應對機器學習中類不平衡的10種技巧
介紹
當一個類的觀察值高于其他類的觀察值時,則存在類失衡。
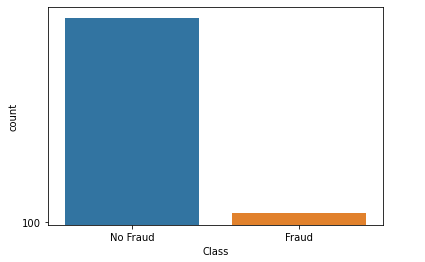
示例:檢測信用卡欺詐交易。如下圖所示,欺詐交易大約為400,而非欺詐交易大約為90000。
類不平衡是機器學習中的常見問題,尤其是在分類問題中。不平衡數據可能會長時間妨礙我們的模型準確性。
類不平衡出現在許多領域,包括:
- 欺詐識別
- 垃圾郵件過濾
- 疾病篩查
- SaaS訂閱流失
- 廣告點擊
類失衡問題
當每個類別中的樣本數量大致相等時,大多數機器學習算法效果最佳。這是因為大多數算法都是為了最大化精確度和減少誤差而設計的。
然而,如果數據集不平衡,那么在這種情況下,僅僅通過預測多數類就可以獲得相當高的準確率,但是無法捕捉少數類,這通常是創建模型的首要目的。
信用卡欺詐檢測示例
假設我們有一個信用卡公司的數據集,我們必須找出信用卡交易是否是欺詐性的。
但是這里有個陷阱……欺詐交易相對罕見,只有6%的交易是欺詐行為。
現在,在你還沒有開始之前,你是否能想到問題應該如何解決?想象一下,如果你根本不花時間訓練模型。相反,如果你只編寫了一行總是預測“沒有欺詐性交易”的代碼,該怎么辦?
- def transaction(transaction_data):
- return 'No fradulent transaction'
好吧,你猜怎么著?你的“解決方案”將具有94%的準確性!
不幸的是,這種準確性令人誤解。
所有這些非欺詐性的交易,你都將擁有100%的準確性。
那些欺詐性的交易,你的準確性為0%。
僅僅因為大多數交易不是欺詐性的(不是因為你的模型很好),你的總體準確性就很高。
這顯然是一個問題,因為許多機器學習算法都旨在最大程度地提高整體準確性。在本文中,我們將看到處理不平衡數據的不同技術。
數據
我們將在本文中使用信用卡欺詐檢測數據集,你可以從此處找到該數據集。
https://www.kaggle.com/mlg-ulb/creditcardfraud
加載數據后,顯示數據集的前五行。
- # check the target variable that is fraudulet and not fradulent transactiondata['Class'].value_counts()# 0 -> non fraudulent
- # 1 -> fraudulent
- # visualize the target variable
- g = sns.countplot(data['Class'])
- g.set_xticklabels(['Not Fraud','Fraud'])
- plt.show()
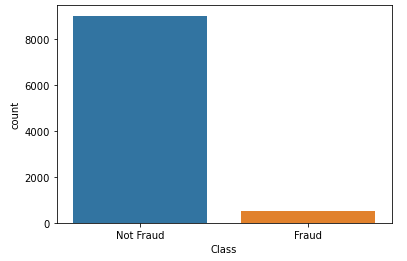
你可以清楚地看到數據集之間存在巨大差異。9000次非欺詐性交易和492次欺詐性交易。
指標陷阱
新開發人員用戶在處理不平衡數據集時遇到的一個主要問題與用于評估其模型的指標有關。使用更簡單的指標,比如準確度得分,可能會產生誤導。在具有高度不平衡類的數據集中,分類器總是在不進行特征分析的情況下“預測”最常見的類,并且它的準確率很高,顯然不是正確的。
讓我們做這個實驗,使用簡單的XGBClassifier和無特征工程:
- # import linrary
- from xgboost import XGBClassifier
- xgb_model = XGBClassifier().fit(x_train, y_train)# predictxgb_y_predict = xgb_model.predict(x_test)# accuracy scorexgb_score = accuracy_score(xgb_y_predict, y_test)print('Accuracy score is:', xbg_score)OUTPUT
- Accuracy score is: 0.992
我們可以看到99%的準確度,我們得到的是非常高的準確度,因為它預測大多數類別為0(非欺詐性)。
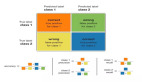
重采樣技術
一種處理高度不平衡數據集的廣泛采用的技術稱為重采樣。它包括從多數類中刪除樣本(欠采樣)和/或從少數類中添加更多示例(過采樣)。
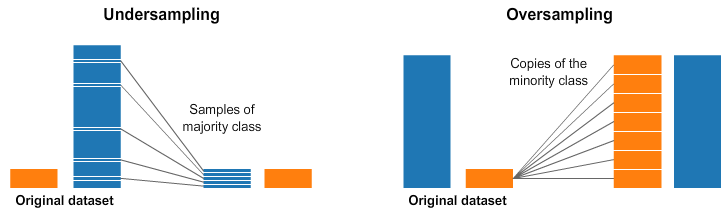
盡管平衡類有很多好處,但是這些技巧也有缺點。
過采樣最簡單的實現是復制少數群體類別的隨機記錄,這可能會導致過度捕撈。
欠采樣最簡單的實現涉及從多數類中刪除隨機記錄,這可能會導致信息丟失。
讓我們用信用卡欺詐檢測示例來實現它。
我們將首先將類0和類1分開。
- # class count
- class_count_0, class_count_1 = data['Class'].value_counts()
- # Separate classclass_0 = data[data['Class'] == 0]
- class_1 = data[data['Class'] == 1]# print the shape of the class
- print('class 0:', class_0.shape)
- print('class 1:', class_1.shape

