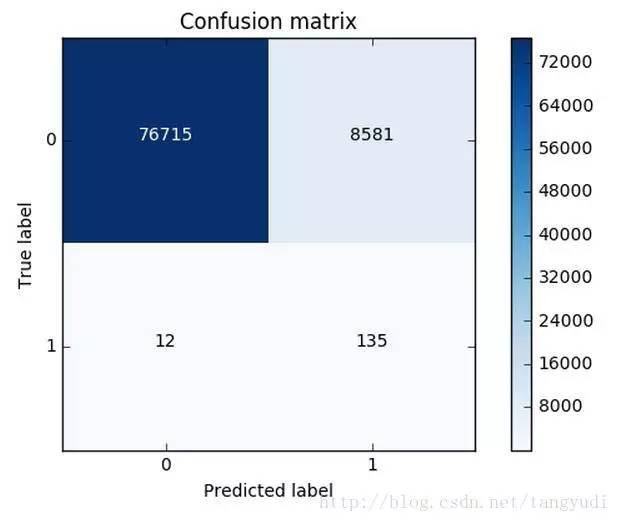
這可還木有完事,我們剛才只是在下采樣的數據集中去進行測試的,那么這份測試還不能完全可信,因為它并不是原始的測試集,我們需要在原始的,大量的測試集中再次去衡量當前模型的效果。可以看到效果其實還不錯,但是哪塊有些問題呢,是不是我們誤殺了很多呀,有些樣本并不是異常的,但是并我們錯誤的當成了異常的,這個現象其實就是下采樣策略本身的一個缺陷。
對于邏輯回歸算法來說,我們還可以指定這樣一個閾值,也就是說最終結果的概率是大于多少我們把它當成是正或者負樣本。不用的閾值會對結果產生很大的影響。
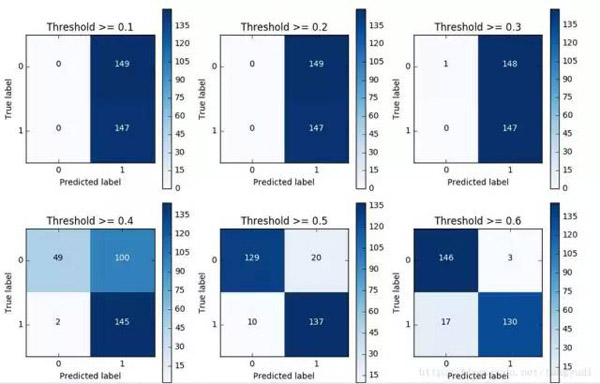
上圖中我們可以看到不用的閾值產生的影響還是蠻大的,閾值較小,意味著我們的模型非常嚴格寧肯錯殺也不肯放過,這樣會使得絕大多數樣本都被當成了異常的樣本,recall很高,精度稍低 當閾值較大的時候我們的模型就稍微寬松些啦,這個時候會導致recall很低,精度稍高,綜上當我們使用邏輯回歸算法的時候,還需要根據實際的應用場景來選擇一個最恰當的閾值!
說完了下采樣策略,我們繼續嘮一下過采樣策略,跟下采樣相反,現在咱們的策略是要讓class為0和1的樣本一樣多,也就是我們需要去進行數據的生成啦。
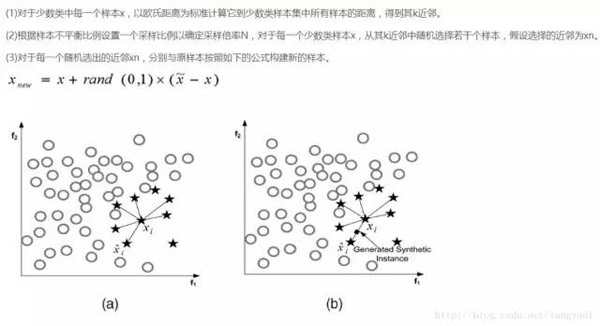
SMOTE算法是用的非常廣泛的數據生成策略,流程可以參考上圖,還是非常簡單的,下面我們使用現成的庫來幫助我們完成過采樣數據生成策略。
很簡單的幾步操作我們就完成過采樣策略,那么現在正負樣本就是一樣多的啦,都有那么20多W個,現在我們再通過混淆矩陣來看一下,邏輯回歸應用于過采樣樣本的效果。數據增強的應用面已經非常廣了,對于很多機器學習或者深度學習問題,這已經成為了一個常規套路啦!
我們對比一下下采樣和過采樣的效果,可以說recall的效果都不錯,都可以檢測到異常樣本,但是下采樣是不是誤殺的比較少呀,所以如果我們可以進行數據生成,那么在處理樣本數據不均衡的情況下,過采樣是一個可以嘗試的方案!
總結:對于一個機器學習案例來說,一份數據肯定伴隨著很多的挑戰和問題,那么最為重要的就是我們該怎么解決這一系列的問題,大牛們不見得代碼寫的比咱們強但是他們卻很清楚如何去解決問題。今天咱們講述了一個以檢測任務為背景的案例,其中涉及到如何處理樣本不均衡問題,以及模型評估選擇的方法,最后給出了邏輯回歸在不用閾值下的結果。這里也是希望同學們可以通過案例多多積攢經驗,早日成為大牛。