1.隨機欠采樣
欠采樣可以定義為刪除多數類的觀察值。這是在多數類和少數類被平衡之前進行的。
當你擁有大量數據時,欠采樣可能是一個不錯的選擇,比如數百萬行。但是欠采樣的一個缺點是我們可能刪除了有價值的信息。
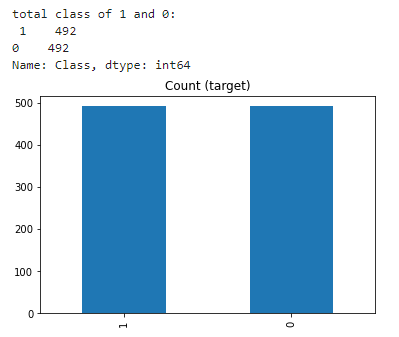
- class_0_under = class_0.sample(class_count_1)
- test_under = pd.concat([class_0_under, class_1], axis=0)
- print("total class of 1 and0:",test_under['Class'].value_counts())# plot the count after under-sampeling
- test_under['Class'].value_counts().plot(kind='bar', title='count (target)')
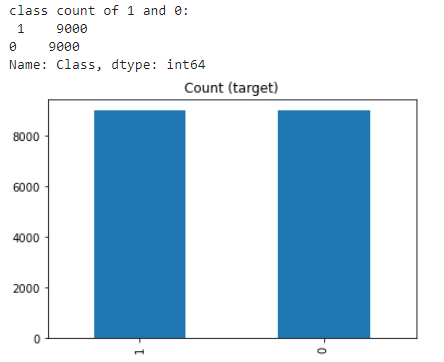
2.隨機過采樣
過采樣可以定義為向少數類添加更多副本。當你沒有大量數據要處理時,過采樣可能是一個不錯的選擇。
欠采樣時要考慮的一個弊端是,它可能導致過擬合并導致測試集泛化不佳。
- class_1_over = class_1.sample(class_count_0, replace=True)
- test_over = pd.concat([class_1_over, class_0], axis=0)
- print("total class of 1 and 0:",test_under['Class'].value_counts())# plot the count after under-sampeling
- test_over['Class'].value_counts().plot(kind='bar', title='count (target)')
使用不平衡學習python模塊平衡數據
在科學文獻中已經提出了許多更復雜的重采樣技術。
例如,我們可以將多數類的記錄聚類,并通過從每個聚類中刪除記錄來進行欠采樣,從而尋求保留信息。在過采樣中,我們可以為這些副本引入較小的變化,從而創建更多樣的合成樣本,而不是創建少數群體記錄的精確副本。
讓我們使用Python庫 imbalanced-learn應用其中一些重采樣技術。它與scikit-learn兼容,并且是scikit-learn-contrib項目的一部分。
- import imblearn
3.使用imblearn進行隨機欠采樣
RandomUnderSampler通過為目標類別隨機選擇數據子集來平衡數據的快速簡便方法。通過隨機選擇有或沒有替代品的樣本對多數類別進行欠采樣。
- # import library
- from imblearn.under_sampling import RandomUnderSampler
- rus = RandomUnderSampler(random_state=42, replacement=True)# fit predictor and target variable
- x_rus, y_rus = rus.fit_resample(x, y)print('original dataset shape:', Counter(y))
- print('Resample dataset shape', Counter(y_rus))

4.使用imblearn進行隨機過采樣
解決不平衡數據的一種方法是在少數群體中生成新樣本。最幼稚的策略是通過隨機采樣替換當前可用的采樣來生成新的采樣。隨機過采樣提供了這樣一個方案。
- # import library
- from imblearn.over_sampling import RandomOverSampler
- ros = RandomOverSampler(random_state=42)
- # fit predictor and target variablex_ros, y_ros = ros.fit_resample(x, y)print('Original dataset shape', Counter(y))
- print('Resample dataset shape', Counter(y_ros))

5.欠采樣:Tomek鏈接
Tomek鏈接是一對非常接近的實例,但類別相反。刪除每對多數類的實例會增加兩個類之間的空間,從而有助于分類過程。
如果兩個樣本是彼此的最近鄰,則存在Tomek的鏈接
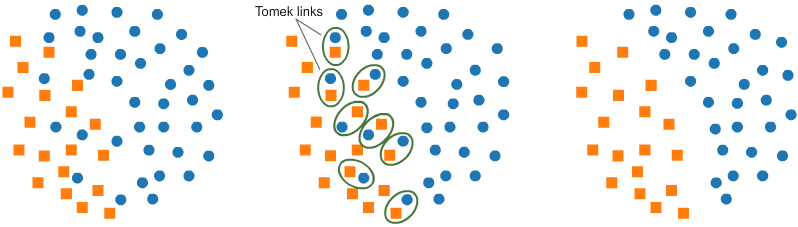
在下面的代碼中,我們將用于ratio='majority'對多數類進行重新采樣。
- # import library
- from imblearn.under_sampling import TomekLinks
- tl = RandomOverSampler(sampling_strategy='majority')
- # fit predictor and target variablex_tl, y_tl = ros.fit_resample(x, y)print('Original dataset shape', Counter(y))
- print('Resample dataset shape', Counter(y_ros))

6. Synthetic Minority Oversampling Technique (SMOTE)
該技術為合成少數過采樣技術。
SMOTE(合成少數過采樣技術)的工作原理是從少數類中隨機選取一個點并計算該點的k近鄰。合成點被添加到所選的點和它的相鄰點之間。
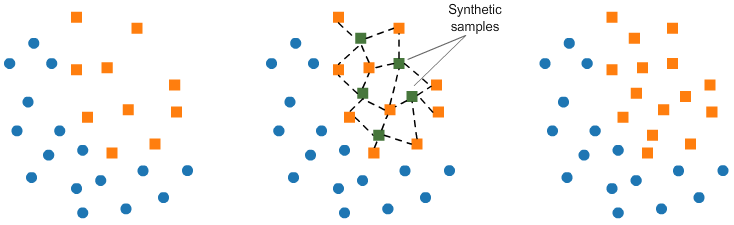
SMOTE算法通過以下四個簡單步驟工作:
- 選擇少數類作為輸入向量
- 查找其k個最近鄰(在SMOTE()函數中將k_neighbors指定為參數)
- 選擇這些鄰居中的一個,并將合成點放置在連接考慮中的點及其所選鄰居的線上的任何位置
- 重復這些步驟,直到數據平衡
- # import library
- from imblearn.over_sampling import SMOTE
- smote = SMOTE()# fit predictor and target variablex_smote, y_smote = smote.fit_resample(x, y)print('Original dataset shape', Counter(y))
- print('Resample dataset shape', Counter(y_ros))

7. NearMiss
NearMiss是欠采樣技術。與其使用距離重新采樣少數類,不如將多數類等同于少數類。
- from imblearn.under_sampling import NearMiss
- nm = NearMiss()x_nm, y_nm = nm.fit_resample(x, y)print('Original dataset shape:', Counter(y))
- print('Resample dataset shape:', Counter(y_nm))

8.更改性能指標
評估不平衡數據集時,準確性不是最佳的度量標準,因為它可能會產生誤導。
可以提供更好洞察力的指標是:
- 混淆矩陣:顯示正確預測和錯誤預測類型的表。
- 精度:真實陽性的數目除以所有陽性預測。精度也稱為正預測值。它是分類器準確性的度量。低精度表示大量誤報。
- 召回率:真實陽性的數量除以測試數據中的陽性值的數量。召回也稱為敏感度或真實陽性率。它是分類器完整性的度量。較低的召回率表示大量假陰性。
- F1:得分:準確性和召回率的加權平均值。
- ROC曲線下面積(AUROC):AUROC表示模型將觀測值與兩個類區分開來的可能性。
換句話說,如果你從每個類中隨機選擇一個觀察值,你的模型能夠正確“排序”它們的概率有多大?
9.懲罰算法(成本敏感訓練)
下一個策略是使用懲罰性學習算法,該算法會增加少數類分類錯誤的成本。
這項技術的一種流行算法是Penalized-SVM。
在訓練過程中,我們可以使用參數class_weight='balanced'來懲罰少數類的錯誤,懲罰量與代表性不足的程度成正比。
如果我們想為支持向量機算法啟用概率估計,我們還希望包含參數probability=True。
讓我們在原始不平衡數據集上使用Penalized-SVM訓練模型:
- # load library
- from sklearn.svm import SVC
- # we can add class_weight='balanced' to add panalize mistake
- svc_model = SVC(class_weight='balanced', probability=True)
- svc_model.fit(x_train, y_train)svc_predict = svc_model.predict(x_test)# check performanceprint('ROCAUC score:',roc_auc_score(y_test, svc_predict))
- print('Accuracy score:',accuracy_score(y_test, svc_predict))
- print('F1 score:',f1_score(y_test, svc_predict))

10.更改算法
盡管在每個機器學習問題中,嘗試各種算法都是一個很好的經驗法則,但是對于不平衡的數據集而言,這尤其有利。
決策樹經常在不平衡的數據上表現良好。在現代機器學習中,樹集成(隨機森林,梯度增強樹等)幾乎總是勝過單個決策樹,因此我們將直接跳到:
基于樹的算法通過學習 if / else 問題的層次結構來工作。這可以強制解決兩個類。
- # load library
- from sklearn.ensemble import RandomForestClassifier
- rfc = RandomForestClassifier()# fit the predictor and targetrfc.fit(x_train, y_train)# predictrfc_predict = rfc.predict(x_test)# check performanceprint('ROCAUC score:',roc_auc_score(y_test, rfc_predict))
- print('Accuracy score:',accuracy_score(y_test, rfc_predict))
- print('F1 score:',f1_score(y_test, rfc_predict))

欠采樣的優點和缺點
優點
- 當訓練數據集很大時,它可以通過減少訓練數據樣本的數量來幫助改善運行時間和存儲問題。
缺點
- 它可以丟棄可能有用的信息,這對于構建規則分類器可能很重要。
- 通過隨機欠采樣選擇的樣本可能是有偏差的樣本。可能導致實際測試數據集的結果不準確。
過采樣的優缺點
優點
- 與欠采樣不同,此方法不會導致信息丟失。
- 在抽樣條件下表現更佳
缺點
- 由于它復制了少數群體事件,因此增加了過度擬合的可能性。
你可以在我的GitHub存儲庫中檢查代碼的實現。
https://github.com/benai9916/Handle-imbalanced-data/tree/master
結論
總而言之,在本文中,我們已經看到了處理數據集中的類不平衡的各種技術。處理不平衡數據時,實際上有很多方法可以嘗試。希望本文對你有所幫助。